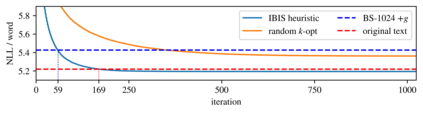
As neural language models approach human performance on NLP benchmark tasks, their advances are widely seen as evidence of an increasingly complex understanding of syntax. This view rests upon a hypothesis that has not yet been empirically tested: that word order encodes meaning essential to performing these tasks. We refute this hypothesis in many cases: in the GLUE suite and in various genres of English text, the words in a sentence or phrase can rarely be permuted to form a phrase carrying substantially different information. Our surprising result relies on inference by iterative shuffling (IBIS), a novel, efficient procedure that finds the ordering of a bag of words having the highest likelihood under a fixed language model. IBIS can use any black-box model without additional training and is superior to existing word ordering algorithms. Coalescing our findings, we discuss how shuffling inference procedures such as IBIS can benefit language modeling and constrained generation.
翻译:随着神经语言模型接近人类在NLP基准任务方面的表现,其进步被广泛视为越来越复杂的对语法理解的证据。这种观点基于一个尚未经过经验检验的假设:单词顺序编码对执行这些任务至关重要。 我们在许多情况下反驳了这一假设:在GLUE套件和英文文本的各种版本中,一句话或短语中的单词很少能够被改写成含有完全不同的信息的短语。 我们的惊人结果依赖于迭代拼接(ISIS)的推论,这是一个新颖而有效的程序,在固定语言模式下找到最有可能的一包单词的顺序。 IBIS可以使用任何黑箱模式,而无需额外的培训,并且优于现有的命令算法。我们的研究,我们讨论了像IBIS这样的拼写程序如何使语言建模和受限制的一代受益。