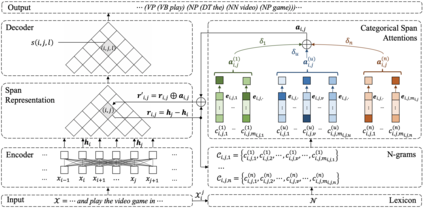
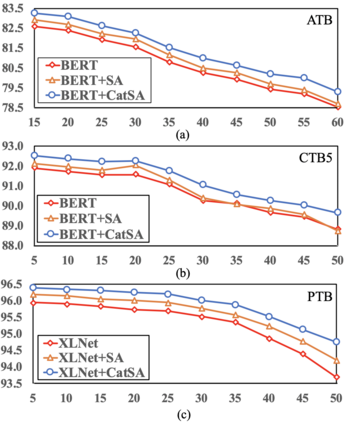
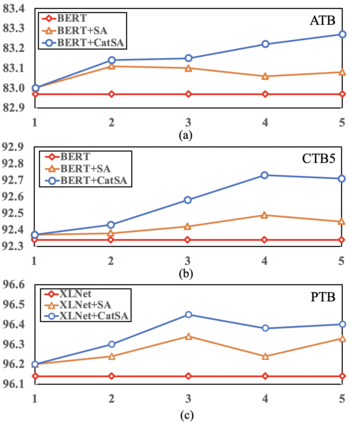
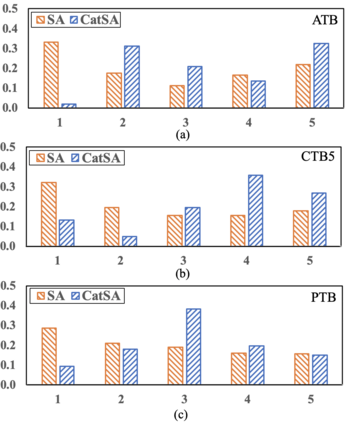
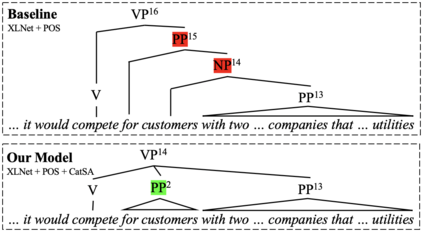
Constituency parsing is a fundamental and important task for natural language understanding, where a good representation of contextual information can help this task. N-grams, which is a conventional type of feature for contextual information, have been demonstrated to be useful in many tasks, and thus could also be beneficial for constituency parsing if they are appropriately modeled. In this paper, we propose span attention for neural chart-based constituency parsing to leverage n-gram information. Considering that current chart-based parsers with Transformer-based encoder represent spans by subtraction of the hidden states at the span boundaries, which may cause information loss especially for long spans, we incorporate n-grams into span representations by weighting them according to their contributions to the parsing process. Moreover, we propose categorical span attention to further enhance the model by weighting n-grams within different length categories, and thus benefit long-sentence parsing. Experimental results on three widely used benchmark datasets demonstrate the effectiveness of our approach in parsing Arabic, Chinese, and English, where state-of-the-art performance is obtained by our approach on all of them.
翻译:选区划分是自然语言理解的一项根本和重要的任务,在自然语言理解中,良好的背景信息代表着一个能够帮助完成这项任务的方方面面。 N克是背景信息的一种传统特征,已经证明在许多任务中有用,因此,如果以适当模式进行划分,也有利于选区划分。在本文中,我们建议对基于神经图表的选区划分给予广泛的关注,以利用n克信息。考虑到目前基于图表的基于变换器编码器的编码器代表着跨度,在跨边界减少隐藏的国家,这可能会造成信息损失,特别是长期的信息损失。我们将n克纳入跨区域表述中,根据它们对平衡过程的贡献加权。此外,我们建议明确跨度注意进一步加强模型,对不同类别中的正克加权,从而有利于长分辨。三个广泛使用的基准数据集的实验结果表明我们在阿拉伯文、中文和英文中进行区分的方法的有效性,我们在所有这些基准数据集中都取得了最先进的业绩。