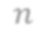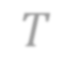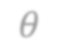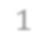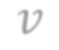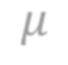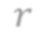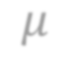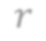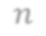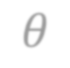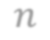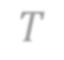In video analysis, background models have many applications such as background/foreground separation, change detection, anomaly detection, tracking, and more. However, while learning such a model in a video captured by a static camera is a fairly-solved task, in the case of a Moving-camera Background Model (MCBM), the success has been far more modest due to algorithmic and scalability challenges that arise due to the camera motion. Thus, existing MCBMs are limited in their scope and their supported camera-motion types. These hurdles also impeded the employment, in this unsupervised task, of end-to-end solutions based on deep learning (DL). Moreover, existing MCBMs usually model the background either on the domain of a typically-large panoramic image or in an online fashion. Unfortunately, the former creates several problems, including poor scalability, while the latter prevents the recognition and leveraging of cases where the camera revisits previously-seen parts of the scene. This paper proposes a new method, called DeepMCBM, that eliminates all the aforementioned issues and achieves state-of-the-art results. Concretely, first we identify the difficulties associated with joint alignment of video frames in general and in a DL setting in particular. Next, we propose a new strategy for joint alignment that lets us use a spatial transformer net with neither a regularization nor any form of specialized (and non-differentiable) initialization. Coupled with an autoencoder conditioned on unwarped robust central moments (obtained from the joint alignment), this yields an end-to-end regularization-free MCBM that supports a broad range of camera motions and scales gracefully. We demonstrate DeepMCBM's utility on a variety of videos, including ones beyond the scope of other methods. Our code is available at https://github.com/BGU-CS-VIL/DeepMCBM .
翻译:在视频分析中,背景模型有许多应用,如背景/前景分离、变化检测、异常检测、跟踪等等。然而,虽然在静态相机摄取的视频中学习这样的模型是相当解决的任务,但在移动镜头背景模型(MCBM)中,由于相机动作产生的算法和可缩缩缩性挑战,成功的程度要小得多。因此,现有的建立信任措施的范围及其支持的摄像器动作类型有限。这些障碍还阻碍了在深层MCM(DL)深层学习(DL)的基础上,在深层MCM(DL)系统之外,采用端到端的解决方案。此外,现有的MBSB通常在典型的全色图像领域或以在线方式模拟背景背景。不幸的是,前者造成一些问题,包括缩放的缩放,而后者则阻碍人们认识和利用摄像头之前所看到的部分。本文提出了一种新的方法,称为深层MBBMBMB,消除所有上述问题,实现状态-端-端解决方案,在初始(DL)结果上实现非端的状态。我们接下来的常规图像调整战略中,我们用一个共同的变校正的缩缩缩定义,用新的工具来显示一个共同变换。