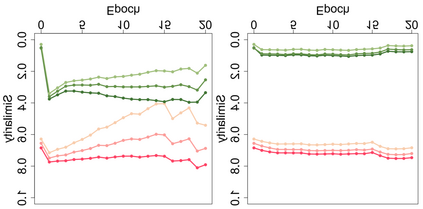
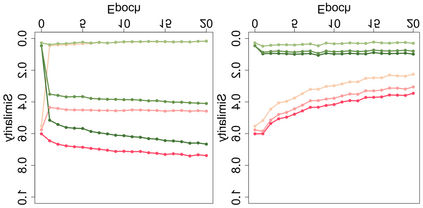
Automatic medical question summarization can significantly help the system to understand consumer health questions and retrieve correct answers. The Seq2Seq model based on maximum likelihood estimation (MLE) has been applied in this task, which faces two general problems: the model can not capture well question focus and and the traditional MLE strategy lacks the ability to understand sentence-level semantics. To alleviate these problems, we propose a novel question focus-driven contrastive learning framework (QFCL). Specially, we propose an easy and effective approach to generate hard negative samples based on the question focus, and exploit contrastive learning at both encoder and decoder to obtain better sentence level representations. On three medical benchmark datasets, our proposed model achieves new state-of-the-art results, and obtains a performance gain of 5.33, 12.85 and 3.81 points over the baseline BART model on three datasets respectively. Further human judgement and detailed analysis prove that our QFCL model learns better sentence representations with the ability to distinguish different sentence meanings, and generates high-quality summaries by capturing question focus.
翻译:以最大可能性估计为基础的Seq2Seq2Seqeq模型(MLE)已经应用于这一任务,它面临两个一般性问题:模型无法很好地抓住问题重点,传统的MLE战略缺乏理解判决等级语义的能力。为了缓解这些问题,我们提议了一个新颖的、以问题为焦点的、有对比的学习框架(QFCL)。特别是,我们提议了一种简单而有效的方法,根据问题重点生成硬性的负面样本,并利用编码器和编码器的对比性学习,以获得更好的判刑级别表现。在三个医学基准数据集中,我们提议的模型取得了新的最新结果,并在三个数据集的基线BART模型上分别取得了5.33、12.85和3.81分的性能收益。进一步的人类判断和详细分析证明,我们的QFCL模型学会了更好的句表达方式,能够区分不同的句义,通过抓住问题焦点生成高质量的摘要。