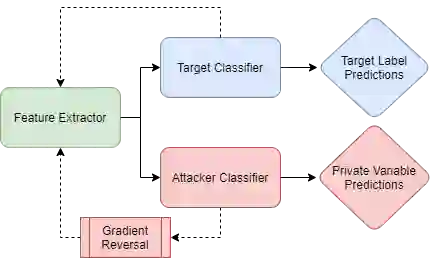
Deep learning-based language models have achieved state-of-the-art results in a number of applications including sentiment analysis, topic labelling, intent classification and others. Obtaining text representations or embeddings using these models presents the possibility of encoding personally identifiable information learned from language and context cues that may present a risk to reputation or privacy. To ameliorate these issues, we propose Context-Aware Private Embeddings (CAPE), a novel approach which preserves privacy during training of embeddings. To maintain the privacy of text representations, CAPE applies calibrated noise through differential privacy, preserving the encoded semantic links while obscuring sensitive information. In addition, CAPE employs an adversarial training regime that obscures identified private variables. Experimental results demonstrate that the proposed approach reduces private information leakage better than either single intervention.
翻译:深层次的学习语言模型在许多应用中取得了最新成果,包括情感分析、专题标签、意图分类和其他应用。使用这些模型获得文本表述或嵌入,就有可能将从语言和背景提示中获取的、可能危及名誉或隐私的可识别个人信息编码起来。为了改善这些问题,我们提议了“环境软件私人嵌入器”(CAPE),这是一种在嵌入器培训中保护隐私的新办法。为了维护文本表述的隐私,CAPE通过不同的隐私应用校准噪声,维护编码的语义链接,同时隐蔽敏感信息。此外,CAPE还采用了一种掩盖已查明的私人变量的对抗性培训制度。实验结果表明,拟议的方法比单一干预都更好地减少私人信息泄漏。