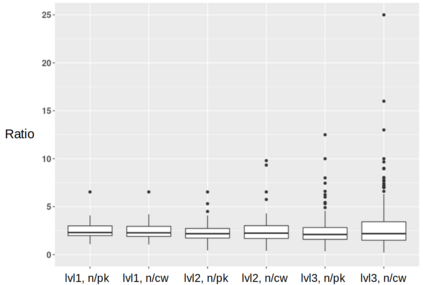
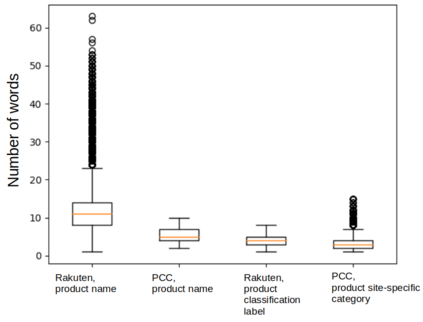
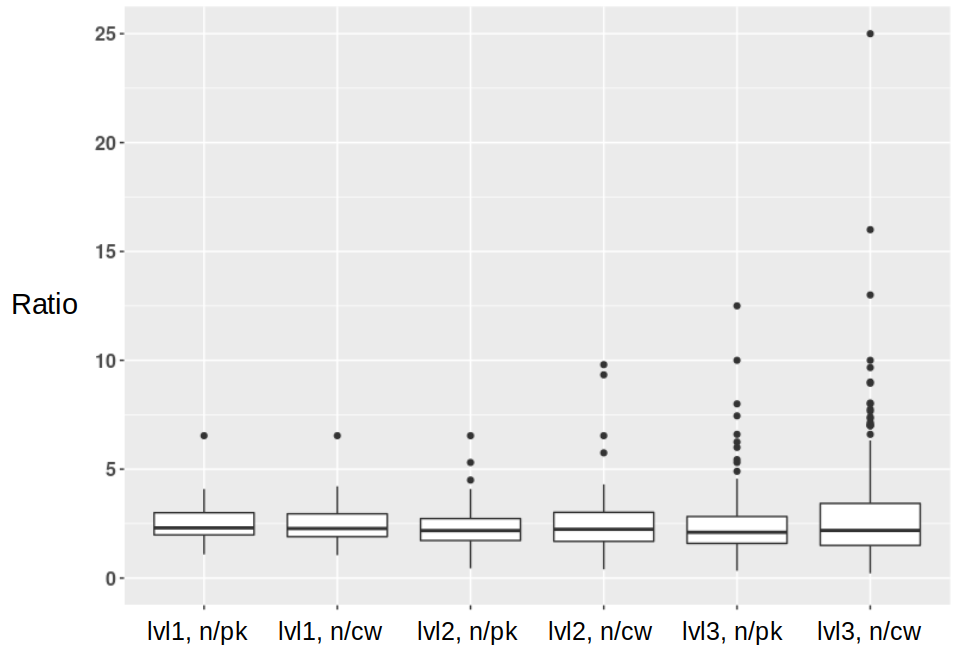
The Linked Open Data practice has led to a significant growth of structured data on the Web in the last decade. Such structured data describe real-world entities in a machine-readable way, and have created an unprecedented opportunity for research in the field of Natural Language Processing. However, there is a lack of studies on how such data can be used, for what kind of tasks, and to what extent they can be useful for these tasks. This work focuses on the e-commerce domain to explore methods of utilising such structured data to create language resources that may be used for product classification and linking. We process billions of structured data points in the form of RDF n-quads, to create multi-million words of product-related corpora that are later used in three different ways for creating of language resources: training word embedding models, continued pre-training of BERT-like language models, and training Machine Translation models that are used as a proxy to generate product-related keywords. Our evaluation on an extensive set of benchmarks shows word embeddings to be the most reliable and consistent method to improve the accuracy on both tasks (with up to 6.9 percentage points in macro-average F1 on some datasets). The other two methods however, are not as useful. Our analysis shows that this could be due to a number of reasons, including the biased domain representation in the structured data and lack of vocabulary coverage. We share our datasets and discuss how our lessons learned could be taken forward to inform future research in this direction.
翻译:在过去十年中,链接的开放数据实践导致网上结构化数据大幅增加。这种结构化数据以机器可读的方式描述真实世界实体,并创造了在自然语言处理领域进行研究的前所未有的机会。然而,对于如何使用这些数据、如何使用这些数据、开展何种任务,以及这些数据在多大程度上对这些任务有用,缺乏研究。这项工作侧重于电子商务领域,探索如何利用这种结构化数据来创造可用于产品分类和链接的语文资源。我们以机器可读的方式处理数十亿个结构化数据点,以RDF n-quds的形式,创建数百万字的与产品有关的公司,这些公司后来以三种不同方式用于创建语言资源:培训词嵌入模型、继续预先培训像BERT这样的语言模型,以及培训机器翻译模型,这些模型被用来替代产生与产品相关的关键词。我们对一套广泛基准的评估显示,将词嵌入最可靠和一致的方法是改进两项任务的准确性(在RDF n-Q-Q-Q-Q-Q-Q-Q-Q-Q-Q-Q-Q-Q-Q-Q-M-M-Q-Q-Q-Q-M-M-M-M-Q-M-M-M-M-M-M-M-M-Q-M-M-M-M-M-M-M-M-M-M-M-M-M-M-M-M-M-M-M-M-M-M-M-M-M-M-M-M-M-M-M-M-M-C-C-C-M-M-M-M-M-M-C-M-M-M-R-M-M-M-M-C-C-C-C-C-C-C-C-C-C-C-C-C-C-C-C-C-C-R-R-R-R-R-R-R-C-C-C-C-C-C-C-C-C-C-C-C-C-C-C-C-C-C-C-C-C-R-L-L-L-L-L-L-L-L-L-L-L-L-C-C-C-C-C-C-C-C-C-L