

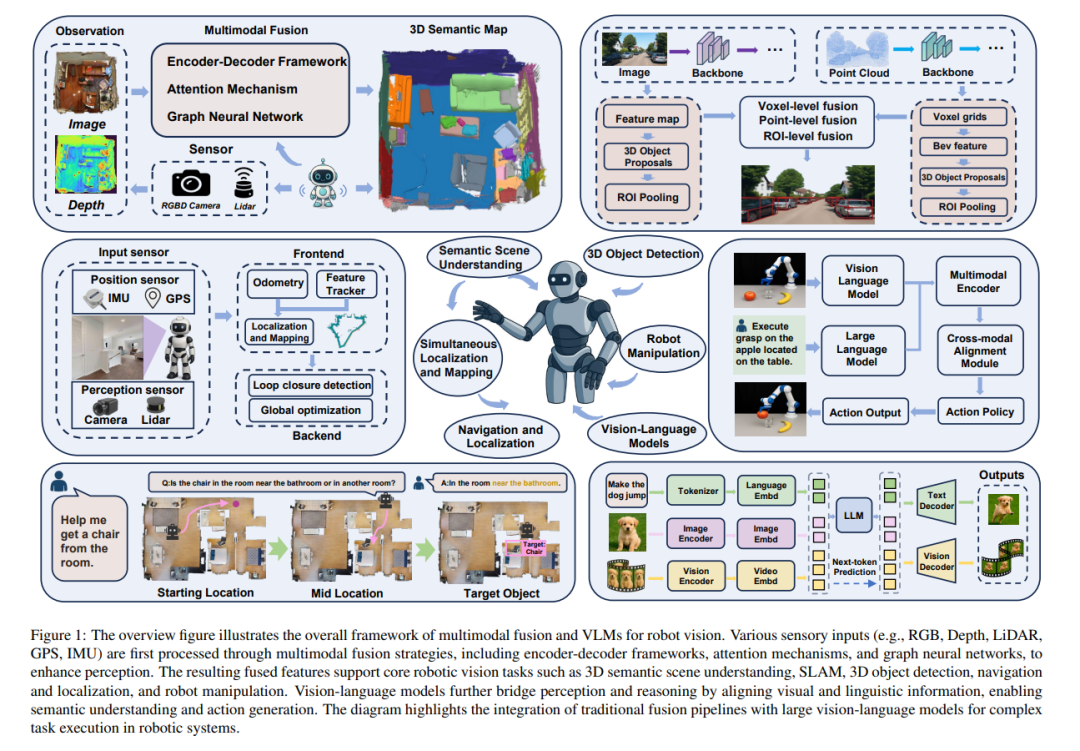
机器人视觉正持续受益于多模态融合技术与视觉-语言模型(Vision-Language Models, VLMs)的迅速发展。本文系统回顾了多模态融合技术在一系列关键机器人视觉任务中的应用,包括语义场景理解、同步定位与地图构建(SLAM)、三维目标检测、导航与定位以及机器人操作控制。 我们将基于大型语言模型(LLMs)的视觉-语言模型与传统多模态融合方法进行了对比,分析了它们在性能、适用性、限制及协同潜力等方面的优劣。与此同时,本文深入剖析了当前常用的数据集,评估其在现实机器人场景中的适用性与挑战。 我们进一步识别出该领域面临的若干关键研究难题,如跨模态对齐、高效融合策略、实时部署能力以及领域自适应问题。为推动研究发展,本文提出若干未来研究方向,包括:用于鲁棒多模态表示的自监督学习、基于Transformer的融合架构以及可扩展的多模态感知框架。 通过全面的文献回顾、系统对比分析与前瞻性探讨,本文为推动机器人视觉领域中的多模态感知与交互提供了有价值的参考。 完整论文列表可访问:https://github.com/Xiaofeng-Han-Res/MF-RV
成为VIP会员查看完整内容
相关内容
Arxiv
37+阅读 · 2023年4月19日
Arxiv
203+阅读 · 2023年4月7日
Arxiv
79+阅读 · 2023年4月4日
Arxiv
138+阅读 · 2023年3月29日

相关VIP内容
相关资讯
相关论文
Arxiv
37+阅读 · 2023年4月19日
Arxiv
203+阅读 · 2023年4月7日
Arxiv
79+阅读 · 2023年4月4日
Arxiv
138+阅读 · 2023年3月29日