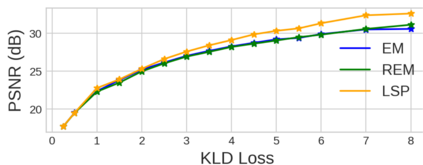
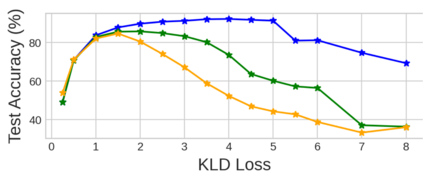
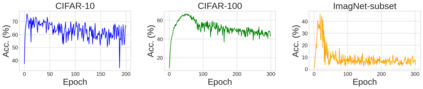
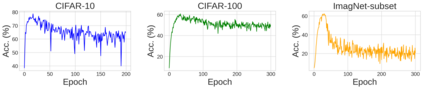
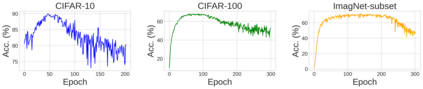
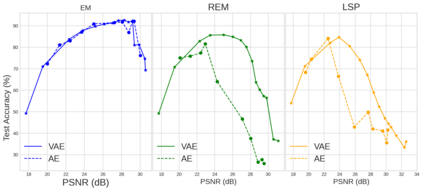
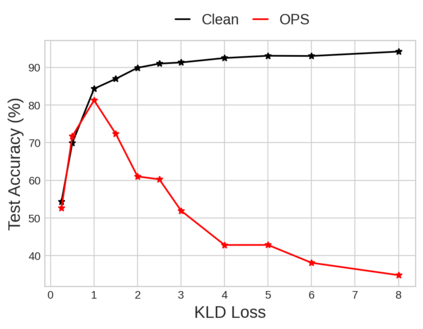
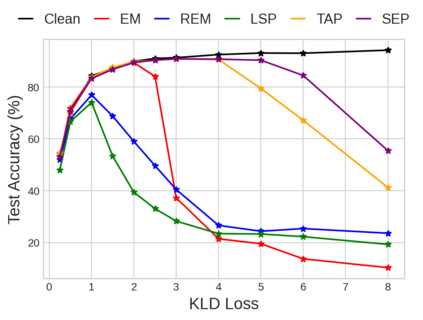
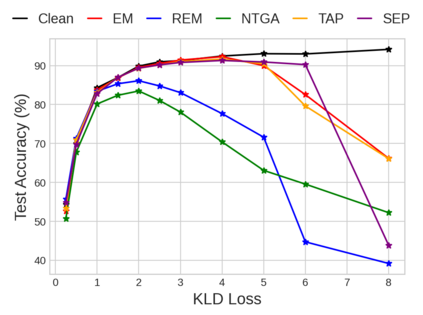
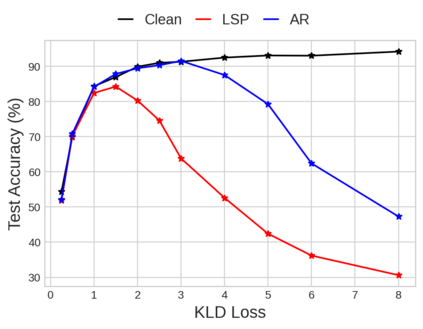
Unlearnable examples (UEs) seek to maximize testing error by making subtle modifications to training examples that are correctly labeled. Defenses against these poisoning attacks can be categorized based on whether specific interventions are adopted during training. The first approach is training-time defense, such as adversarial training, which can mitigate poisoning effects but is computationally intensive. The other approach is pre-training purification, e.g., image short squeezing, which consists of several simple compressions but often encounters challenges in dealing with various UEs. Our work provides a novel disentanglement mechanism to build an efficient pre-training purification method. Firstly, we uncover rate-constrained variational autoencoders (VAEs), demonstrating a clear tendency to suppress the perturbations in UEs. We subsequently conduct a theoretical analysis for this phenomenon. Building upon these insights, we introduce a disentangle variational autoencoder (D-VAE), capable of disentangling the perturbations with learnable class-wise embeddings. Based on this network, a two-stage purification approach is naturally developed. The first stage focuses on roughly eliminating perturbations, while the second stage produces refined, poison-free results, ensuring effectiveness and robustness across various scenarios. Extensive experiments demonstrate the remarkable performance of our method across CIFAR-10, CIFAR-100, and a 100-class ImageNet-subset. Code is available at https://github.com/yuyi-sd/D-VAE.
翻译:暂无翻译