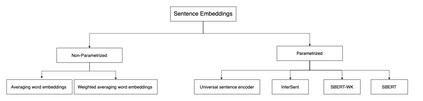
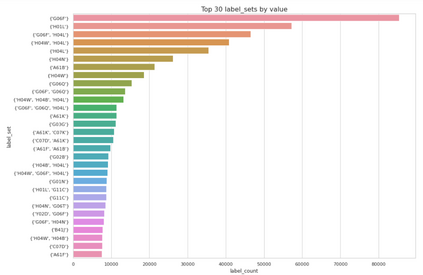
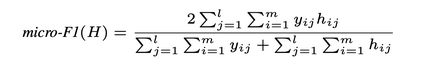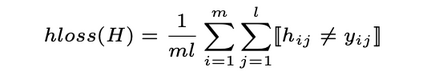Patent data is an important source of knowledge for innovation research, while the technological similarity between pairs of patents is a key enabling indicator for patent analysis. Recently researchers have been using patent vector space models based on different NLP embeddings models to calculate the technological similarity between pairs of patents to help better understand innovations, patent landscaping, technology mapping, and patent quality evaluation. More often than not, Text Embedding is a vital precursor to patent analysis tasks. A pertinent question then arises: How should we measure and evaluate the accuracy of these embeddings? To the best of our knowledge, there is no comprehensive survey that builds a clear delineation of embedding models' performance for calculating patent similarity indicators. Therefore, in this study, we provide an overview of the accuracy of these algorithms based on patent classification performance and propose a standard library and dataset for assessing the accuracy of embeddings models based on PatentSBERTa approach. In a detailed discussion, we report the performance of the top 3 algorithms at section, class, and subclass levels. The results based on the first claim of patents show that PatentSBERTa, Bert-for-patents, and TF-IDF Weighted Word Embeddings have the best accuracy for computing sentence embeddings at the subclass level. According to the first results, the performance of the models in different classes varies, which shows researchers in patent analysis can utilize the results of this study to choose the best proper model based on the specific section of patent data they used.
翻译:专利数据是创新研究知识的重要来源,而专利对等之间的技术相似性则是专利分析的主要有利指标。最近研究人员一直在使用基于不同NLP嵌入模型的专利矢量空间模型来计算专利对等技术相似性,以帮助更好地了解创新、专利景观美化、技术绘图和专利质量评估。通常情况下,文本嵌入是专利分析任务的重要先锋。随后出现一个相关的问题:我们应如何衡量和评估这些嵌入的准确性?根据我们的知识,没有全面调查能够清楚地界定用于计算专利相似性指标的嵌入模型的性能。因此,在本研究中,我们概述了基于专利分类绩效的这些算法的准确性,并提出了一个标准图书馆和数据集,用于评估基于专利SBETETRA方法的嵌入模型的准确性。在详细讨论中,我们报告了在部门、级别和次类各级的3种顶级算法的性能。根据专利索赔的首项,Bert-for-pent计算模型在计算专利相似性指标指标指标时,我们概述了这些算算法的准确性,在标准级上,我们利用了该级的精度分析中,在标准级的精度上,我们可以使用该级的精度数据,将精度的精度的精度,在E-DFFDFDF的精度的精度上,在计算结果在计算结果的精度上,在使用该级的精度上,在计算结果的精度的精度上,在SBDFBR的精度上,我们的精度分析。