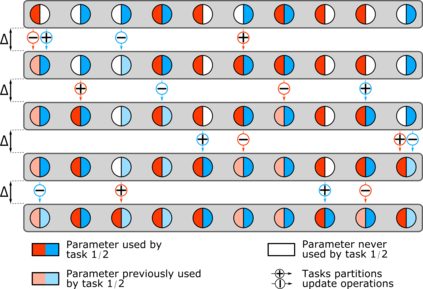
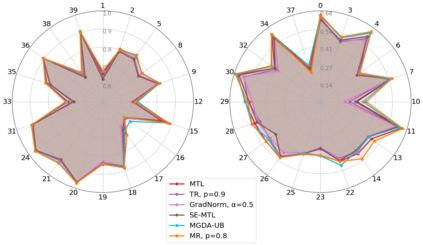
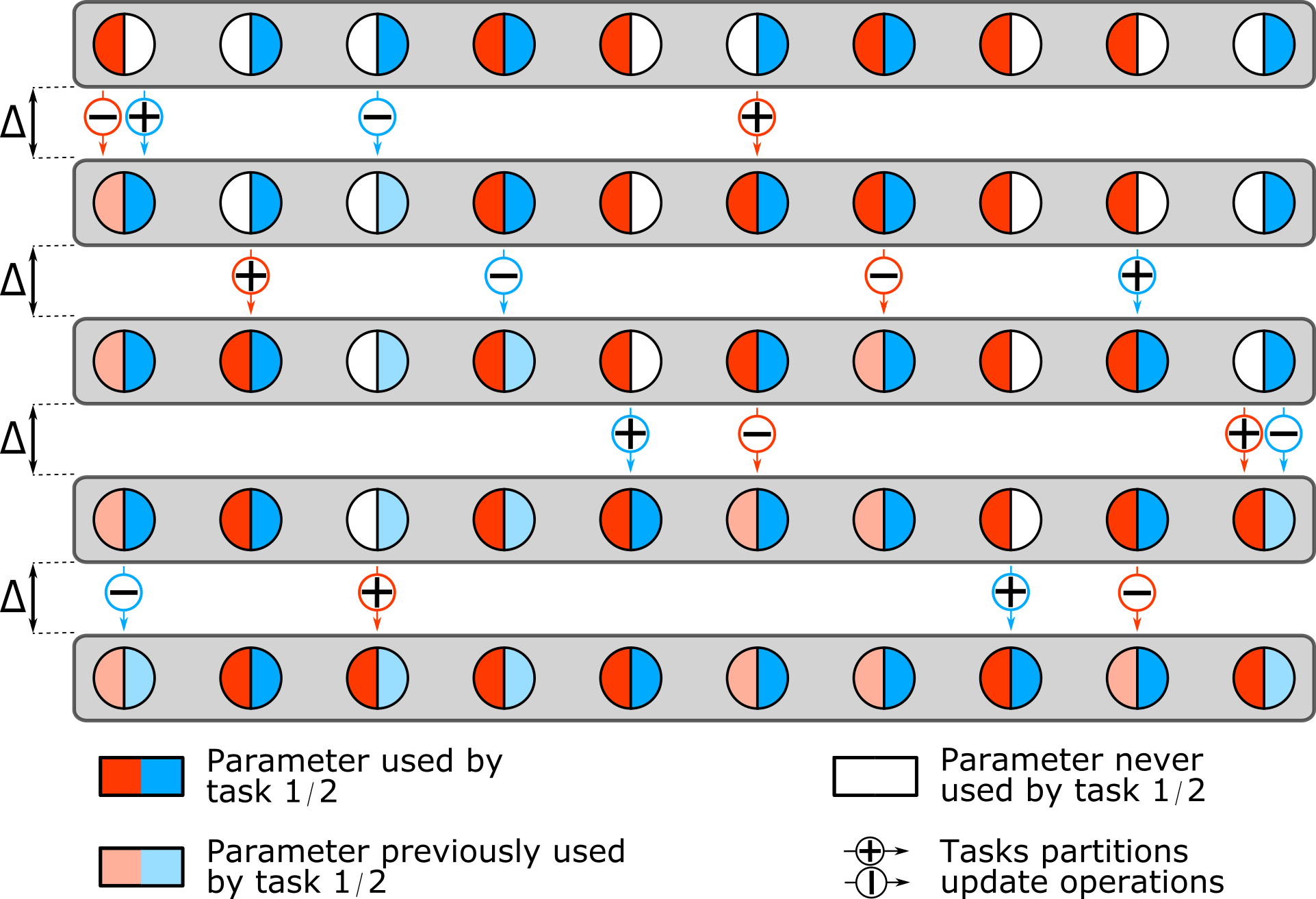
Multi-task learning has gained popularity due to the advantages it provides with respect to resource usage and performance. Nonetheless, the joint optimization of parameters with respect to multiple tasks remains an active research topic. Sub-partitioning the parameters between different tasks has proven to be an efficient way to relax the optimization constraints over the shared weights, may the partitions be disjoint or overlapping. However, one drawback of this approach is that it can weaken the inductive bias generally set up by the joint task optimization. In this work, we present a novel way to partition the parameter space without weakening the inductive bias. Specifically, we propose Maximum Roaming, a method inspired by dropout that randomly varies the parameter partitioning, while forcing them to visit as many tasks as possible at a regulated frequency, so that the network fully adapts to each update. We study the properties of our method through experiments on a variety of visual multi-task data sets. Experimental results suggest that the regularization brought by roaming has more impact on performance than usual partitioning optimization strategies. The overall method is flexible, easily applicable, provides superior regularization and consistently achieves improved performances compared to recent multi-task learning formulations.
翻译:多任务学习因其在资源使用和性能方面的优势而获得受欢迎。然而,对多种任务参数的联合优化仍然是一个积极的研究专题。不同任务之间的分层参数已证明是放松共享重量的优化限制的有效方法,但分割区可能会脱节或重叠。但这种方法的一个缺点是,它可能会削弱联合任务优化通常设置的感性偏差。在这项工作中,我们提出了一个在不削弱感性偏差的情况下分割参数空间的新办法。具体地说,我们提议了最大旋转法,这是由辍学引起的一种方法,随机地改变参数分隔,同时迫使它们按规定频率访问尽可能多的任务,以便网络能够充分适应每一次更新。我们通过对各种视觉多任务数据集的实验研究我们的方法的特性。实验结果表明,漫游带来的调整对性能的影响大于通常的偏差优化战略。总体方法灵活、容易适用、提供高级规范,并持续实现与最近的多任务学习设计相比的改进性能。