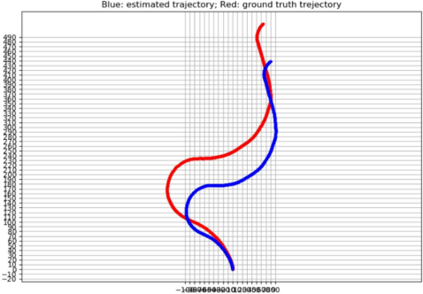
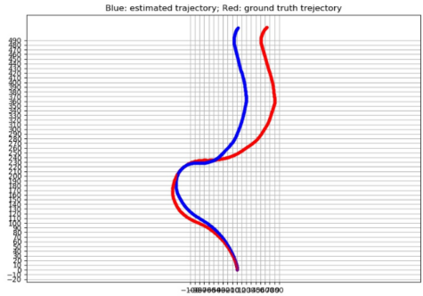
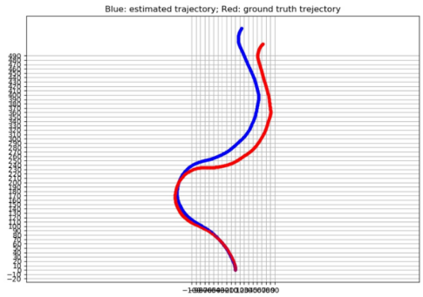
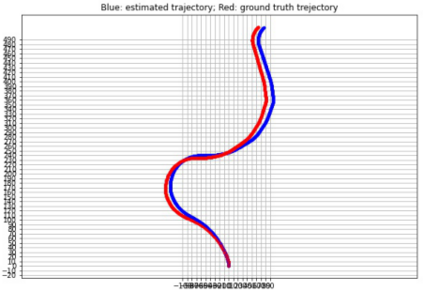
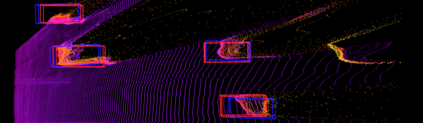
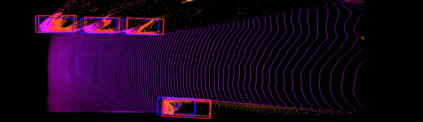
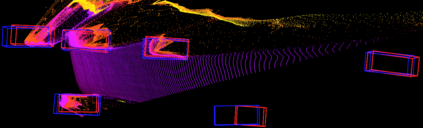
Mapping and 3D detection are two major issues in vision-based robotics, and self-driving. While previous works only focus on each task separately, we present an innovative and efficient multi-task deep learning framework (SM3D) for Simultaneous Mapping and 3D Detection by bridging the gap with robust depth estimation and "Pseudo-LiDAR" point cloud for the first time. The Mapping module takes consecutive monocular frames to generate depth and pose estimation. In 3D Detection module, the depth estimation is projected into 3D space to generate "Pseudo-LiDAR" point cloud, where LiDAR-based 3D detector can be leveraged on point cloud for vehicular 3D detection and localization. By end-to-end training of both modules, the proposed mapping and 3D detection method outperforms the state-of-the-art baseline by 10.0% and 13.2% in accuracy, respectively. While achieving better accuracy, our monocular multi-task SM3D is more than 2 times faster than pure stereo 3D detector, and 18.3% faster than using two modules separately.
翻译:映射和 3D 探测是基于视觉的机器人和自我驱动的两个主要问题。 虽然先前的工程只分别侧重于每项任务, 但我们展示了一个创新的、高效的多任务深层学习框架( SM3D ), 用于同步绘图和 3D 探测, 首次通过强力深度估计和“ 普塞多- LiDAR” 点云缩小差距。 映射模块使用连续的单望远镜框架来产生深度并作出估计。 在 3D 探测模块中, 深度估计将投向 3D 空间, 以生成“ 普塞多- LiDAR ” 点云, 在那里, 3D 基 3D 探测器可以在点云上被利用, 用于3D 3D 探测和 本地化。 通过对两个模块的端对端培训, 拟议的映射和 3D 探测方法分别以10.0% 和 13.2% 的精确度取代了状态基线。 在达到更精确度时, 我们的单项多任务SM3D 3D 探测器比纯粹3D 探测器快2倍以上, 和18.3% 。