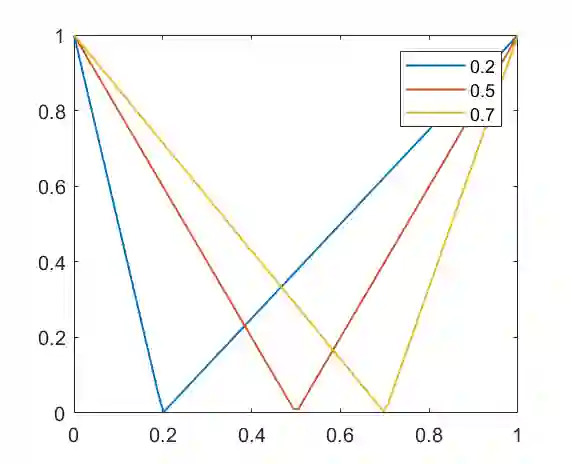
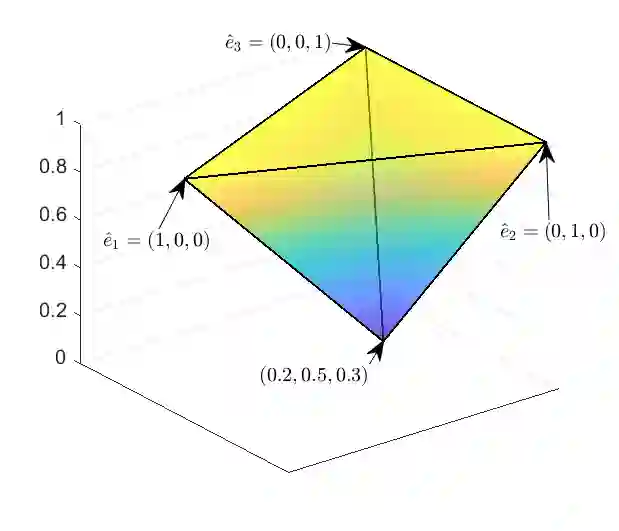
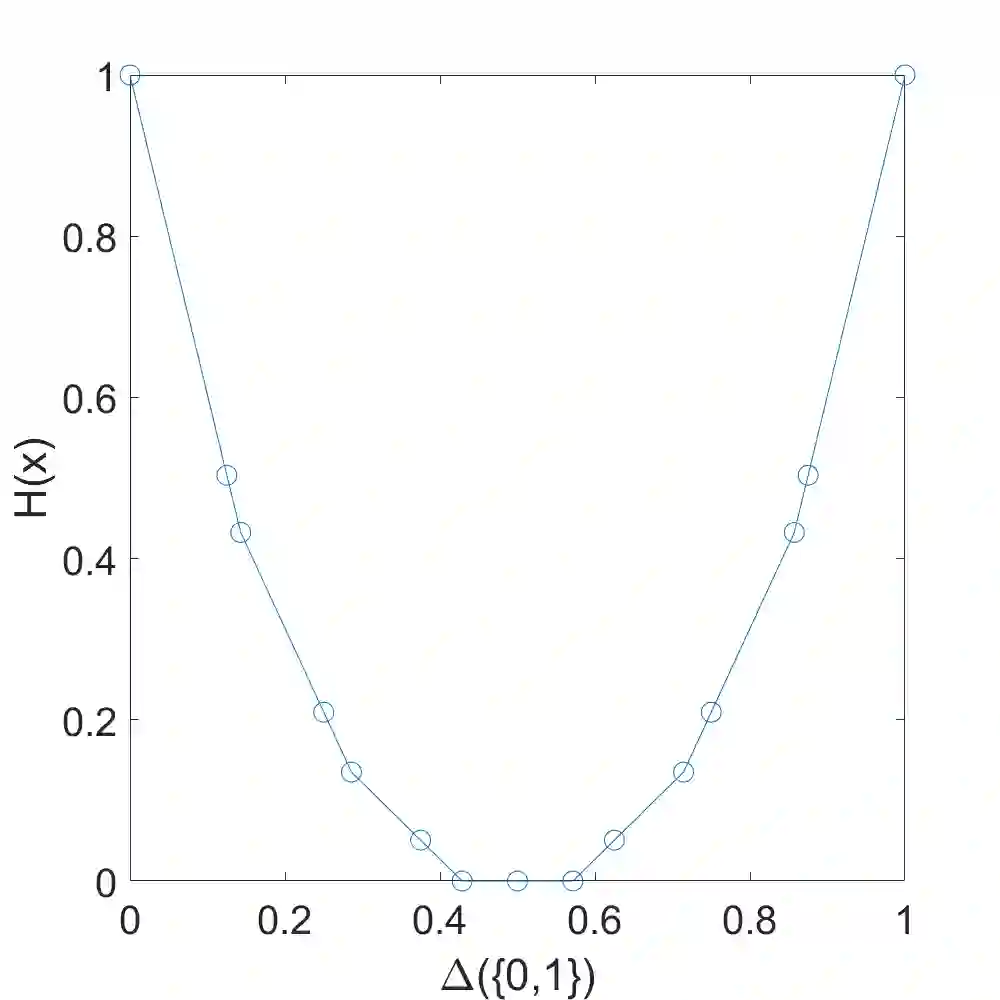
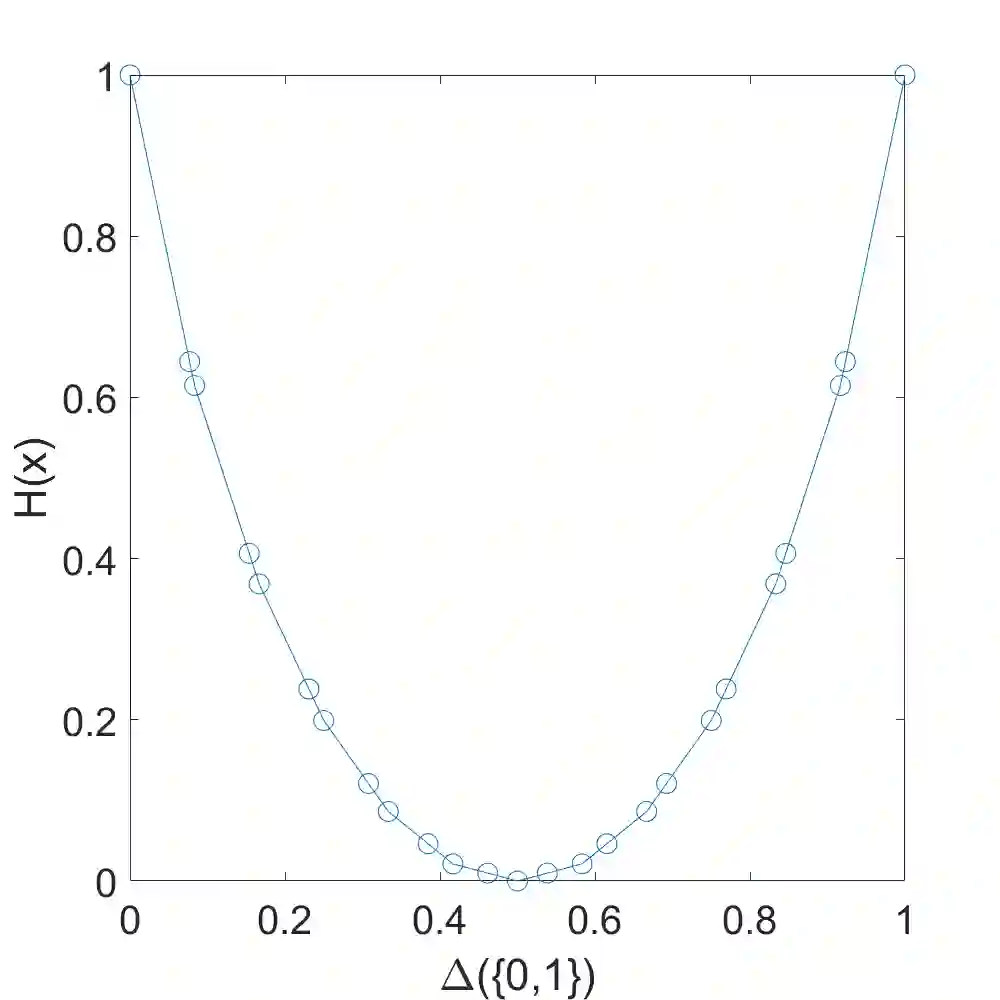
This paper introduces an optimization problem for proper scoring rule design. Consider a principal who wants to collect an agent's prediction about an unknown state. The agent can either report his prior prediction or access a costly signal and report the posterior prediction. Given a collection of possible distributions containing the agent's posterior prediction distribution, the principal's objective is to design a bounded scoring rule to maximize the agent's worst-case payoff increment between reporting his posterior prediction and reporting his prior prediction. We study two settings of such optimization for proper scoring rules: static and asymptotic settings. In the static setting, where the agent can access one signal, we propose an efficient algorithm to compute an optimal scoring rule when the collection of distributions is finite. The agent can adaptively and indefinitely refine his prediction in the asymptotic setting. We first consider a sequence of collections of posterior distributions with vanishing covariance, which emulates general estimators with large samples, and show the optimality of the quadratic scoring rule. Then, when the agent's posterior distribution is a Beta-Bernoulli process, we find that the log scoring rule is optimal. We also prove the optimality of the log scoring rule over a smaller set of functions for categorical distributions with Dirichlet priors.
翻译:本文引入了适当的评分规则设计的最优化问题 。 考虑一个想收集代理商对未知状态的预测的负责人。 代理商可以报告其先前的预测或者获取昂贵的信号, 并报告后方预测 。 考虑到可能包含代理商后部预测分布的分布的集合, 委托人的目标是设计一个捆绑的评分规则, 在报告其后方预测和报告其先前的预测之间最大限度地增加代理商最坏的加薪。 我们研究两种优化的设置, 正确的评分规则: 静态和消瘦的设置。 在静态设置中, 代理商可以访问一个信号, 我们建议一种高效的算法, 以计算最佳的评分规则在分配有限的情况下, 计算最佳的评分规则。 代理商可以适应性地和无限期地改进其在淡化环境中的预测 。 我们首先考虑一个收藏远端分配后方最坏的评分数序列, 与大样本的一般估相比, 并显示复方评分规则的最佳性。 然后, 当代理商的后方分配是最佳的比喻规则的比重度, 之前的正标的比正值进程。