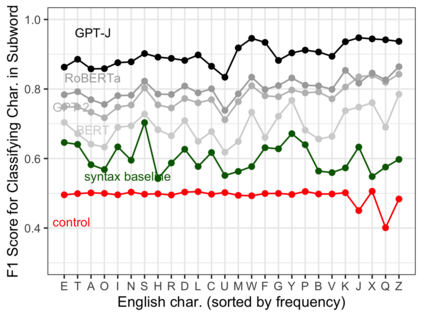
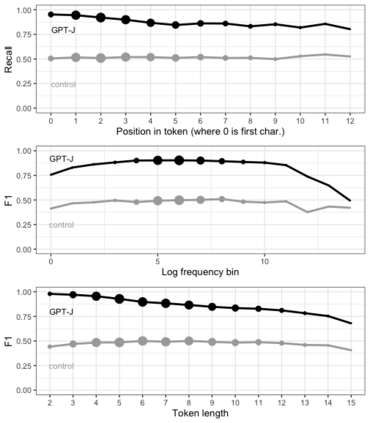
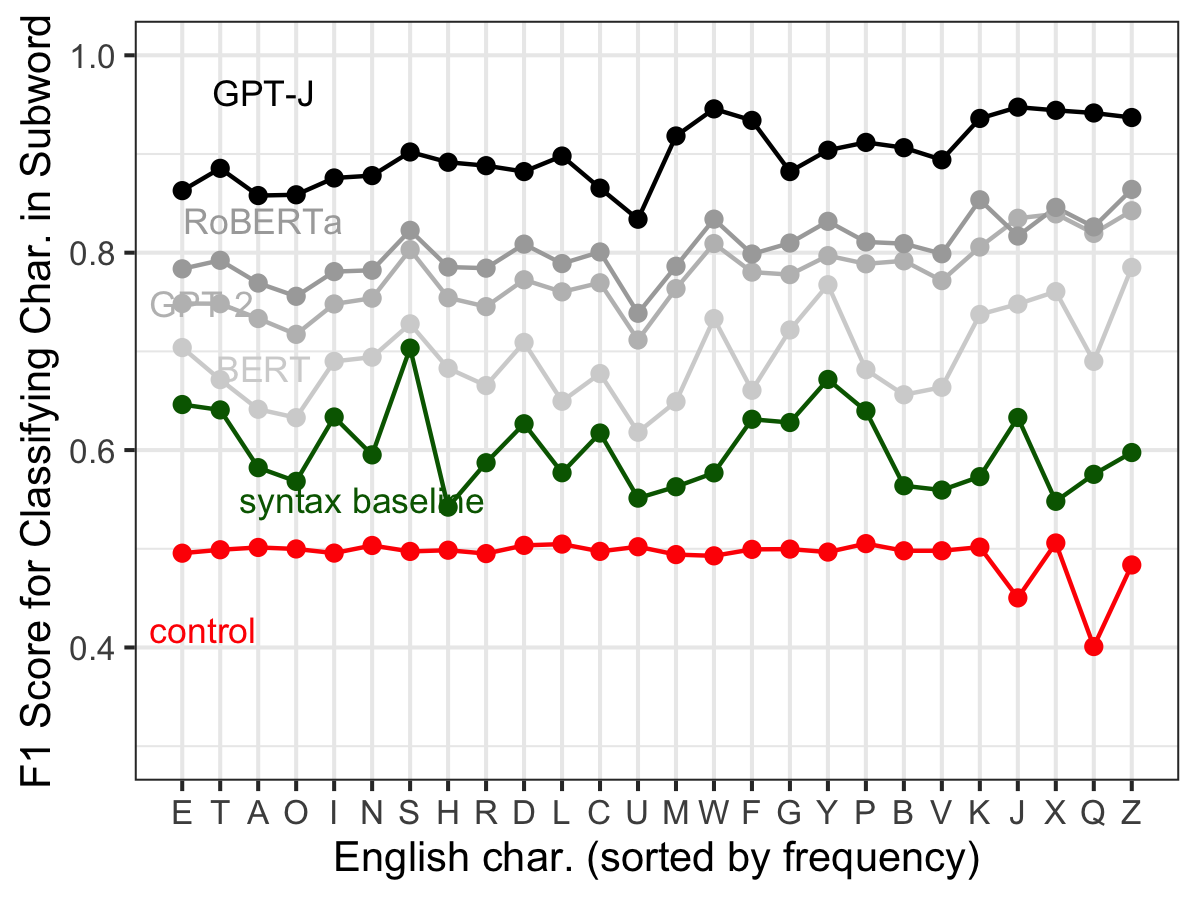
Pre-trained language models (PLMs) that use subword tokenization schemes can succeed at a variety of language tasks that require character-level information, despite lacking explicit access to the character composition of tokens. Here, studying a range of models (e.g., GPT- J, BERT, RoBERTa, GloVe), we probe what word pieces encode about character-level information by training classifiers to predict the presence or absence of a particular alphabetical character in a token, based on its embedding (e.g., probing whether the model embedding for "cat" encodes that it contains the character "a"). We find that these models robustly encode character-level information and, in general, larger models perform better at the task. We show that these results generalize to characters from non-Latin alphabets (Arabic, Devanagari, and Cyrillic). Then, through a series of experiments and analyses, we investigate the mechanisms through which PLMs acquire English-language character information during training and argue that this knowledge is acquired through multiple phenomena, including a systematic relationship between particular characters and particular parts of speech, as well as natural variability in the tokenization of related strings.
翻译:使用子词符号化办法的经过事先训练的语言模型(PLM)在各种语言任务中可以取得成功,这些语言任务需要品格级信息,尽管缺乏明确获取象征品的品格组成。在这里,我们研究一系列模型(例如,GPT-J、BERT、ROBERTA、GloVe),我们通过培训分类人员,根据嵌入方式(例如,检验是否嵌入包含“a”特性的“Cat”编码的模型),可以成功完成各种需要品格级信息的语文任务。我们发现,这些模型强有力地编码了字符级信息,总体而言,较大的模型在执行任务时表现更好。我们表明,这些结果概括了非拉丁字母(阿拉伯文、德瓦纳加里和西里尔利奇)的字符。 然后,通过一系列试验和分析,我们调查PLMs在培训期间获取英语特征信息的机制,并论证这种知识是通过多种现象获得的,包括特定字符和特定语言部分之间的系统关系,以及象征质化的自然变异性。