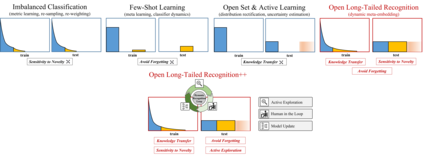
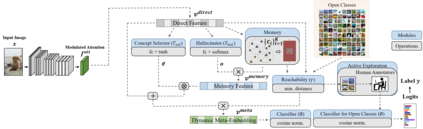
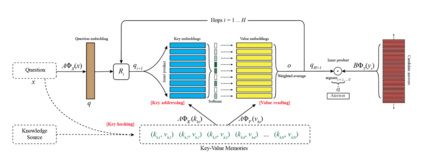
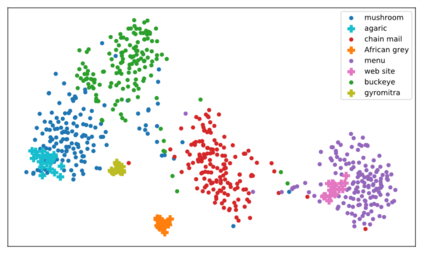
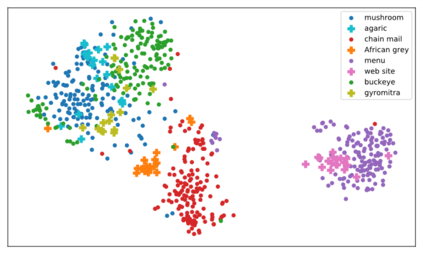
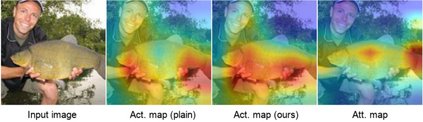
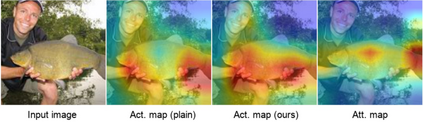
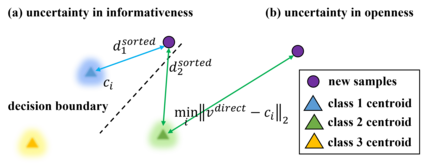
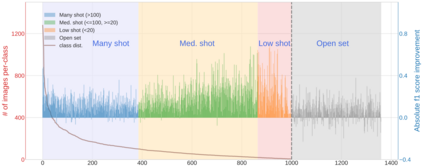
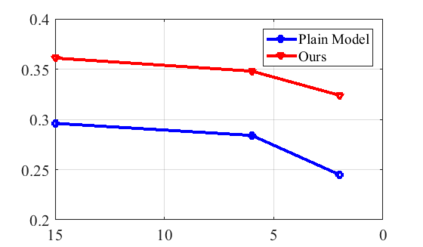
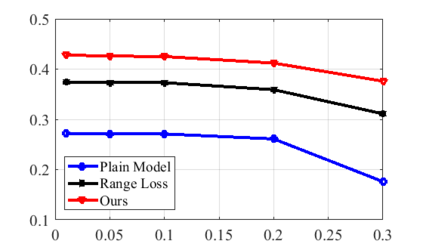
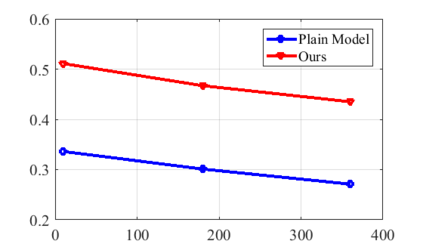
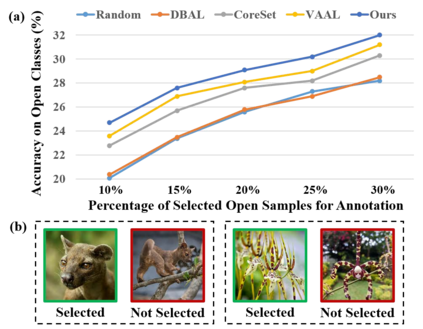
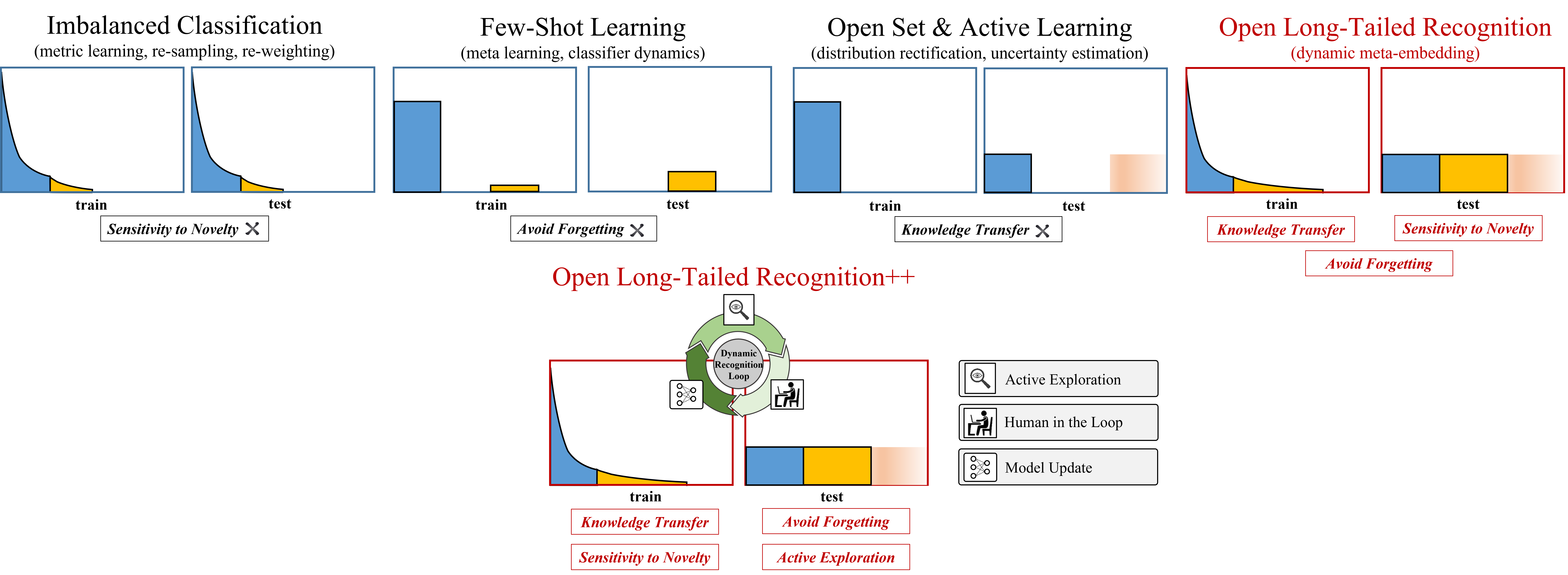
Real world data often exhibits a long-tailed and open-ended (with unseen classes) distribution. A practical recognition system must balance between majority (head) and minority (tail) classes, generalize across the distribution, and acknowledge novelty upon the instances of unseen classes (open classes). We define Open Long-Tailed Recognition++ (OLTR++) as learning from such naturally distributed data and optimizing for the classification accuracy over a balanced test set which includes both known and open classes. OLTR++ handles imbalanced classification, few-shot learning, open-set recognition, and active learning in one integrated algorithm, whereas existing classification approaches often focus only on one or two aspects and deliver poorly over the entire spectrum. The key challenges are: 1) how to share visual knowledge between head and tail classes, 2) how to reduce confusion between tail and open classes, and 3) how to actively explore open classes with learned knowledge. Our algorithm, OLTR++, maps images to a feature space such that visual concepts can relate to each other through a memory association mechanism and a learned metric (dynamic meta-embedding) that both respects the closed world classification of seen classes and acknowledges the novelty of open classes. Additionally, we propose an active learning scheme based on visual memory, which learns to recognize open classes in a data-efficient manner for future expansions. On three large-scale open long-tailed datasets we curated from ImageNet (object-centric), Places (scene-centric), and MS1M (face-centric) data, as well as three standard benchmarks (CIFAR-10-LT, CIFAR-100-LT, and iNaturalist-18), our approach, as a unified framework, consistently demonstrates competitive performance. Notably, our approach also shows strong potential for the active exploration of open classes and the fairness analysis of minority groups.
翻译:现实世界数据往往呈现出一个长期和开放的(隐形类)分布。一个实用的识别系统必须平衡多数类(头类)和少数类(尾类)之间的平衡,在整个分布中进行普及,并承认对隐形类(开放类)的新颖性。我们定义了开放的长途识别+(OLTR++),从这种自然分布的数据中学习,并优化包括已知和开放类在内的均衡测试组的分类准确性。 OLTR++ 处理不平衡的分类、 少见学习、 公开的识别和在一个综合算法中积极学习,而现有的分类方法往往只关注一个或两个方面,并且在整个频谱中提供差。 关键的挑战是:(1) 如何在头类和尾类(开放类)之间分享视觉知识,2 如何减少尾端和开放类之间的混淆,3 如何积极探索开放类。 我们的算法、 OLTR++、 将图像映射到一个特征空间, 视觉概念可以通过一个公开的组合(直径方法、 动态的代代代谢框架) 既尊重封闭世界分类,又直观的分类,又持续地学习一个直观的直观的直径级数据。