
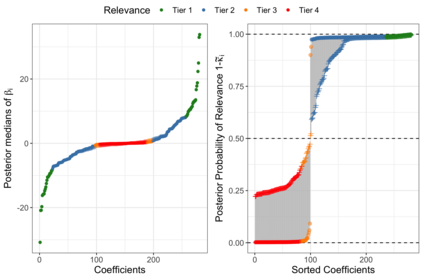
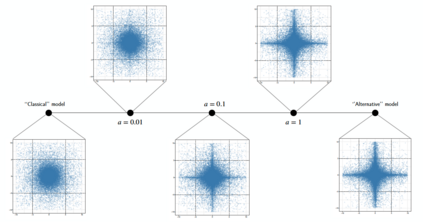
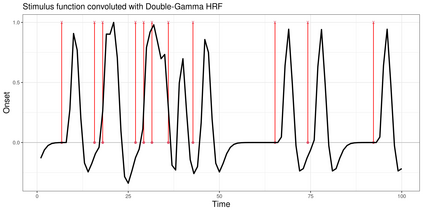
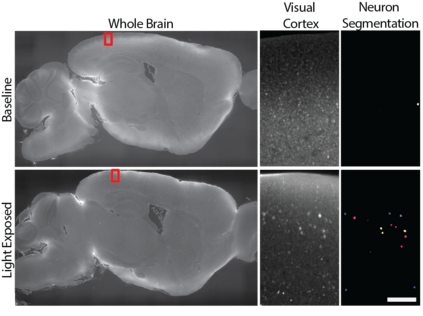
Finding parsimonious models through variable selection is a fundamental problem in many areas of statistical inference. Here, we focus on Bayesian regression models, where variable selection can be implemented through a regularizing prior imposed on the distribution of the regression coefficients. In the Bayesian literature, there are two main types of priors used to accomplish this goal: the spike-and-slab and the continuous scale mixtures of Gaussians. The former is a discrete mixture of two distributions characterized by low and high variance. In the latter, a continuous prior is elicited on the scale of a zero-mean Gaussian distribution. In contrast to these existing methods, we propose a new class of priors based on discrete mixture of continuous scale mixtures providing a more general framework for Bayesian variable selection. To this end, we substitute the observation-specific local shrinkage parameters (typical of continuous mixtures) with mixture component shrinkage parameters. Our approach drastically reduces the number of parameters needed and allows sharing information across the coefficients, improving the shrinkage effect. By using half-Cauchy distributions, this approach leads to a cluster-shrinkage version of the Horseshoe prior. We present the properties of our model and showcase its estimation and prediction performance in a simulation study. We then recast the model in a multiple hypothesis testing framework and apply it to a neurological dataset obtained using a novel whole-brain imaging technique.
翻译:通过变量选择寻找相似的模型是统计推断的许多领域的一个根本问题。 在这里, 我们侧重于贝叶西亚回归模型, 通过对回归系数的分布进行常规化, 可以通过对回归系数的分布进行变量选择。 在巴伊西亚文献中, 用于实现这一目标的有两大类前科: 悬浮和悬浮, 以及高斯人的连续比例混合。 前者是两种分布的分解混合, 其特点是低差异和高度差异。 在后者中, 一个连续的先导是零平均值的高斯分布尺度。 与这些现有方法不同, 我们提出一个新的前导类别, 以连续比例混合物混合物的离散混合物组合为基础, 为巴伊西亚变量的选择提供一个更一般的框架。 为此, 我们用混合成分组合和连续混合物的局部缩放参数替代了特定的观测本地缩放参数( 典型的混合物) 。 我们的方法极大地减少了所需参数的数量, 并允许在各种系数之间共享信息, 改进了缩放效果。 通过使用半敏感度分布, 这种方法导致一种新的前期模型, 我们用当前对马质的模型进行分组和多级模型的预估测算。




相关内容

Source: Apple - iOS 8

