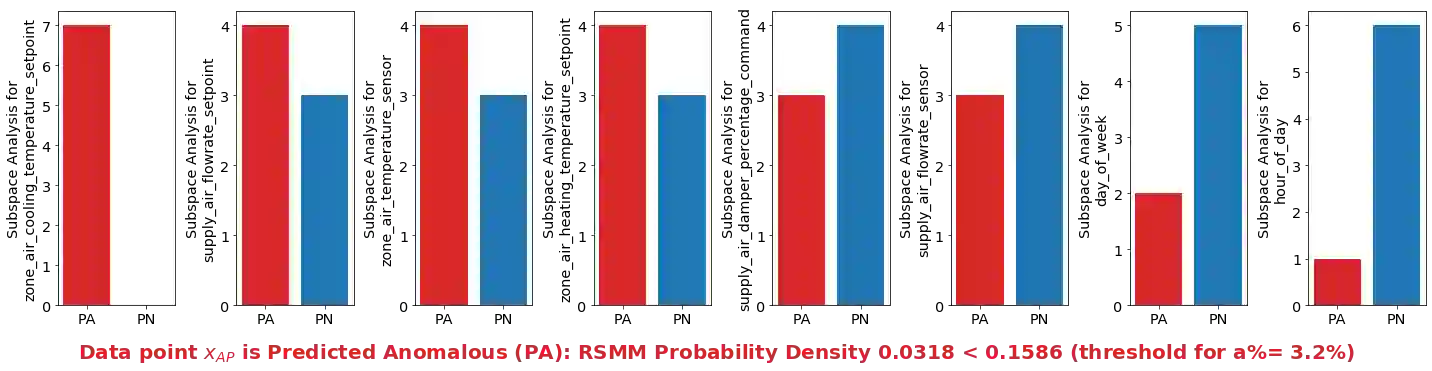
We present a new subspace-based method to construct probabilistic models for high-dimensional data and highlight its use in anomaly detection. The approach is based on a statistical estimation of probability density using densities of random subspaces combined with geometric averaging. In selecting random subspaces, equal representation of each attribute is used to ensure correct statistical limits. Gaussian mixture models (GMMs) are used to create the probability densities for each subspace with techniques included to mitigate singularities allowing for the ability to handle both numerical and categorial attributes. The number of components for each GMM is determined automatically through Bayesian information criterion to prevent overfitting. The proposed algorithm attains competitive AUC scores compared with prominent algorithms against benchmark anomaly detection datasets with the added benefits of being simple, scalable, and interpretable.
翻译:我们提出了一个新的子空间基方法,用于构建高维数据的概率模型,并突出其在异常探测中的使用。该方法基于利用随机子空间密度与平均几何等相加的随机子空间密度对概率密度的统计估计。在选择随机子空间时,每个属性的同等代表性用于确保正确的统计限制。高斯混合模型(GMMS)用于为每个子空间创造概率密度,包括各种技术,以降低特性,从而能够处理数字和分类属性。每个GMM的组件数量通过巴伊西亚信息标准自动确定,以防止过度匹配。提议的算法与显著的异常探测数据集相比,具有竞争性的ACU分数,而主要算法则具有简单、可缩放和可解释的附加效益。