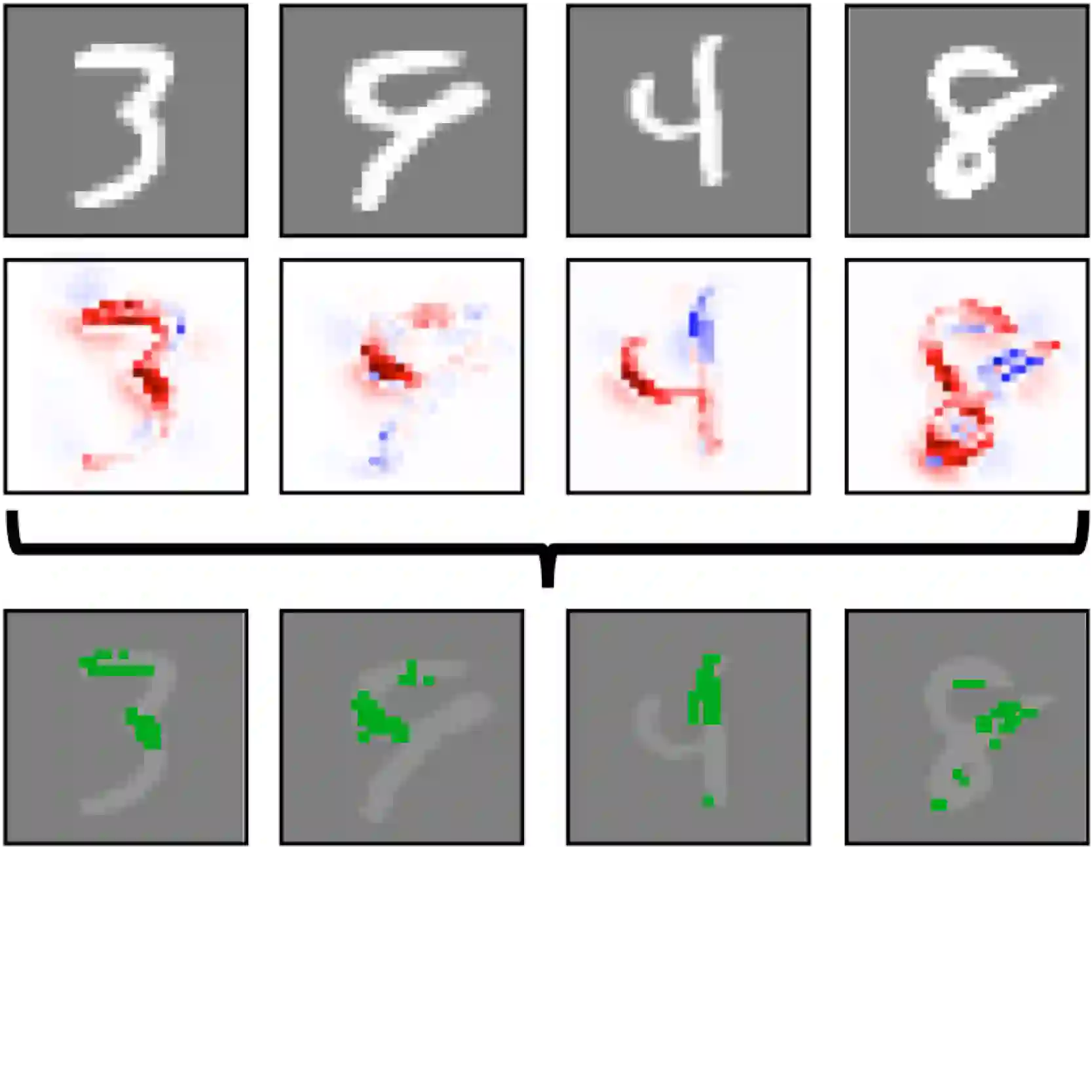
We show that utilizing attribution maps for training neural networks can improve regularization of models and thus increase performance. Regularization is key in deep learning, especially when training complex models on relatively small datasets. In order to understand inner workings of neural networks, attribution methods such as Layer-wise Relevance Propagation (LRP) have been extensively studied, particularly for interpreting the relevance of input features. We introduce Challenger, a module that leverages the explainable power of attribution maps in order to manipulate particularly relevant input patterns. Therefore, exposing and subsequently resolving regions of ambiguity towards separating classes on the ground-truth data manifold, an issue that arises particularly when training models on rather small datasets. Our Challenger module increases model performance through building more diverse filters within the network and can be applied to any input data domain. We demonstrate that our approach results in substantially better classification as well as calibration performance on datasets with only a few samples up to datasets with thousands of samples. In particular, we show that our generic domain-independent approach yields state-of-the-art results in vision, natural language processing and on time series tasks.
翻译:我们显示,利用归属图培训神经网络可以改善模型的正规化,从而提高性能。正规化是深层次学习的关键,特别是在培训相对小的数据集的复杂模型时。为了理解神经网络的内部功能,已经广泛研究了诸如图层与相关性促进(LRP)等属性方法,特别是为了解释输入特征的相关性。我们引入了挑战者模块,该模块利用归属图的可解释能力来操纵特别相关的输入模式。因此,暴露并随后解决了在地面真相数据中分级的模棱两可区域,这个问题在相当小的数据集培训模型中特别出现。我们的挑战者模块通过在网络内建立更多样化的过滤器来提高模型性能,并可用于任何输入数据领域。我们证明,我们的方法可以大大改进对数据集的分类以及校准性能,只有少数几个样本可以使用数千个样本的数据集。特别是,我们展示的通用域独立方法在视觉、自然语言处理和时间序列任务中产生最新结果。