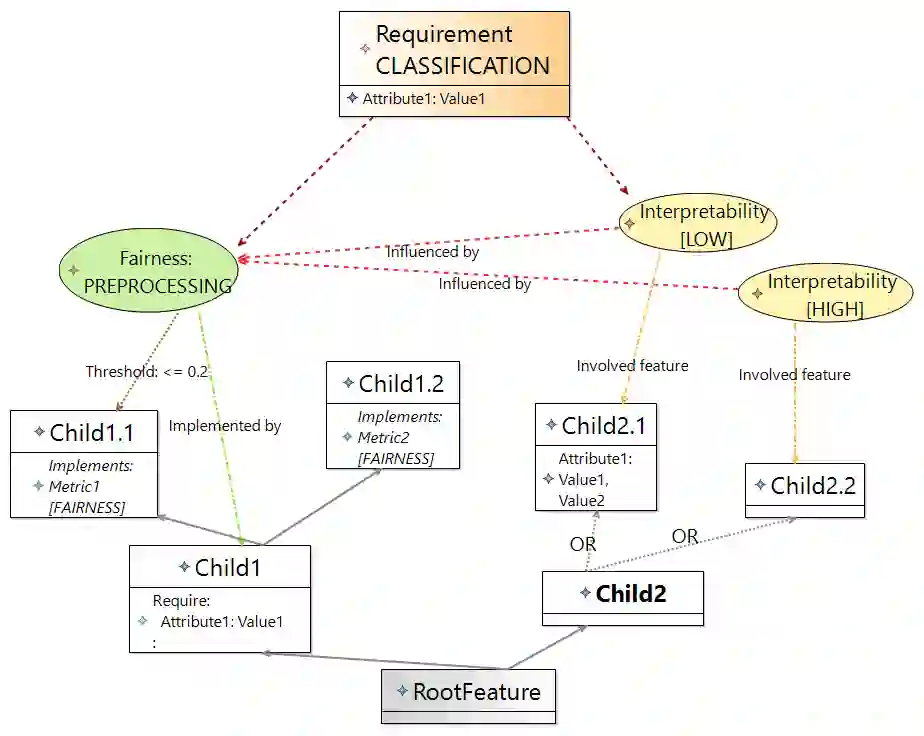
The recently increased complexity of Machine Learning (ML) methods, led to the necessity to lighten both the research and industry development processes. ML pipelines have become an essential tool for experts of many domains, data scientists and researchers, allowing them to easily put together several ML models to cover the full analytic process starting from raw datasets. Over the years, several solutions have been proposed to automate the building of ML pipelines, most of them focused on semantic aspects and characteristics of the input dataset. However, an approach taking into account the new quality concerns needed by ML systems (like fairness, interpretability, privacy, etc.) is still missing. In this paper, we first identify, from the literature, key quality attributes of ML systems. Further, we propose a new engineering approach for quality ML pipeline by properly extending the Feature Models meta-model. The presented approach allows to model ML pipelines, their quality requirements (on the whole pipeline and on single phases), and quality characteristics of algorithms used to implement each pipeline phase. Finally, we demonstrate the expressiveness of our model considering the classification problem.
翻译:最近机器学习(ML)方法日益复杂,因此有必要减轻研究和工业发展过程。ML管道已成为许多领域专家、数据科学家和研究人员的基本工具,使他们可以很容易地将若干ML模型组合起来,以涵盖从原始数据集开始的全面分析过程。几年来,提出了若干解决办法,使ML管道的建设自动化,其中多数侧重于输入数据集的语义方面和特征。然而,考虑到ML系统所需的新的质量问题(如公平性、可解释性、隐私等)的方法仍然缺失。在本文件中,我们首先从文献中找出ML系统的关键质量属性。此外,我们提出一个新的工程方法,通过适当扩展功能模型的元模型,使质量ML管道的建设自动化,其质量要求(整个管道和单一阶段),以及用于执行每个管道阶段的算法的质量特点。最后,我们展示了考虑分类问题的模型的清晰性。