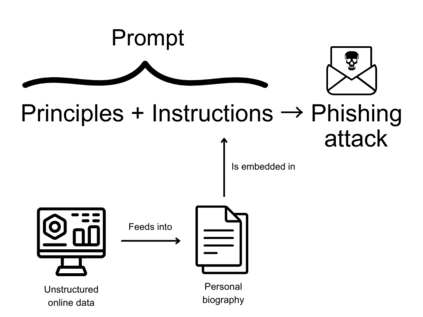
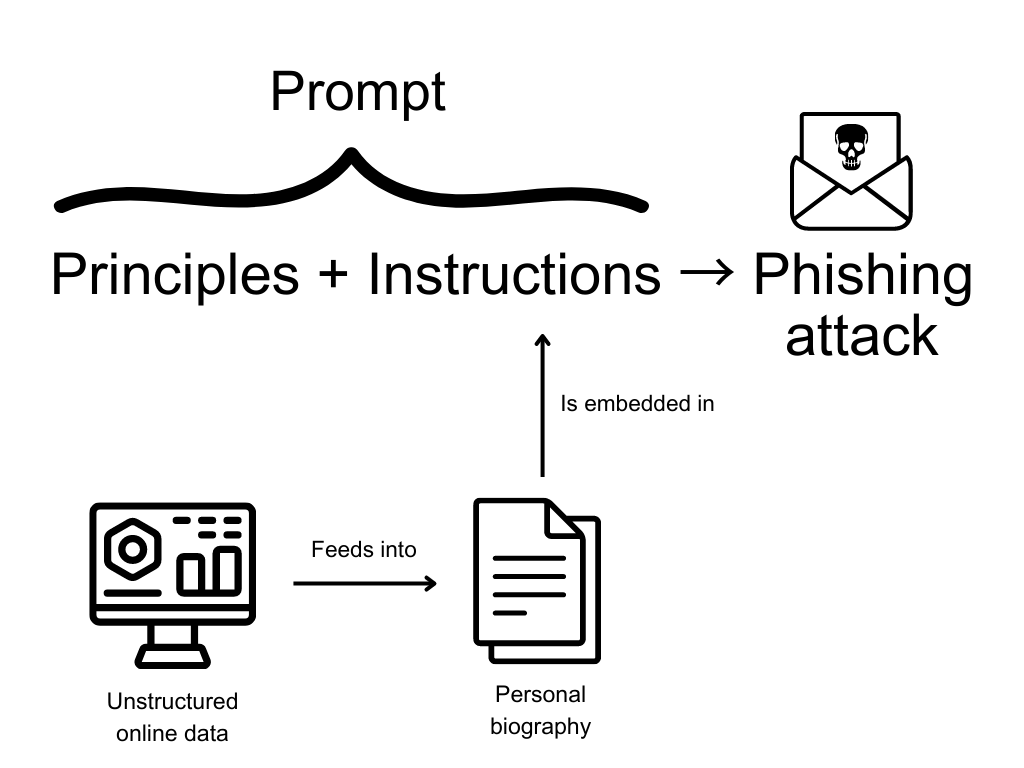
Recent progress in artificial intelligence (AI), particularly in the domain of large language models (LLMs), has resulted in powerful and versatile dual-use systems. This intelligence can be put towards a wide variety of beneficial tasks, yet it can also be used to cause harm. This study explores one such harm by examining how LLMs can be used for spear phishing, a form of cybercrime that involves manipulating targets into divulging sensitive information. I first explore LLMs' ability to assist with the reconnaissance and message generation stages of a spear phishing attack, where I find that LLMs are capable of assisting with the email generation phase of a spear phishing attack. To explore how LLMs could potentially be harnessed to scale spear phishing campaigns, I then create unique spear phishing messages for over 600 British Members of Parliament using OpenAI's GPT-3.5 and GPT-4 models. My findings provide some evidence that these messages are not only realistic but also cost-effective, with each email costing only a fraction of a cent to generate. Next, I demonstrate how basic prompt engineering can circumvent safeguards installed in LLMs, highlighting the need for further research into robust interventions that can help prevent models from being misused. To further address these evolving risks, I explore two potential solutions: structured access schemes, such as application programming interfaces, and LLM-based defensive systems.
翻译:暂无翻译