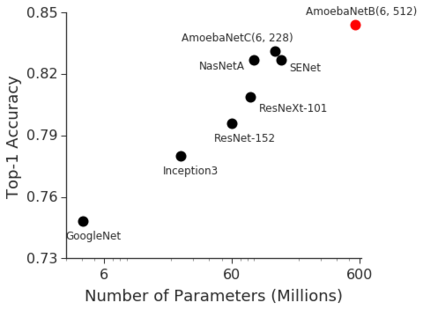
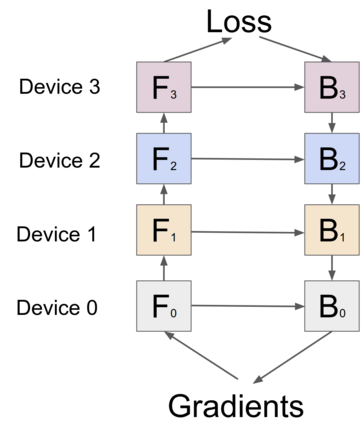
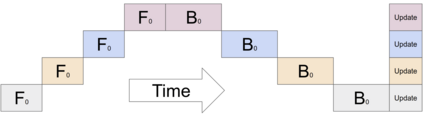
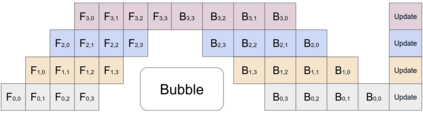
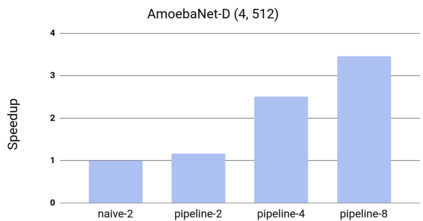
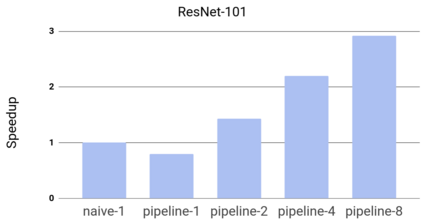
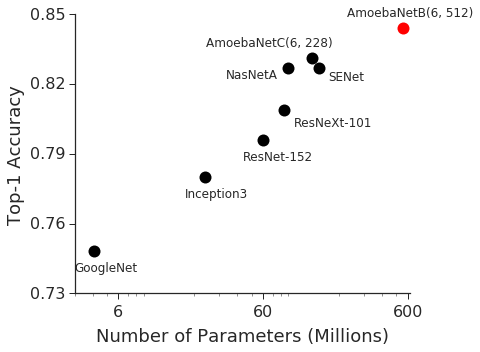
GPipe is a scalable pipeline parallelism library that enables learning of giant deep neural networks. It partitions network layers across accelerators and pipelines execution to achieve high hardware utilization. It leverages recomputation to minimize activation memory usage. For example, using partitions over 8 accelerators, it is able to train networks that are 25x larger, demonstrating its scalability. It also guarantees that the computed gradients remain consistent regardless of the number of partitions. It achieves an almost linear speed up without any changes in the model parameters: when using 4x more accelerators, training the same model is up to 3.5x faster. We train a 557 million parameters AmoebaNet model on ImageNet and achieve a new state-of-the-art 84.3% top-1 / 97.0% top-5 accuracy on ImageNet. Finally, we use this learned model as an initialization for training 7 different popular image classification datasets and obtain results that exceed the best published ones on 5 of them, including pushing the CIFAR-10 accuracy to 99% and CIFAR-100 accuracy to 91.3%.
翻译:GPipe是一个可扩缩的管道平行库,可以让巨型深神经网络学习。 它通过加速器和管道执行将网络层隔开, 以达到高硬件利用率。 它利用重新计算来尽量减少激活内存的使用。 例如, 它使用8个加速器的分割器, 它能够训练25x以上的网络, 展示其可扩缩性。 它还保证计算出的梯度保持一致性, 不论分区数量多少。 它在模型参数方面没有任何变化, 几乎直线速度加快: 当使用 4x 更多的加速器时, 训练同样的模型更快到3.5x。 我们在图像网络上培训了55 700万个参数 AmoebaNet 模型, 并在图像网络上实现了一个新的最先进的84.3% 1% / 97.0% 5 精确度 。 最后, 我们使用这个学习的模型作为初始化模型, 用于培训7个不同的流行图像分类数据集, 并获得超过其中5个最佳公布数据集的结果, 包括将CIFAR- 10 10 精确度提高到99% 和 CIFAR- 100 精确度达913%。