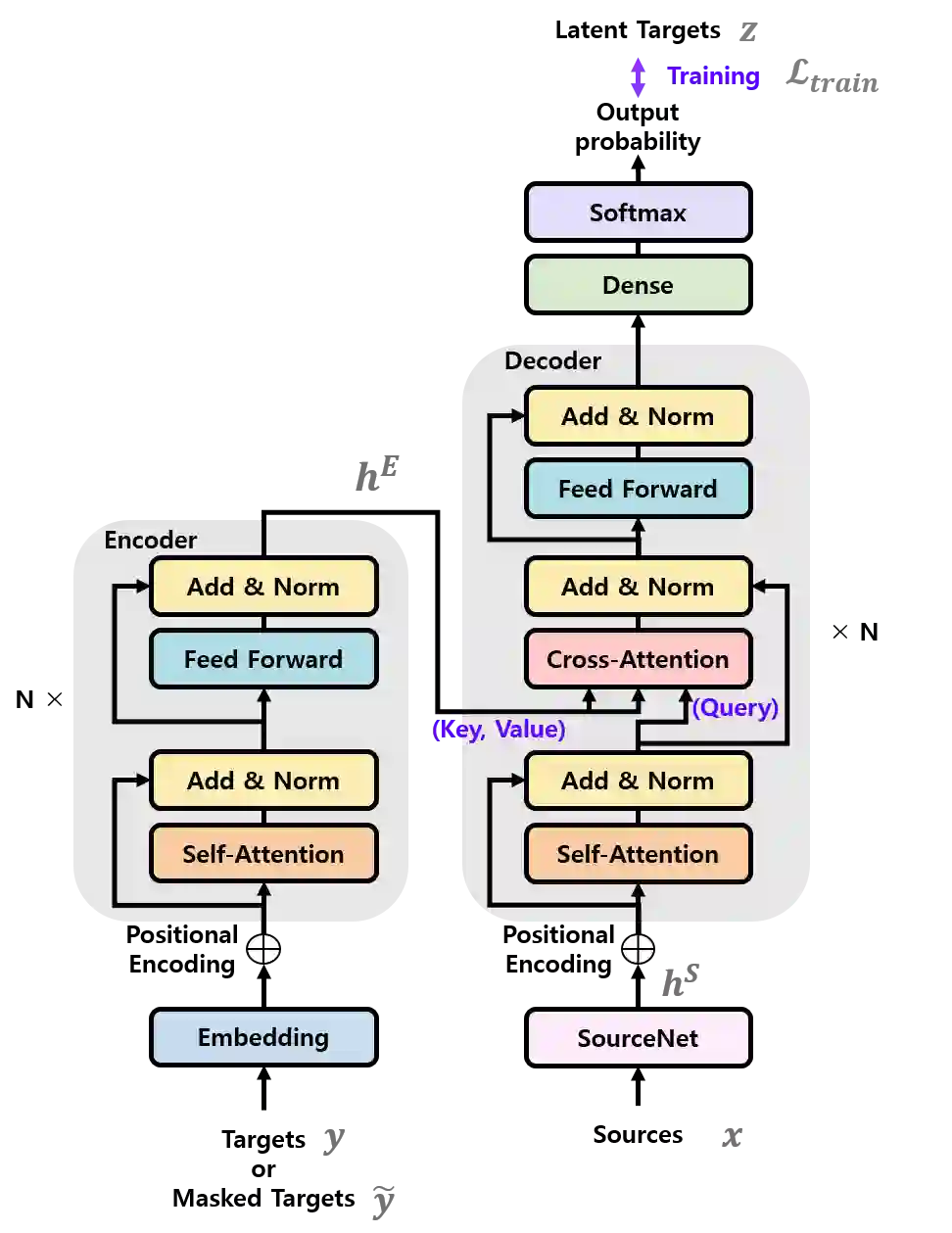
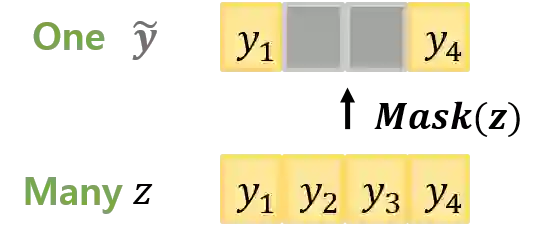
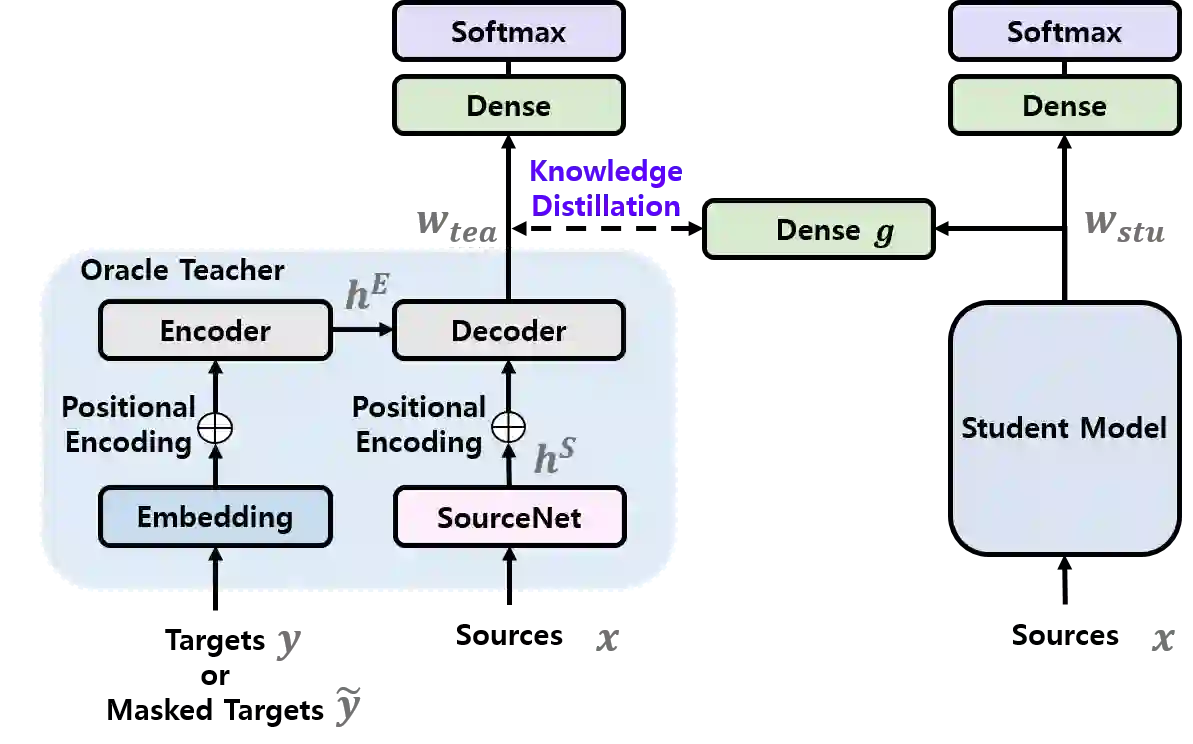
Knowledge distillation (KD), best known as an effective method for model compression, aims at transferring the knowledge of a bigger network (teacher) to a much smaller network (student). Conventional KD methods usually employ the teacher model trained in a supervised manner, where output labels are treated only as targets. Extending this supervised scheme further, we introduce a new type of teacher model for KD, namely Oracle Teacher, that utilizes the embeddings of both the source inputs and the output labels to extract a more accurate knowledge to be transferred to the student. One potential risk for the proposed approach is a trivial solution that the model's output directly copies the oracle input. In Oracle Teacher, we present a training scheme that can effectively prevent the trivial solution and thus enables utilizing both source inputs and oracle inputs for model training. Extensive experiments are conducted on three different sequence learning tasks: speech recognition, scene text recognition, and machine translation. From the experimental results, we empirically show that the proposed model improves the students across these tasks while achieving a considerable speed-up in the teacher model's training time.
翻译:知识蒸馏(KD)最常称为一种有效的模型压缩方法,其目的在于将更大的网络(教师)的知识传授给一个小得多的网络(学生)。常规的KD方法通常使用以监督方式培训的教师模式,这种模式只将输出标签作为目标。进一步推广这一监督的计划,我们为KD引入一种新的教师模式,即甲骨文教师,这种模式利用源投入和输出标签的嵌入来获取更准确的知识,以便传递给学生。拟议方法的一个潜在风险是该模型输出直接复制神器输入的微不足道的解决方案。在Oracle师傅中,我们提出了一个培训计划,能够有效防止微小的解决方案,从而能够同时利用源投入和神器投入进行模型培训。我们根据实验结果对三种不同的学习任务进行了广泛的实验:语音识别、现场文本识别和机器翻译。我们从实验结果中可以看出,拟议的模型改进了学生完成这些任务的进度,同时在教师模型的培训时间上实现相当的加速。