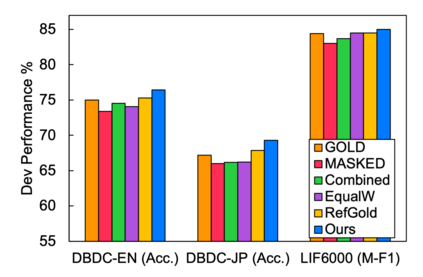
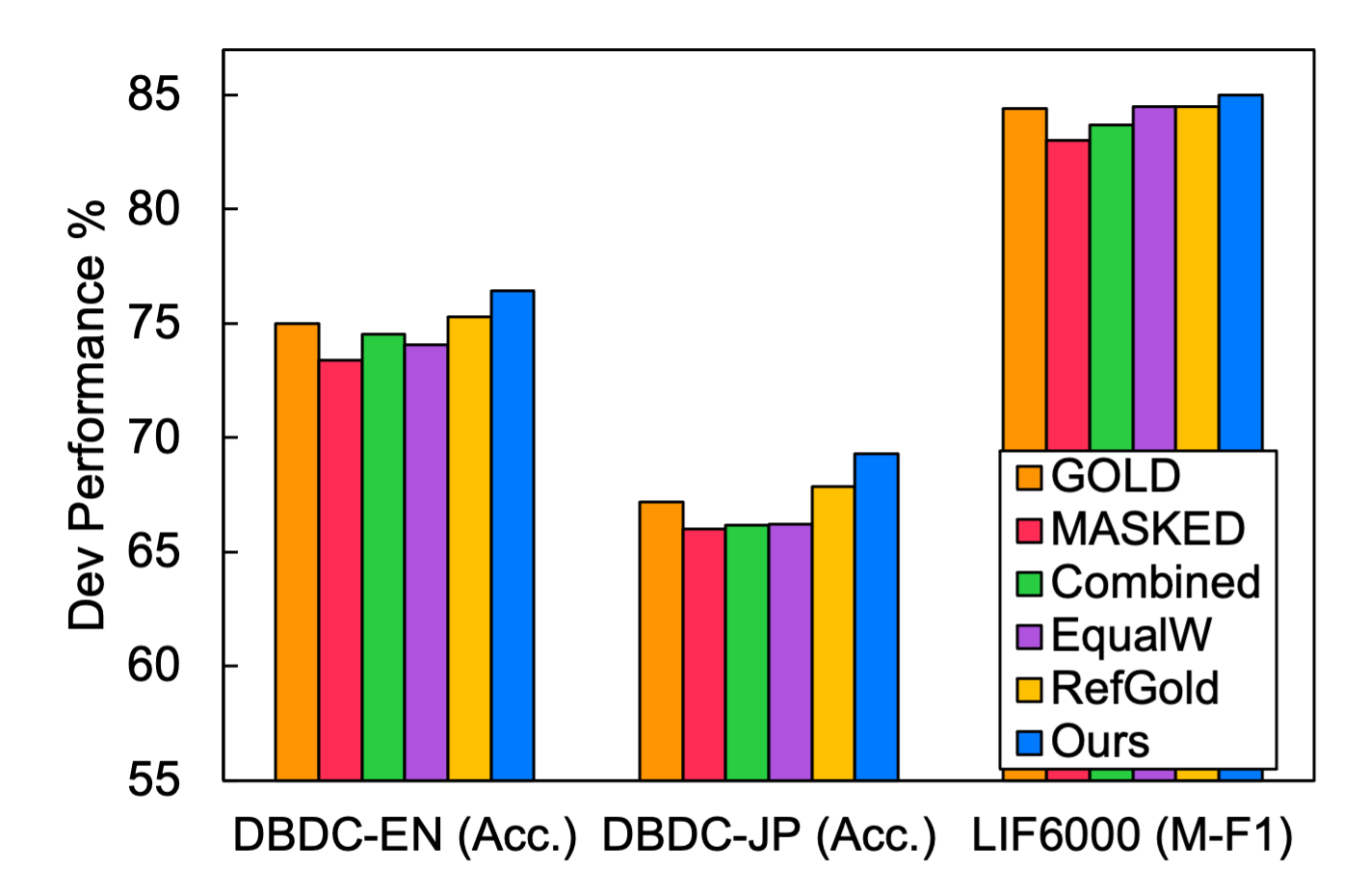Identifying breakdowns in ongoing dialogues helps to improve communication effectiveness. Most prior work on this topic relies on human annotated data and data augmentation to learn a classification model. While quality labeled dialogue data requires human annotation and is usually expensive to obtain, unlabeled data is easier to collect from various sources. In this paper, we propose a novel semi-supervised teacher-student learning framework to tackle this task. We introduce two teachers which are trained on labeled data and perturbed labeled data respectively. We leverage unlabeled data to improve classification in student training where we employ two teachers to refine the labeling of unlabeled data through teacher-student learning in a bootstrapping manner. Through our proposed training approach, the student can achieve improvements over single-teacher performance. Experimental results on the Dialogue Breakdown Detection Challenge dataset DBDC5 and Learning to Identify Follow-Up Questions dataset LIF show that our approach outperforms all previous published approaches as well as other supervised and semi-supervised baseline methods.
翻译:目前对话的分解有助于提高沟通效率。关于这个专题的大部分先前工作都依靠人类附加说明的数据和数据增强来学习分类模型。质量标签的对话数据需要人类注解,而且通常费用昂贵,但从各种来源收集的无标签数据比较容易。在本文件中,我们提议建立一个新的半监督的教师-学生学习框架来完成这项任务。我们引入了两名教师,他们分别接受标签数据和被扰动的标签数据培训。我们利用未贴标签的数据来改进学生培训的分类,即我们雇用两名教师,通过教师-学生学习,改进未贴标签数据标签的标签。通过我们拟议的培训方法,学生可以改进单教师的成绩。“对话分解发现挑战数据集 DBDC5 ” 和“学习确定后续问题数据集LIF”的实验结果显示,我们的方法超越了以前公布的所有方法以及其他受监督和半监督的基线方法。