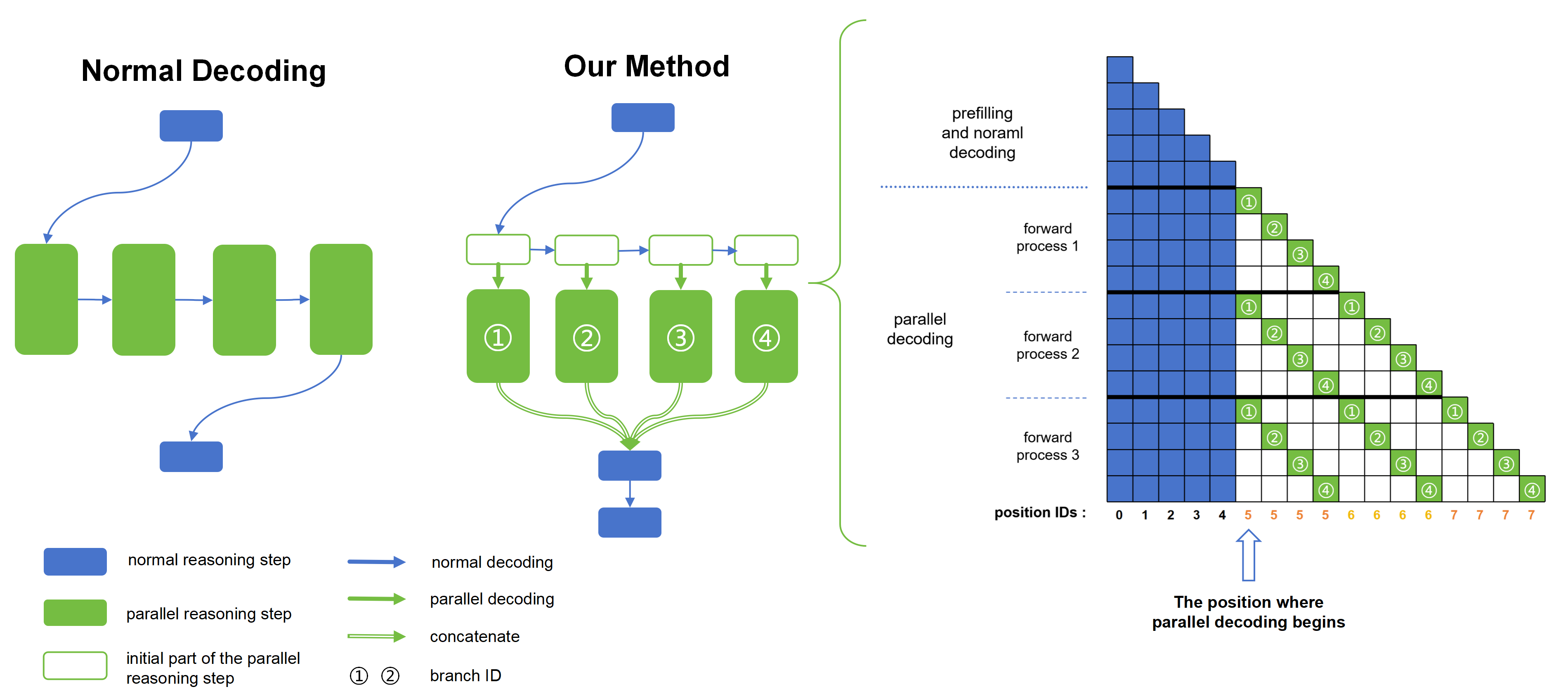
Recent advances in reasoning models have demonstrated significant improvements in accuracy, particularly for complex tasks such as mathematical reasoning, by employing detailed and comprehensive reasoning processes. However, generating these lengthy reasoning sequences is computationally expensive and time-consuming. To address this inefficiency, we leverage the inherent parallelizability of certain tasks to accelerate the reasoning process. Specifically, when multiple parallel reasoning branches exist, we decode multiple tokens per step using a specialized attention mask, processing them within a single sequence, avoiding additional memory usage. Experimental results show that our method achieves over 100% speedup in decoding time while maintaining the answer quality.
翻译:暂无翻译