白话attention综述(上)
作者: 章锦川 (大三)
知乎专栏:NLP成长之路
学校:华南农业大学
原文链接:
https://zhuanlan.zhihu.com/p/73357761
今天这篇文章主题的是attention model, 写这篇文章一方面是为了自己加深和拓宽自己对attention的认识,一方面也是想帮助一下刚起步的同学理解这个相对抽象一点儿的概念。此前已有不少大神分享过他们对attention的解读和见解了,我也会引用一些,但我希望在他们的基础上介绍得更易于理解、涵盖得更广一些(毕竟这两年各种attention的应用层出不穷)
本篇将分为几个部分:attention的由来和在NLP领域的发展、attention的常见门类及其进一步的介绍、相关方法的拓展阅读。
Attention的由来
attention 最早是由 Bahdanau在做机器翻译时提出的,我们知道机器翻译是个典型的seq2seq问题,起初一般采用传统的encoder-decoder模型:
常见的是encoder用一层RNN对输入进行编码,最终得到一固定长度的向量,再将其作为decoder的输入,decode也是一层RNN,依此产生一个输出序列。
从传统的统计机器翻译到上述的encoder-decoder模型是一个质的飞跃,但后来大家逐渐发现传统的encoder-decoder有几个令人难以忽视的问题。一是不管多长的句子,最终都压缩到了隐藏层的一个固定长度的向量 
近年来层出不穷的注意力模型不仅缓解了上述的几个问题,还增强了神经网络模型的可解释性,最直观的我认为要算caption生成问题,所谓caption生成,就是给定一张图片,生成一句话来描述这张图片。常规的做法是先选一个词作为起始token,然后经过RNN每一步生成一个词,未使用attention之前:
x指image,通常是一张图片经过CNN提取后得到的特征向量,使用attention后:
x可以是一张图片划分成的不同部分,分别计算它们与上一个隐藏态的得分,将得分作为各个部分的权重,加权求和作为当前隐藏态的输入,便可得到下一个词应该更关注图片的哪个部分。

谈到这里,大家应该对attention已经有了一个比较感性的认识,接下来我们用不同的分类方式深入剖析一下近几年出现的这些attention模型。
本文对attention的分类主要参考了 An Attentive Survey of Attention Models 这篇非常精彩的综述。
按参与计算attention的序列数来分
self-attention
self-attention一般是用于输入是一个序列,但输出并非是一个序列的问题。比如情感分析这种文本分类问题,输出是一个情感倾向或说某个类别,所以我们可以将其视为单个序列参与attention计算的一种。self-attention首次由Yang等人在 Hierarchical Attention Networks for Document Classification 中提出
下面我们详细介绍一下这个模型
首先不要被这幅图吓到,其实它想刻画的含义是不难理解的。
先从宏观上看,这个模型将一篇待分类的文章分成了两级结构,从下往上,若干词先组成一个句子,而后若干句子再构成一篇文章。
再来看具体的细节:



论文中采用的方法是每句话的各个词先乘以词嵌入矩阵,得到各自的词向量表示后再经过一层双向GRU, 并将两个方向的隐藏态拼接起来:
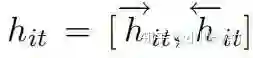
然后将得到的 

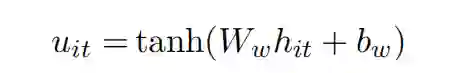
此时我们引入一个词级别的上下文向量 
我们通过下列公式计算每个词的重要性得分:
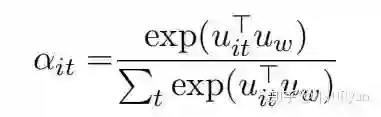
然后得分将作为权重,对每个词的隐藏态加权求和得到这个句子的最终表示
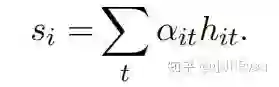
我们可以认为此时的
上述是第一级self-attention, 从词到句,第二级从句到篇也几乎是同理:
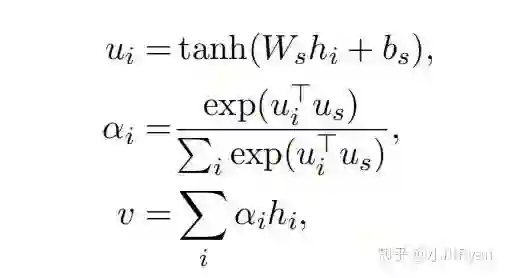
每个句子 


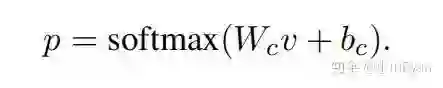
采用交叉熵损失函数进行训练即可:
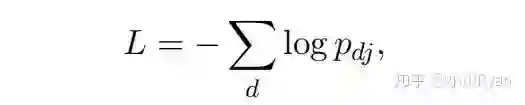
HAN计算了两次self-attention,每次计算都是在自身序列(第一次词序列,第二次句子序列)上进行计算的,可认为只有一个序列参与了attention计算。
distinctive attention
distinctive attention 不是啥新出现的attention门类,而是综述作者为了分类,对 两个序列参与attention计算的attention一种称呼。
最典型的distinctive attention自然是由Bahdanau最早提出的用于机器翻译的attention了。
他基于encoder-decoder引入attention后的模型大概可以表述为:
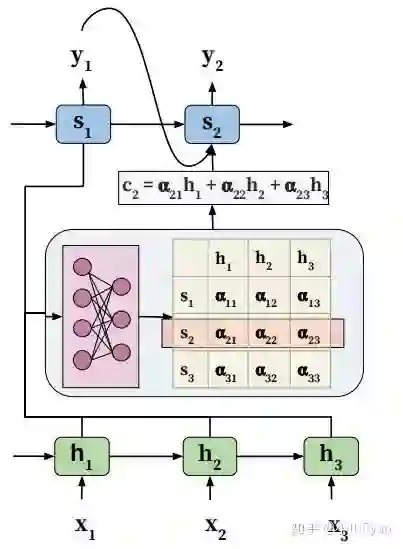
输入序列经过一层双向RNN作为encoder得到隐藏态 

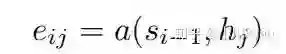
a为图中的全连接层,再经过归一化:
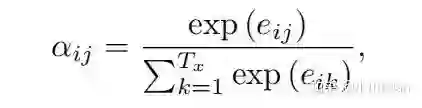
并进行加权求和后,得到context向量:
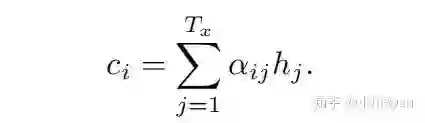
用其计算decoder的下一个状态:
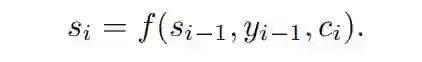
从而计算出输出序列的下一个状态:

为便于理解这种计算attention时用到了两个状态序列的我们可称其为distinctive attention,常用于诸如机器翻译、文档摘要、caption、语音识别等场景。
co-attention
计算attnetion涉及的序列可能不止两个,可能是三个甚至多个。这时我们可以称其为co-attention. 例如视觉问答问题中,给定一张图片和一个问题,需要生成响应的答案,那么这个时候就可以用图片、问题和答案三者联合学习注意力权重:
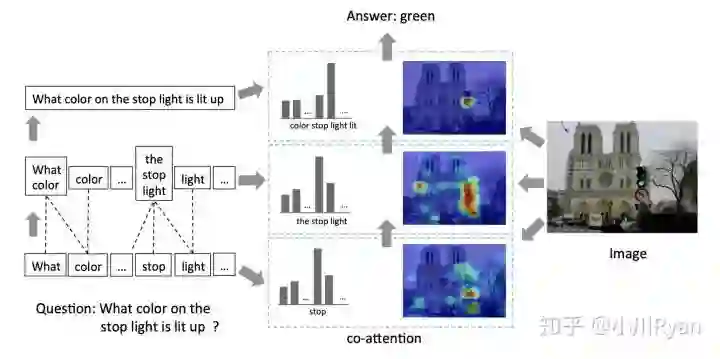
感兴趣的可以参见论文 Hierarchical question-image co-attention for visual question answering
按encoder序列参与计算attention的位置分
soft attention vs. hard attention
soft attention和hard attention的概念最早由Xu在
Show, Attend and Tell: Neural Image Caption Generation with Visual Attention提出
soft attention并非是啥新算法,它也是作者按计算attention方式不同所作出的一个分类,所谓"soft",是指对于输入序列的各个状态计算出得分后,将这个得分作为每个状态的权重,进行加权求和;而hard attention则是对输入序列的各个状态采样,计算到的每个状态的得分是它们被采样到的概率。
由于hard attention随机采样的思想,为了还能使用反向传播计算梯度,需要使用蒙特卡罗方法来对所有可能的采样结果进行求平均。而相比之下,soft attention就计算梯度而言会简便一些。
soft attention和hard attention最主要的差别就在于此,而计算attention得分的方法并无很大差别,故对caption generation感兴趣的同学可以去看看Xu的论文,如果觉得比较难理解的话,可以看看这篇比较清晰易懂的博客:"Soft & hard attention" ,在此就不赘述了。
global attention vs. local attention
global attention和local attention是Luong15年在
Effective Approaches to Attention-based Neural Machine Translation中提出来的,其中global attention与Bahdanau最早提出用于机器翻译领域的attention, 以及上面的soft attention几乎没有任何区别,如果非要说有什么区别的话,主要在于Bahdanau的论文中attention是对输入序列经过双向RNN后得到的隐藏态计算的,而Luong的网络结构是输入序列经过两层LSTM,后用最上层的LSTM的隐藏态来算attention得分;除此之外就没啥区别了
而至于local attention, 其实思想跟hard attention差不多,它们都是为了改善当输入序列过长,需要对每个状态都计算attention得分的高计算成本问题。只不过hard attention是通过将得到的attention得分作为每个状态被采样到的概率,而local attention是根据位置来采样的,它先选定一个中点 
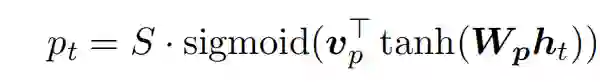
来选取,其中S是序列的长度,乘以范围为[0,1]的sigmoid之后即可选取[0,S]中的任何一个位置,然后选取一个窗口,大小为 

按attention的层次结构分
按层次结构分应该很好理解,大部分的attention都仅在原来的输入序列的层次上计算得到,可视为是单层的。而像上面提到的HAN便是两层的,除此之外,Zhao and Zhang在Attention-via-Attention Neural Machine Translation 还提出了character-level到word-level的多层注意力,感兴趣也可以去详细看看。
按输入序列的representation数分
这种划分的方式是指,对于输出序列采用几种不同的表示时或者提取的是输入序列不同维度的特征时,attention可以帮助用来选择几种表示的权重。比如论文Dynamic Meta-Embeddings for Improved Sentence Representations 中就用attention来对不同的word embedding方式做融合,比简单地将embedding拼接或求平均取得了更好的效果。
关于attention的分类暂时就介绍到这里,如果大家有啥比较有意思的想法或分类方式欢迎大家一起交流。下一篇文章我会探讨一下attention常用于的几种网络结构,并引出transformer,为后面继续完成词向量系列的文章做铺垫。
本文转载自公众号:机器学习算法与自然语言处理,作者:章锦川
推荐阅读
我们建了一个免费的知识星球:AINLP芝麻街,欢迎来玩,期待一个高质量的NLP问答社区
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLP君微信(id:AINLP2),备注工作/研究方向+加群目的。




