深度学习变天,模型越做越小!Google发布FLAN,模型参数少400亿,性能超越GPT-3
![]()
来源:新智元
本文约2158字,建议阅读4分钟
本文介绍了Google最新发布的一个新的语言模型——FLAN。


【导读】你是否抱怨过深度学习这畸形的研究发展路线,大公司才能玩得起sota,普通人连买张显卡都要承受几倍的溢价!最近Google发布了一个新的语言模型FLAN,或许能在深度学习中带来新的发展趋势,它相比GPT-3少了400亿参数,性能还更强!


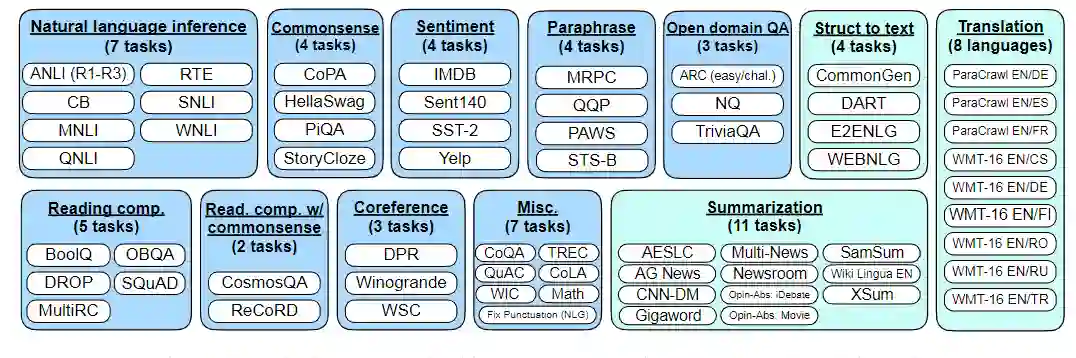

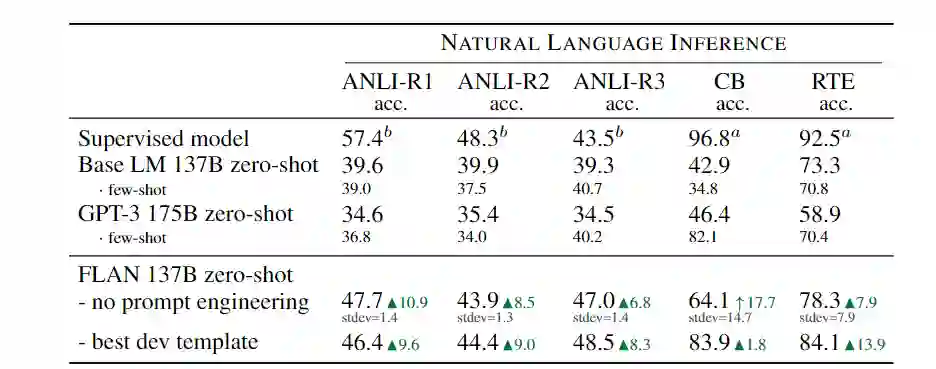




参考资料:
https://arxiv.org/pdf/2109.01652.pdf

登录查看更多
相关内容
Arxiv
0+阅读 · 2022年4月14日
Arxiv
16+阅读 · 2017年11月20日



相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年4月14日
Arxiv
16+阅读 · 2017年11月20日