从 BERT 到 GPT-2 再到 GPT-3,大模型的规模是一路看涨,表现也越来越惊艳。增大模型规模已经被证明是一条可行的改进路径,而且 DeepMind 前段时间的一些研究表明:这条路还没有走到头,继续增大模型依然有着可观的收益。
但与此同时,我们也知道,增大模型可能并不是提升性能的唯一路径,前段时间的几个研究也证明了这一点。其中比较有代表性的研究要数 DeepMind 的 RETRO Transformer 和 OpenAI 的 WebGPT。这两项研究表明,如果我们用一种搜索 / 查询信息的方式来增强模型,小一点的生成语言模型也能达到之前大模型才能达到的性能。
在大模型一统天下的今天,这类研究显得非常难能可贵。
在这篇文章中,擅长机器学习可视化的知名博客作者 Jay Alammar 详细分析了 DeepMind 的 RETRO(Retrieval-Enhanced TRansfOrmer)模型。该模型与 GPT-3 性能相当,但参数量仅为 GPT-3 的 4%。
![]()
![]()
RETRO 整合了从数据库中检索到的信息,将其参数从昂贵的事实和世界知识存储中解放出来。
在 RETRO 之前,研究社区也有一些工作采用了类似的方法,因此本文并不是要解释它的新颖性,而是该模型本身。
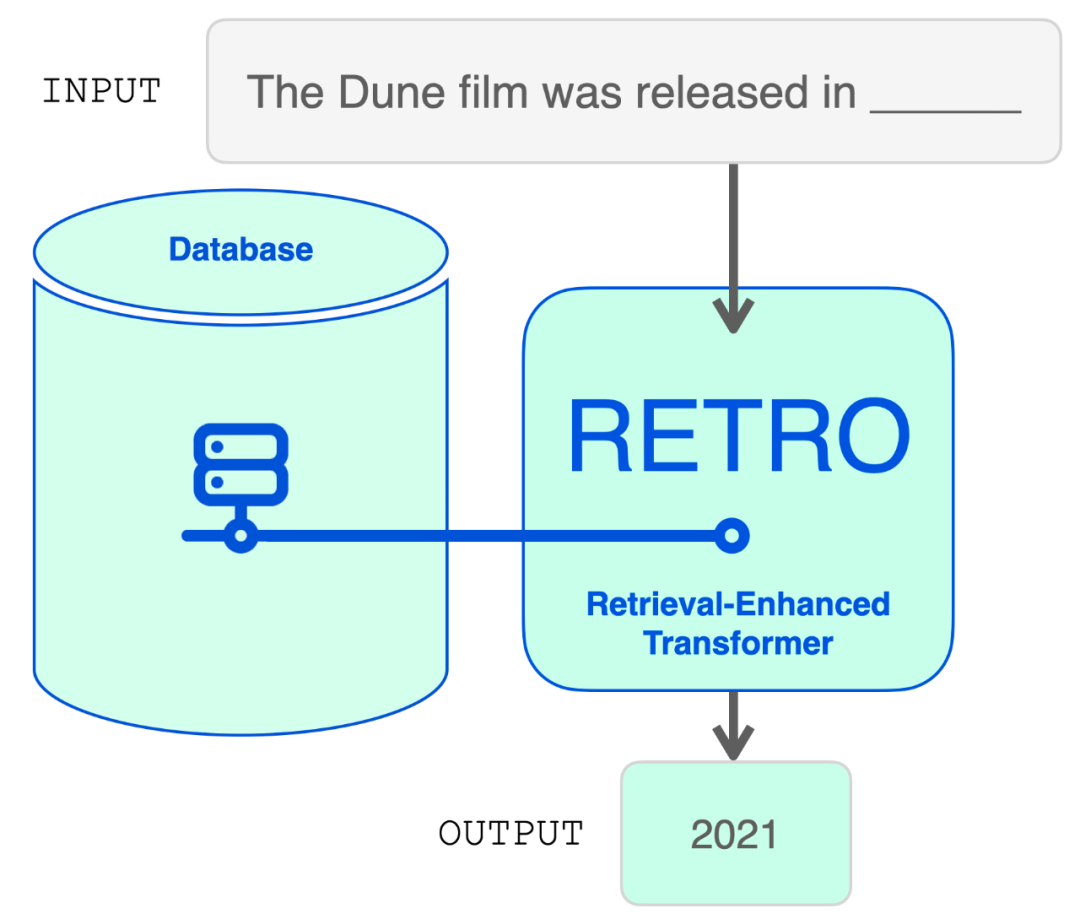
一般来讲,语言模型的任务就是做填空题,这项任务有时候需要与事实有关的信息,比如
![]()
但有时候,如果你对某种语言比较熟悉,你也可以直接猜出空白部分要填什么,例如:
![]()
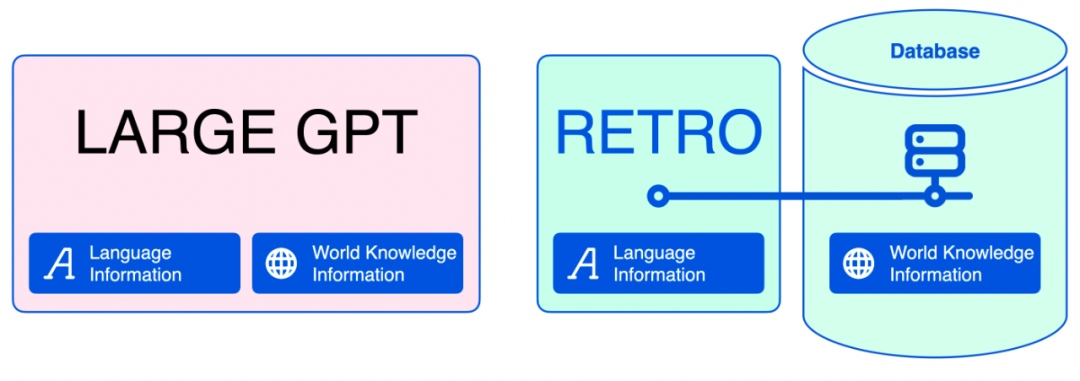
这种区别非常重要,因为大型语言模型将它们所知道的一切都编码到模型参数中。虽然这对于语言信息是有意义的,但是对于事实信息和世界知识信息是无效的。加入检索方法之后,语言模型可以缩小很多。在文本生成过程中,神经数据库可以帮助模型检索它需要的事实信息。
![]()
随着训练数据记忆量的减少,我们可以使用较小的语言模型来加速训练。任何人都可以在更小、更便宜的 GPU 上部署这些模型,并根据需要对它们进行调整。
从结构上看,RETRO 是一个编码器 - 解码器模型,就像原始的 Transformer。然而,它在检索数据库的帮助下增加了输入序列。该模型在数据库中找到最可能的序列,并将它们添加到输入中。RETRO 利用它的魔力生成输出预测。
![]()
在探索模型架构之前,让我们先深入挖掘一下检索数据库。
此处的数据库是一个键值存储(key-value store)数据库。其中 key 是标准的 BERT 句子嵌入,value 是由两部分组成的文本:
Neighbor,用于计算 key;
Completion,原文件中文本的延续。
RETRO 的数据库包含基于 MassiveText 数据集的 2 万亿个多语言 token。neighbor chunk 和 completion chunk 的长度最多为 64 个 token。
![]()
RETRO 数据库内部展示了 RETRO 数据库中键值对的示例。
RETRO 将输入提示分成多个 chunk。为简单起见,此处重点关注如何用检索到的文本扩充一个 chunk。但是,模型会针对输入提示中的每个 chunk(第一个 chunk 除外)执行此过程。
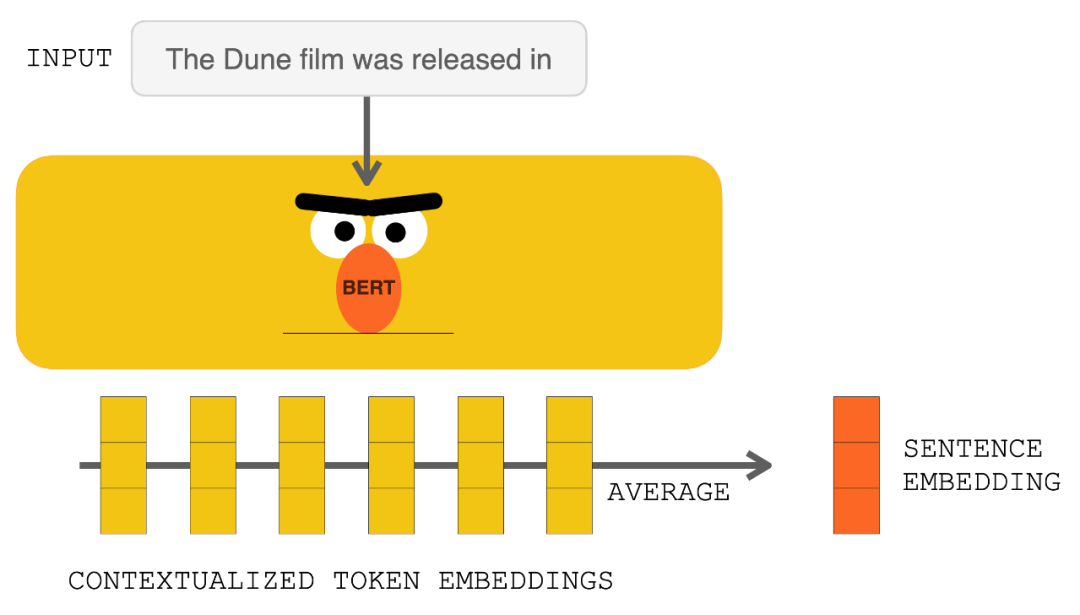
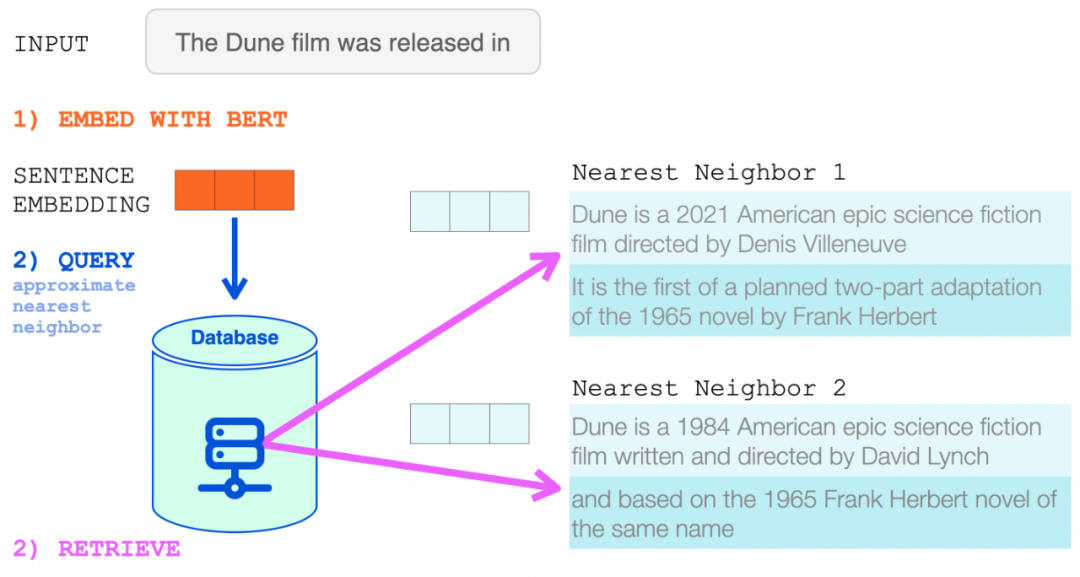
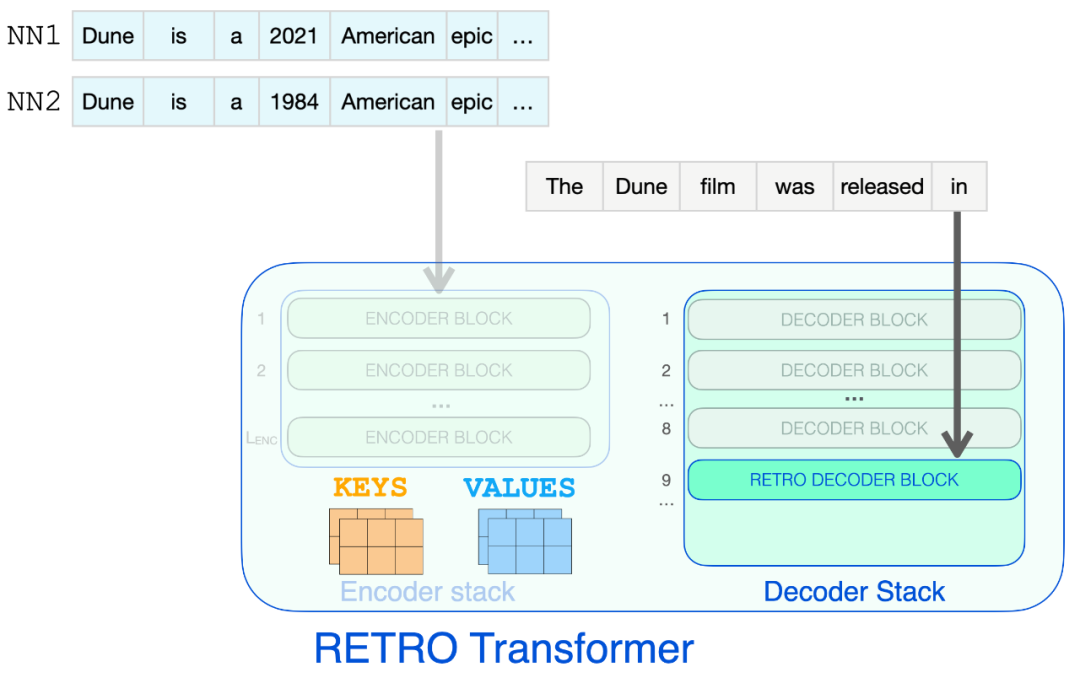
在点击 RETRO 之前,输入提示进入 BERT。对输出的上下文向量进行平均以构建句子嵌入向量。然后使用该向量查询数据库。
![]()
使用 BERT 处理输入提示会生成上下文化的 token 嵌入 。对它们求平均值会产生一个句子嵌入。
然后将该句子嵌入用于近似最近邻搜索。检索两个最近邻,它们的文本成为 RETRO 输入的一部分。
![]()
BERT 句子嵌入用于从 RETRO 的神经数据库中检索最近邻。然后将这些添加到语言模型的输入中。
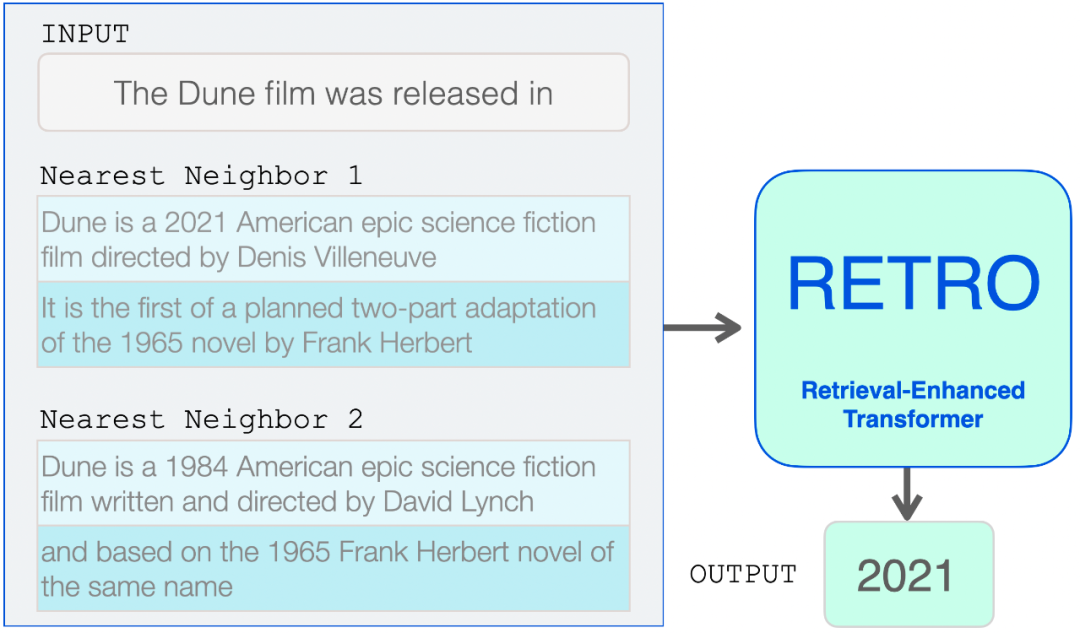
现在 RETRO 的输入是:输入提示及其来自数据库的两个最近邻(及其延续)。
从这里开始,Transformer 和 RETRO 块将信息合并到它们的处理中。
![]()
检索到的近邻被添加到语言模型的输入中。然而,它们在模型内部的处理方式略有不同。
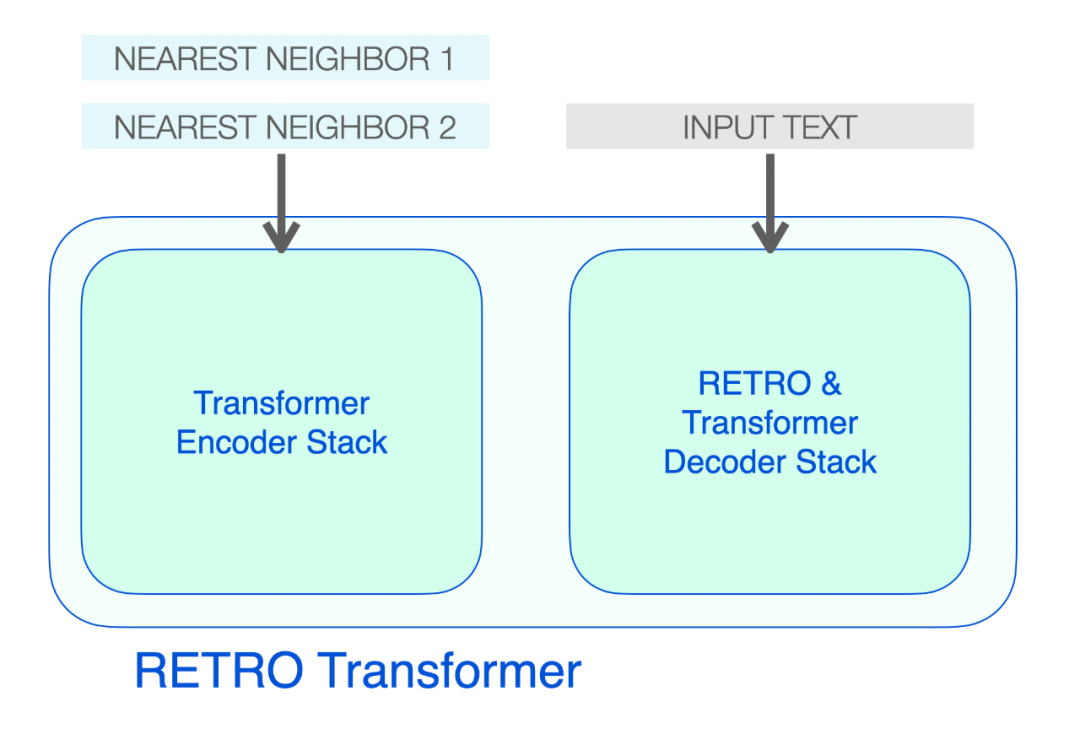
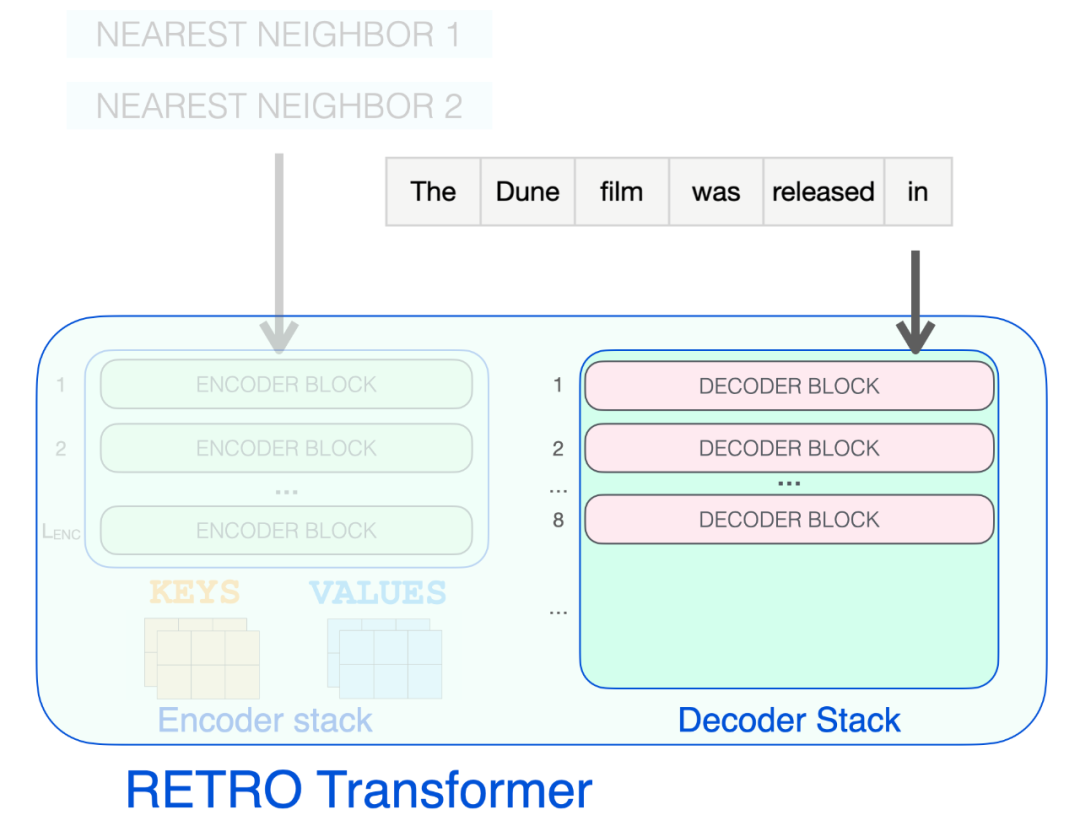
RETRO 的架构由一个编码器堆栈和一个解码器堆栈组成。
![]()
RETRO Transformer 由一个编码器堆栈(处理近邻)和一个解码器堆栈(处理输入)组成。
编码器由标准的 Transformer 编码器块(self-attention + FFNN)组成。Retro 使用由两个 Transformer 编码器块组成的编码器。
![]()
构成 RETRO 的三种 Transformer 模块。
编码器堆栈会处理检索到的近邻,生成后续将用于注意力的 KEYS 和 VALUES 矩阵。
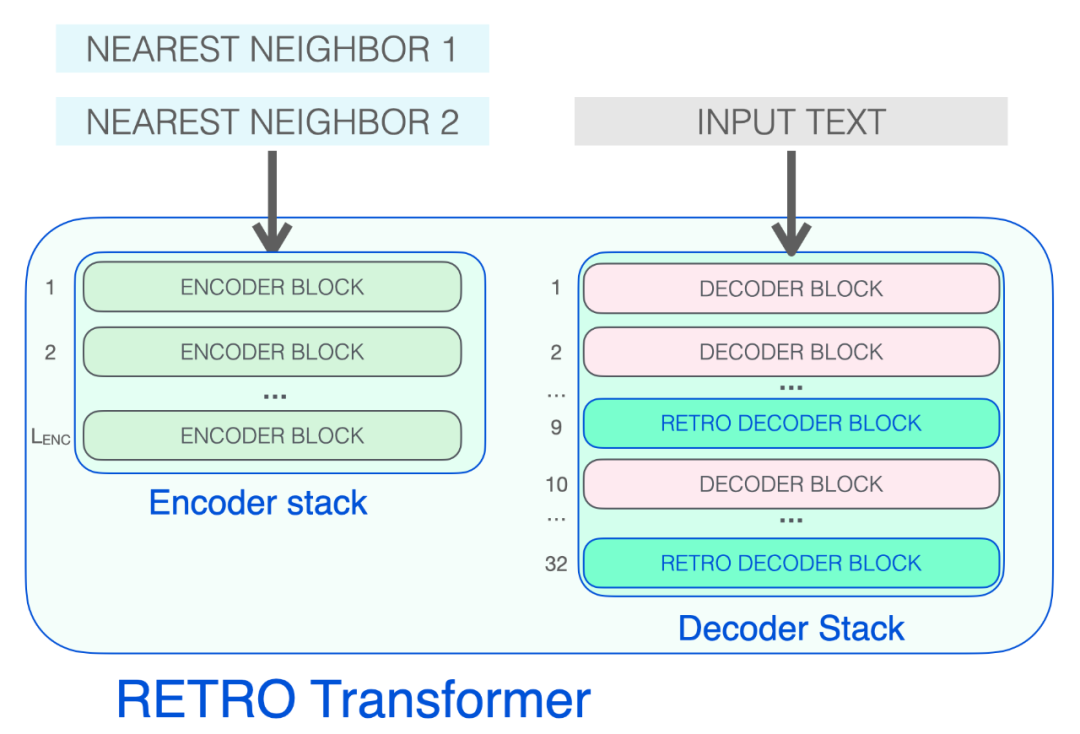
解码器 block 像 GPT 一样处理输入文本。它对提示 token 应用自注意力(因此只关注之前的 token),然后通过 FFNN 层。
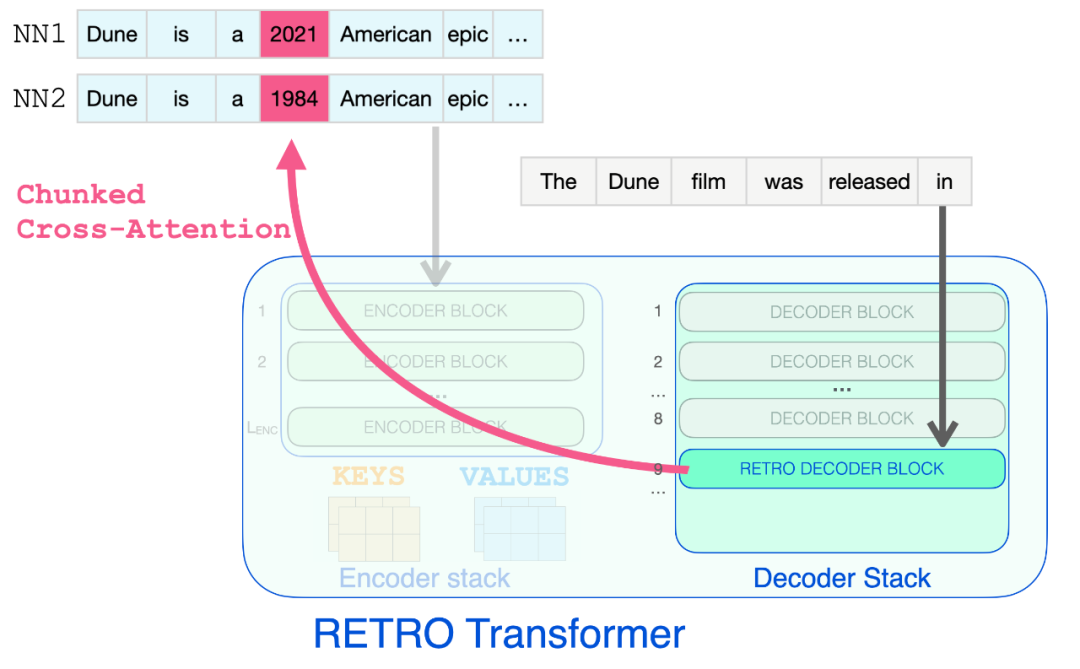
![]()
只有到达 RETRO 解码器时,它才开始合并检索到的信息。从 9 开始的每个第三个 block 是一个 RETRO block(允许其输入关注近邻)。所以第 9、12、15…32 层是 RETRO block。
![]()
下图展示了检索到的信息可以浏览完成提示所需的节点步骤。
![]()
原文链接:http://jalammar.github.io/illustrated-retrieval-transformer/
使用NVIDIA Riva快速构建企业级TTS语音合成助手
NVIDIA Riva 是一个使用 GPU 加速,能用于快速部署高性能会话式 AI 服务的 SDK,可用于快速开发语音 AI 的应用程序。Riva 的设计旨在帮助您轻松、快速地访问会话 AI 功能,开箱即用,通过一些简单的命令和 API 操作就可以快速构建高级别的 TTS 语音合成服务。
2022年1月12日19:30-21:00,本次线上分享主要介绍:
-
-
-
启动 NVIDIA Riva 客户端快速实现文字转语音功能
-
使用 Python 快速搭建基于 Riva 的 TTS 语音合成服务应用
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com