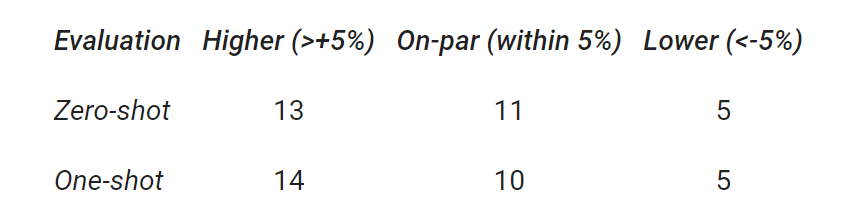©作者 | 机器之心编辑部
来源 | 机器之心
大规模语言模型性能固然好,但计算和资源成本太高了,有没有方法可以更有效地训练和使用 ML 模型呢?
近几年,我们已经看到模型规模越来越大,例如 2018 年诞生的 GPT 具有 1.17 亿参数,时隔一年,2019 年 GPT-2 参数量达到 15 亿,2020 年更是将其扩展到 1750 亿参数的 GPT-3。据了解,OpenAI 打造的超级计算机拥有 285000 个 CPU 核以及 10000 个 GPU,供 OpenAI 在上面训练所有的 AI 模型。
大型语言模型虽然训练昂贵,但也有其重要的一面,例如可以在各种任务中执行小样本学习,包括阅读理解、问答。虽然这些模型可以通过简单地使用更多参数来获得更好的性能。但是有没有方法可以更有效地训练和使用这些模型呢?
为了回答这个问题,谷歌推出了具有万亿权重的通用语言模型 (Generalist Language Model,GLaM),该模型的一大特点就是具有稀疏性,可以高效地进行训练和服务(在计算和资源使用方面),并在多个小样本学习任务上取得有竞争力的性能。
谷歌首先构建了一个高质量的、具有 1.6 万亿 token 的数据集,该无标签数据集很大一部分来自 Web 页面,其范围从专业写作到低质量的评论和论坛页面。此外,谷歌还开发了一个文本质量过滤器,该过滤器是在维基百科和书籍文本数据集上训练而成,由于过滤器训练的数据集质量很高,所以谷歌将其过滤 Web 网页内容的质量。最后,谷歌应用这个过滤器来生成 Web 网页的最终子集,并将其与书籍和维基百科数据相结合来创建最终的训练数据集。
GLaM 是混合专家模型 (MoE) ,这种模型可以被认为具有不同的子模型(或专家),每个子模型都专门用于不同的输入。每一层的专家由一个门控网络控制,该门控网络根据输入数据激活专家。对于每个 token(通常是一个词或词的一部分),门控网络选择两个最合适的专家来处理数据。完整的 GLaM 总共有 1.2T 参数,每个 MoE 包含 64 个专家,总共 32 个 MoE 层,但在推理期间,模型只会激活 97B 的参数,占总参数的 8%。
![]()
GLaM 的体系架构,每个输入 token 都被动态路由到从 64 个专家网络中选择的两个专家网络中进行预测。
与 GShard MoE Transformer 类似,谷歌用 MoE 层替换其他 transformer 层的单个前馈网络(人工神经网络最简单的一层,如上图蓝色方框中的 Feedforward 或 FFN)。MoE 层有多个专家,每个专家都是具有相同架构但不同权重参数的前馈网络。
尽管 MoE 层有很多参数,但专家是稀疏激活的,这意味着对于给定的输入 token,只使用两个专家,这样做的优势是在限制计算的同时给模型提供更多的容量。在训练期间,每个 MoE 层门控网络都经过训练,使用它的输入来激活每个 token 的最佳两位专家,然后将其用于推理。对于 MoE 层的 E 专家来说,这本质上提供了 E×(E-1) 个不同前馈网络组合的集合,而不是经典 Transformer 中的一个组合,从而带来更大的计算灵活性。
最终学习到的 token 表示来自两个专家输出的加权组合,这使得不同的专家可以激活不同类型的输入。为了能够扩展到更大的模型,GLaM 架构中的每个专家都可以跨越多个计算设备。谷歌使用 GSPMD 编译器后端来解决扩展专家的挑战,并训练了多个变体(基于专家规模和专家数量)来了解稀疏激活语言模型的扩展效果。
谷歌使用 zero-shot 和 one-shot 两种设置,其中训练中使用的是未见过的任务。评估基准包括如下:
完形填空和完成任务;
开放域问答;
Winograd-style 任务;
常识推理;
上下文阅读理解;
SuperGLUE 任务;
自然语言推理。
谷歌一共使用了 8 项自然语言生成(NLG)任务,其中生成的短语基于真值目标进行评估(以 Exact Match 和 F1 measure 为指标),以及 21 项自然语言理解(NLU)任务,其中几个 options 中的预测通过条件对数似然来选择。
当每个 MoE 层只有一个专家时,GLaM 缩减为一个基于 Transformer 的基础密集模型架构。在所有试验中,谷歌使用「基础密集模型大小 / 每个 MoE 层的专家数量」来描述 GLaM 模型。比如,1B/64E 表示是 1B 参数的密集模型架构,每隔一层由 64 个专家 MoE 层代替。
谷歌测试了 GLaM 的性能和扩展属性,包括在相同数据集上训练的基线密集模型。与最近微软联合英伟达推出的 Megatron-Turing 相比,GLaM 使用 5% margin 时在 7 项不同的任务上实现了不相上下的性能,同时推理过程中使用的算力减少了 4/5。
此外,在推理过程中使用算力更少的情况下,1.2T 参数的稀疏激活模型(GLaM)在更多任务上实现了比 1.75B 参数的密集 GPT-3 模型更好的平均结果。
![]()
NLG(左)和 NLU(右)任务上,GLaM 和 GPT-3 的平均得分(越高越好)。
谷歌总结了 29 个基准上,GLaM 与 GPT-3 的性能比较结果。结果显示,GLaM 在 80% 左右的 zero-shot 任务和 90% 左右的 one-shot 任务上超越或持平 GPT-3 的性能。
![]()
此外,虽然完整版 GLaM 有 1.2T 的总参数,但在推理过程中每个 token 仅激活 97B 参数(1.2T 的 8%)的子网。
![]()
GLaM 有两种扩展方式:1) 扩展每层的专家数量,其中每个专家都托管在一个计算设备中;2) 扩展每个专家的大小以超出单个设备的限制。为了评估扩展属性,该研究在推理时比较每个 token 的 FLOPS 相似的相应密集模型。
![]()
通过增加每个专家的大小,zero-shot 和 one-shot 的平均性能。随着专家大小的增长,推理时每个 token 预测的 FLOPS 也会增加。
如上图所示,跨任务的性能与专家的大小成比例。在生成任务的推理过程中,GLaM 稀疏激活模型的性能也优于 FLOP 类似的密集模型。对于理解任务,研究者观察到它们在较小的规模上性能相似,但稀疏激活模型在较大的规模上性能更好。
训练大型语言模型计算密集,因此提高效率有助于降低能耗。该研究展示了完整版 GLaM 的计算成本。
![]()
模型推理(左)和训练(右)的计算成本(GFLOPS)。
这些计算成本表明 GLaM 在训练期间使用了更多的计算,因为它在更多的 token 上训练,但在推理期间使用的计算却少得多。下图展示了使用不同数量的 token 进行训练的比较结果,并评估了该模型的学习曲线。
![]()
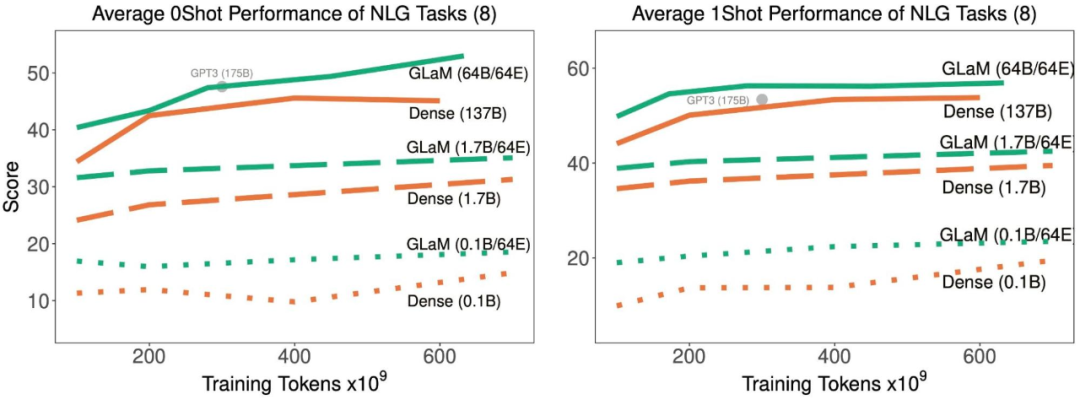
随着训练中处理了更多的 token,稀疏激活型和密集模型在 8 项生成任务上的平均 zero-shot 和 one-shot 性能。
![]()
随着训练中处理了更多的 token,稀疏激活型和密集模型在 21 项理解任务上的平均 zero-shot 和 one-shot 性能。
结果表明,稀疏激活模型在达到与密集模型相似的 zero-shot 和 one-shot 性能时,训练时使用的数据显著减少。并且,如果适用的数据量相同,稀疏型模型的表现明显更好。
![]()
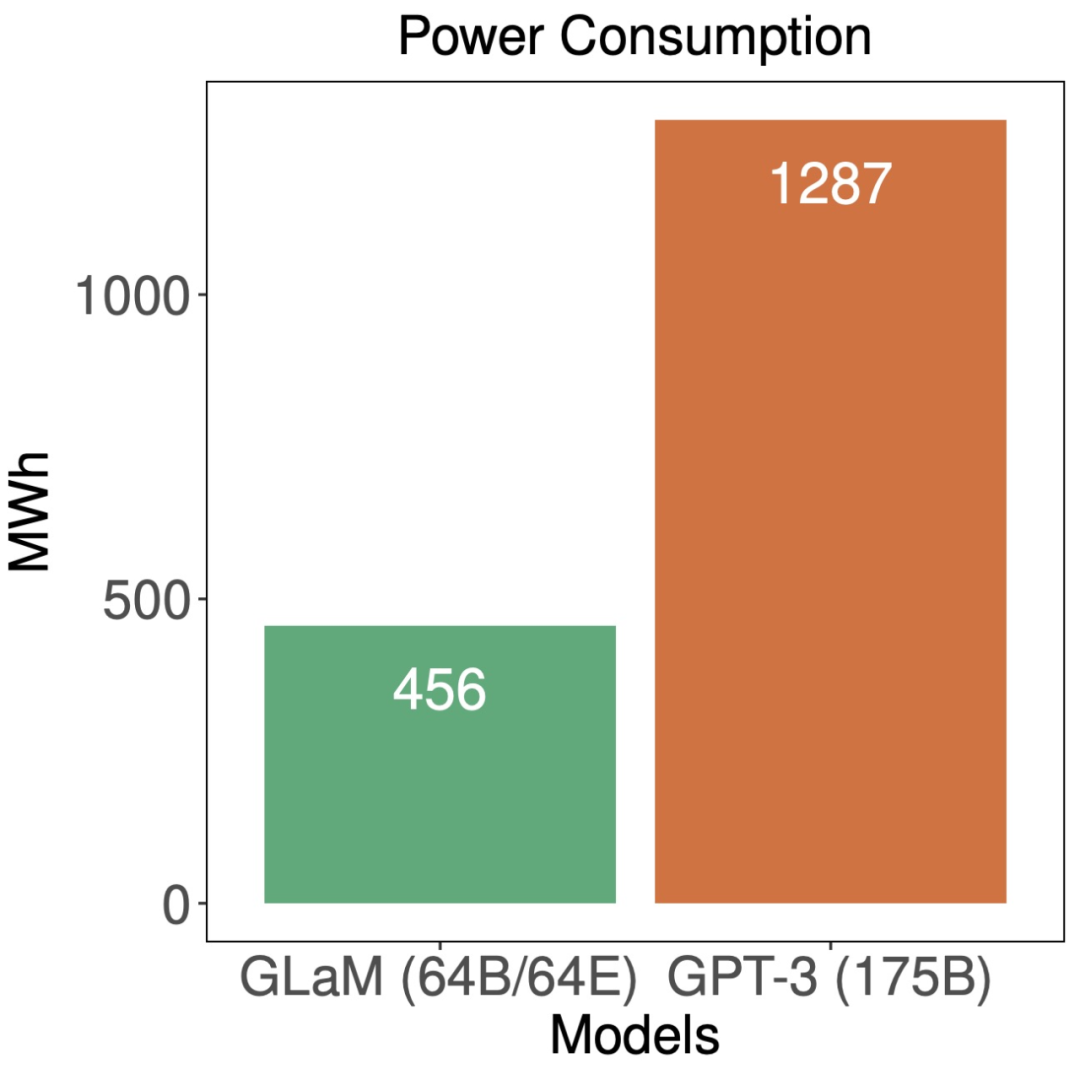
虽然 GLaM 在训练期间使用了更多算力,但得益于 GSPMD(谷歌 5 月推出的用于常见机器学习计算图的基于编译器的自动化并行系统)赋能的更高效软件实现和 TPUv4 的优势,它在训练时耗能要少于其他模型。
英文原文:https://ai.googleblog.com/
感谢 TCCI 天桥脑科学研究院对于 PaperWeekly 的支持。TCCI 关注大脑探知、大脑功能和大脑健康。
![]()
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿
![]()
△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
![]()