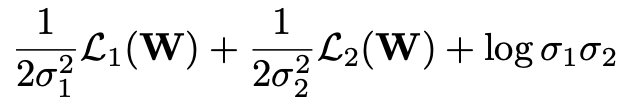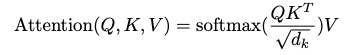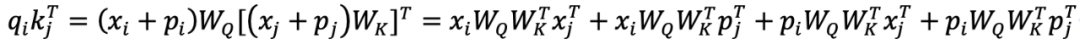今年以来,中文 NLP 圈陆续出现了百亿、千亿甚至万亿参数的预训练语言模型,炼大模型再次延续了「暴力美学」。但 QQ 浏览器搜索团队选择构建十亿级别参数量的「小」模型,提出的预训练模型「摩天」登顶了 CLUE 总排行榜以及下游四个分榜。
2021 年,自然语言处理(NLP)领域技术关注者一定听说过预训练的大名。随着以 BERT 为代表的一系列优秀预训练模型的推出,先基于预训练,再到下游任务的微调训练范式也已经成为一种主流,甚者对于产业界来说,某种意义上打破了之前语义理解的技术壁垒。
一个壁垒的打破,从另一个角度往往也代表着另一个新的试炼战场的形成,即自研预训练模型。2021 年初,各大互联网公司先后推出了自家的预训练模型,在反哺自身业务的同时纷纷在 CLUE 榜单(中文语言理解评测集合)不断刷新成绩和排名。
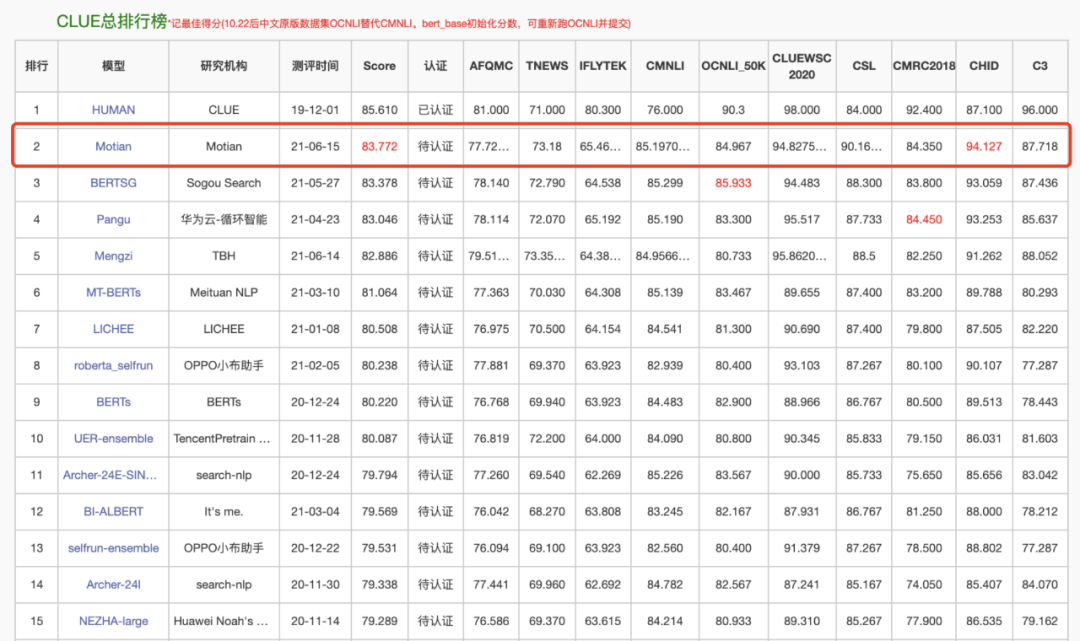
近期,QQ 浏览器搜索语义团队产出的摩天预训练模型在 6 月 15 日
登顶 CLUE 总排行榜单(包括共计 10 个语义类任务),登顶下游 4 个分榜(分类、阅读理解、自然语言推理和 NER)
。本文将介绍 QQ 浏览器搜索语义团队在预训练模型的前沿探索及技术实践。
![]()
注:HUMAN 为人类标注成绩,非模型效果,不参与排名
语义技术是传统搜索的核心能力。从BERT论文发表(2018)至今,预训练+微调的模式是取得语义模型最优效果的必经之路。
对于搜索而言,大多数下游任务场景涉及到query、title以及document这类文本内容,开源的预训练模型在语料上没有应用自身业务数据,直接使用会存在一个bias,无法做到Domain-Adaptive Pretraining;同时,搜索所具有的丰富数据和知识,也能为预训练效果带来很大的助力。因此,QQ浏览器搜索语义团队进行了预训练模型(摩天)的自研,以提升搜索效果的天花板。
从业界看,CLUE作为中文模型的一个最大的benchmark,自20-21年以来越来越多的公司、模型在此打榜。摩天为了进一步验证模型的效果,希望与业界开源的各大预训练模型进行效果对比,取长补短,在效果对比的过程中不断打磨自身硬实力,得到技术沉淀。
QQ 浏览器搜索语义团队随着自身业务快速发展,积累了海量优质资源,一个很自然的想法是利用这些数据构建预训练模型,进一步提升 QQ 浏览器搜索、知识图谱应用等方面的效果,为 QQ 浏览器搜索提供更准确、更智能的结果提供一份力量。
在产业界项目落地上,一个适配自身业务的领域内(
Domain-Adaptive Pretraining
)的预训练模型对业务的帮助是显著的 [2]。基于当前主流的训练范式:pretrain + finetune + distill,更好的预训练模型可以提高下游各个任务 finetune 后的 Teacher 模型效果,从而提升效果的天花板,也通过蒸馏一个线上可应用的 Student 模型获得更好的效果。
QQ 浏览器搜索语义团队秉持小步快跑的打法,没有瞄准百亿、千亿级别参数量的预训练模型,而构建
十亿级别参数量
的「小」模型。这里一方面是希望充分「压榨」预训练网络中每个层、每个参数的性能,做到极致;另一方面是希望模型可以快速、方便在搜索场景下以可控的成本落地。
收集了多类型、大量的数据并清洗出 1TB 高价值数据;
优化 Masked language model 遮蔽方案,消除预训练阶段和微调阶段不一致的问题,引入了搜索点曝任务;
自研一种相对位置编码方案,更敏感捕捉短文本位置信息契合搜索场景;
两阶段训练流程;
大规模 / 大 batch 预训练模型训练能力优化:Pre-LN、混合精度计算、梯度聚集、进一步优化 LAMB optimizer;
使用了有限资源,约 100 张 V100 显卡。
下文会分别从
数据、模型结构 & 训练任务、位置编码、两阶段训练、计算加速
这几个方面来介绍摩天。
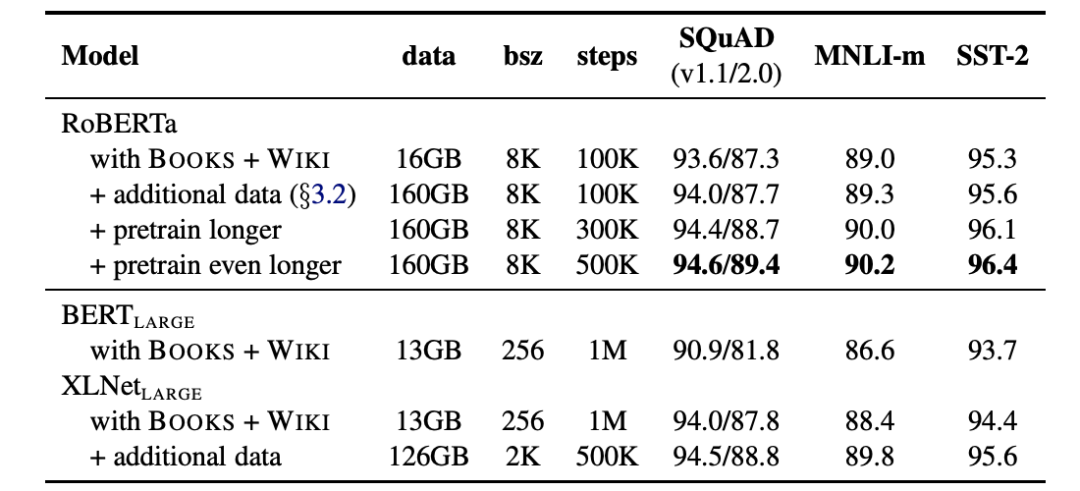
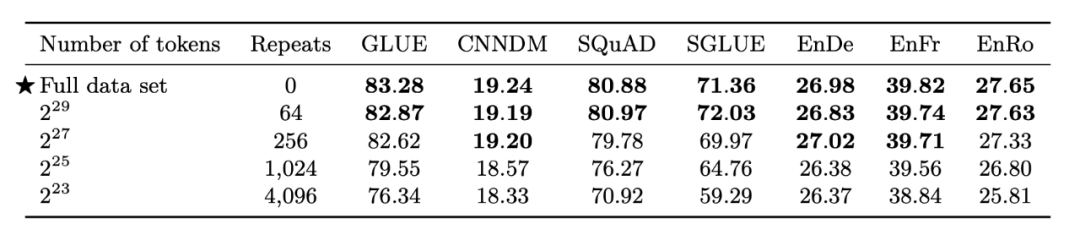
RoBETA、T5 等论文均对预训练模型的训练语料大小、质量进行过实验分析。通常需要几十到几百 GB 的无监督数据。随着预训练模型参数的不断扩大,现阶段也出现了吃几 TB,甚至几十 TB 数据的预训练模型。
![]()
![]()
QQ 浏览器搜索语义团队语料的收集的标准主要有以下三个:规模大、质量高和覆盖广。QQ 浏览器搜索场景下,涉及到的 Document 语料非常丰富,包括企鹅号、小说、各类百科、新闻、社区问答等内容。最终我们得到了近 1TB 数据,并在此基础上完成了数据清洗与低质过滤。
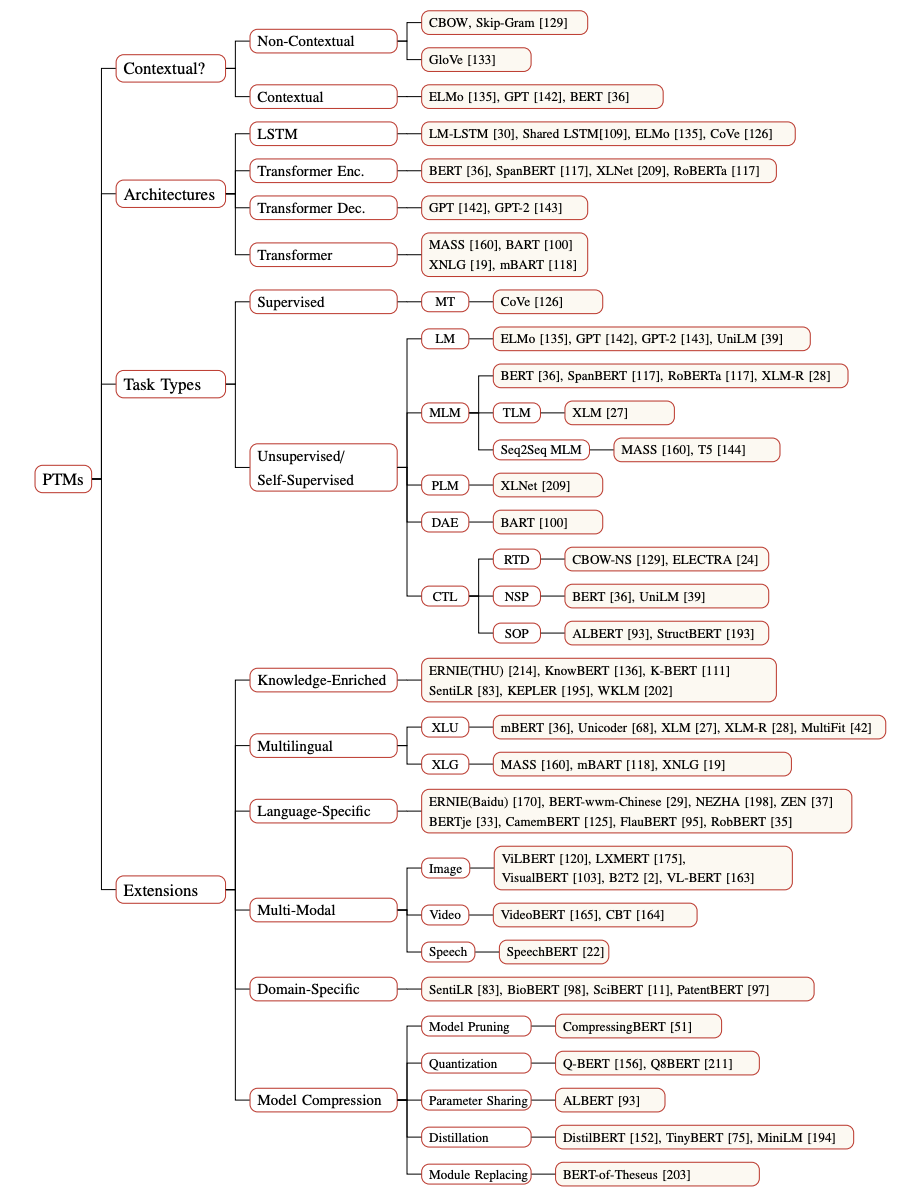
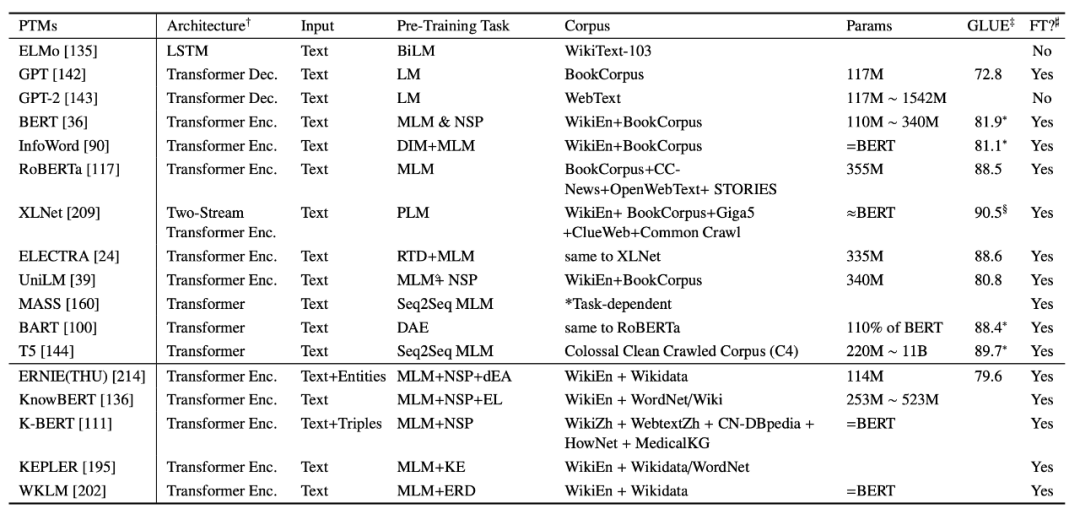
Pre-trained Models(PTMs)可以从 4 个方面 Representation Types、Architectures、Pre-training Task Types、Extensions 来进行分类。
![]()
从
表达信息角度
来看,第一代的预训练模型,比如 Skip-Gram 和 GloVe,通常是一些浅层模型, 用来学习一个比较不错的 word embeddings,尽管包含了一些语义知识,但通常也是上下文无关的,也就没有办法进一步捕捉更高级的概念。第二代的预训练模型,比如 CoVe、ELMo、OpenAI GPT 和 BERT 则可以捕捉到上下文信息。
![]()
从
预训练任务
来看:可以分为监督学习(Supervised learning)、无监督学习(Unsupervised learning)和自监督学习(Self-Supervised learning)。
这里包括了最常见的 NLP 无监督任务语言模型(Language Modeling, LM),以及由 Taylor 提出的掩码语言模型(Masked language modeling, MLM),之后 Devlin 把 MLM 进一步应用到预训练模型中来克服 LM 的缺陷(只有单向)。但是 MLM 的方式也同样带来了另一个问题,即预训练阶段与微调阶段存在一个 mismatch。排列语言模型(Permuted Language Modeling, PLM)应用而生,进一步解决了 MLM 遗留下来的 mismatch 问题。
其他任务:降噪自编码器(Denoising autoencoder, DAE)通过破坏部分输入信号,之后通过模型恢复原始的输入;还有对比学习(Contrastive Learning, CTL) ,其中包含了 NSP、SOP、RTD 等任务。
在摩天上,采用了更符合搜索特色的预训练模型,预训练阶段任务分为两个:一是
MLM
,另一个是
搜索点击曝光任务
。两个预训练任务运用 Multi-Task 的方式同时训练,
通过衡量任务的不确定性(Uncertainty)去表示两个任务的 loss 权重
。
![]()
在预训练任务 MLM 上。扩展了
Whole Word Mask(WWM)为 Phrase + 词级别结合
的 Mask 方案,迫使模型去通过更长的上下文信息去预测被 Mask 的连续字符,而不仅仅是根据词或短语片段中的字共现信息去完成预测。
另一方面,BERT 存在预训练任务与下游微调任务时不一致的问题,即预训练阶段的 [MASK]token 在下游微调中并不出现。为缓解这个问题,BERT 原始论文中对需要 Mask 的 token 按照 8:1:1 的比例替换为 [MASK],随机词,保留。
针对这个问题,我们进行了多种不同方案的实验,目的是加强预训练与微调阶段的一致性,比如
按照全随机词替换的方式、以一定概率分布的随机词、近义词替换
等。同时实验也证明以一定概率分布的近义词替换的效果更好。
![]()
在搜索点击曝光任务上,QQ 浏览器搜索语义团队利用自有海量的点击曝光日志构建了
搜索点击曝光任务
来辅助训练。这样保证可以进一步提高下游句对任务的效果。另一方面也是一种隐式的 DAPT 方案,进一步保证预训练模型可以更加适应自有搜索业务场景。
早期 RNN 模型,后一时刻的输入依赖前一时刻的输出,这样的结构天然捕捉了自然语言中 term 的先后顺序。而自然语言中的序列信息通常又是非常关键的。对于 Transformer block 计算的组件,为了引入不同位置 Token 的信息,选择在输入层引入位置信息的 Embedding,从而保证了 Attention 组件可以捕捉自然语言语序信息。
在探究 Transformer 位置信息的引入方式上可以大体分成两种,第一种是
绝对位置编码
,第二种是
相对位置编码
。
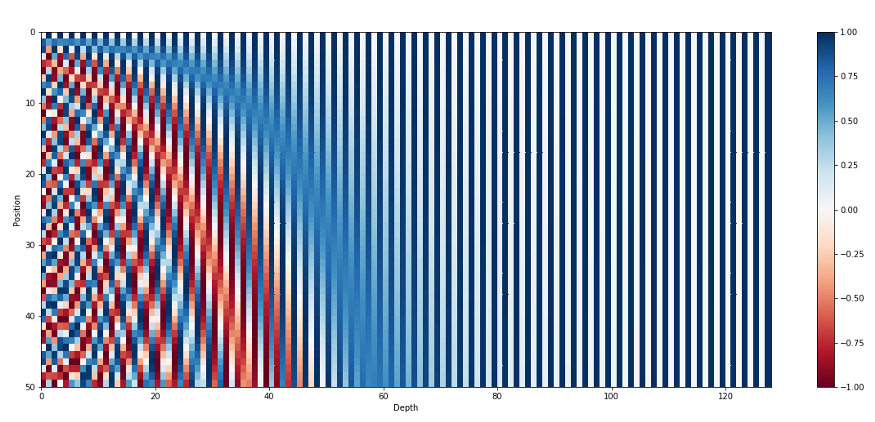
绝对位置编码是一种比较常见的位置编码方案,比如 BERT、RoBERTa、AlBERT、ERNIE 等均是采用这种编码方案。这种编码方案的优势是直接、朴素,即每一个绝对位置表达为一个特定的 Embedding 表示,这种 Embedding 表示的形式又可以细分为可训练的或者函数式的。
其中可训练的绝对位置 Embedding 随着模型训练而得到更新,函数式的绝对位置则是 Attention is all you need 中提出 Sinusoidal 位置编码。
![]()
我们对以上两种绝对位置编码方案进行实验。
预训练数据量足够大的时候,可学习的位置编码 Embedding 会取得更好的实验结果;相反,Sinusoidal 位置编码方案效果会相对好一些
。另外 Sinusoidal 编码方案在对于超过预训练时指定的最大长度时候,会有
更好的外延性
。
整体来看绝对位置编码的方案,不管是可学习的位置编码方案还是 Sinusoidal 位置编码方案都可以完成对位置信息的编码这个任务。
同时这里延伸出另一个问题,即原生的绝对位置编码信息是否隐含了相对位置编码信息。要解答这个问题,可以关注 Attention 模块是如何应用位置编码信息的:
![]()
![]()
这里对 QK 进行展开,一共有 4 项。其中第 1 项不包含位置信息,第 2、3 项是位置信息和 token 信息交互,也不包含位置信息,只有第 4 项存在两个绝对位置信息的交互。那么如果模型能通过绝对位置编码信息间接捕捉到相对位置信息基本上只可能在这。
仔细观察第 4 项,如果去掉中间的两个参数矩阵,单独看两个位置编码的乘法(以 Sinusoidal 的表示方法为例)只和两个位置的相对差值有关,所以是包含了相对位置信息的。但是第 4 项中有两个不可省略的参数矩阵,在经过这两个参数矩阵的映射,是否还包含相对位置信息?从理论上如果两个映射矩阵经过学习,只有在相乘结果刚好是单位矩阵 E 的情况下,才会隐含着包含相对位置信息。
同时,从自然语言的特点去理解,更多的时候关注的是 term 和 term 之间的相对位置,而不是绝对位置。比如短文本:北京到深圳,北京、深圳的相对位置要比绝对位置蕴含更多的语义知识,所以摩天考虑通过更加直接的方案引入相对位置编码。
结合当前 NEZHA、XLNET、T5、DeBERTa 等相当位置编码方案,
提出了一种相对位置编码方案
,更敏感捕捉短文本位置信息契合搜索场景。在实验中发现,在使用这种相对位置编码方案之后,预训练模型的
PPL 在相同配置下可以压的更低
,同时在下游多个任务上也均有不同程度的提升(
百分位 1 个点
)。
BERT 家族针对超长的文本的处理一直是一个研究方向。其中也有很多基于不同角度的解决方案,比如 Transformer-XL、稀疏注意力机制、层次分解位置编码等。
对于 BERT、RoBERTa、ERNIE 等最多能处理 512 个 token 的问题。算法上的原因是在预训练的时候使用了可学习的绝对位置编码方案,所以最多只能处理 512 个 token。在工程上,Attention block 的计算时间复杂度和句子长度成平方关系,这导致了在资源相对受限的情况下,预训练模型训练过程中很难承受非常大的句子长度。
针对第一个问题,上文提到的相对位置编码方案可以比较好地解决。
针对第二个问题,我们引入了
两阶段的训练方式
,即第一阶段以 max_seq_len=128 的配置完成第一阶段的预训练。第二阶段以一阶段产出模型热启动,之后以 max_seq_len=512 的配置完成第二阶段的预训练,进一步压低 PPL,并产出最终模型。这种方案可以在训练资源相对受限的情况下,尽可能的兼顾长文本训练效率与效果。
通过第二阶段训练,模型效果在下游任务上有
千分位
的效果提升。另外对于长句任务,收敛性得到比较大的改善。
![]()
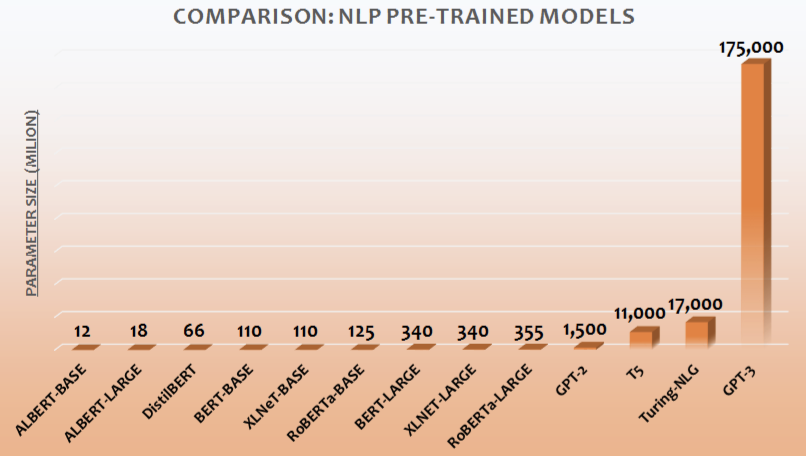
从 18 年 BERT 论文发表至今,预训练模型的效果不断的被更大的模型持续刷新,且目前还未看到天花板。通常一个预训练模型需要几十张 V100/A100 显卡,不过随着预训练模型参数量的不断扩大,Google、Facebook、Nvidia 等企业更是先后用上千张 GPU 卡训练了百亿、千亿参数的 GPT、BERT 模型。在中文预训练模型上也不断有百亿、千亿参数量的预训练模型被发布。这些不断向我们揭示了大规模预训练的成功,以及算力的重要性。
![]()
QQ 浏览器搜索语义团队在基础建设方面搭建了百张卡的大规模训练集群用于训练预训练模型。采用基于 Horovod 的多机多卡并行方案,同时为了进一步提搞训练效率,使用了
混合精度计算、梯度聚集、重计算
等算法加速计算、节省显存。
这里需要特别指出,梯度聚集算法相当于在训练过程中引入了超大的 batch_size,甚至在模型调研中曾一度使用了 64k~128k 的超大 batch_size。为保证模型的收敛,我们借鉴了
LAMB 算法
,并在此基础上引入
梯度正则
进一步保证优化器更关注梯度的方向,而不是梯度的大小;另一方面对
动量和冲量进行修偏
,保证模型在迭代初期的收敛。
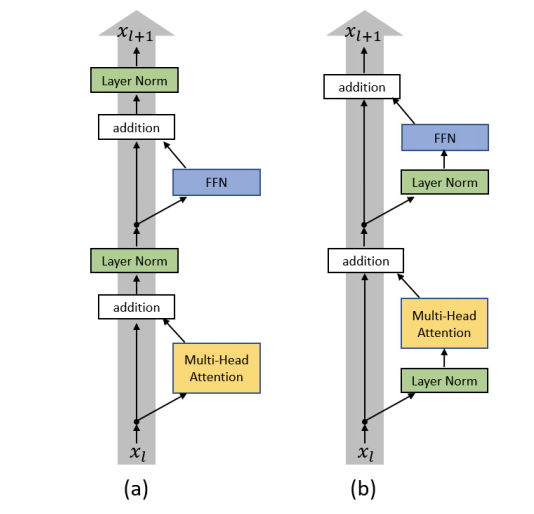
另一方面,摩天大模型升级了 Post-LN 为
Pre-LN
提升预训练模型效果、并进一步保证模型收敛。
![]()
QQ 浏览器搜索团队以 QQ 浏览器为主要阵地,依托腾讯内容生态,致力于打造年轻人爱用、爱玩的浏览器产品。用户在浏览器搜索内可享受到文章、图片、小说、长短视频、便捷服务等众多形态的搜索体验。通过用户研究驱动产品创新,拉动用户增长,提升搜索商业变现能力,使浏览器搜索成为新一代搜索引擎的代表。在搜索算法方面,以 NLP、深度学习、富媒体内容理解、知识图谱等技术为基础,建设内容处理、Query 理解、相关性计算模型、搜索推荐、搜索增长等技术方向,吸收业界先进的技术成果,打造更优秀的搜索体验。在搜索工程方面,建设搜索技术中台工业化系统,打磨高并发、高可用、低延时的百亿级检索系统,并为腾讯 PCG 各个内容业务的搜索场景提供基础的搜索引擎服务;当前服务已经支持 QQ 浏览器,QQ 看点,快报,腾讯视频,腾讯新闻,腾讯微视等 PCG 重要产品线。
[1]Pre-trained Models for Natural Language Processing: A Survey
[2]Don’t Stop Pretraining: Adapt Language Models to Domains and Tasks
[3]LARGE BATCH OPTIMIZATION FOR DEEP LEARNING: TRAINING BERT IN 76 MINUTES
[4]TENER: Adapting Transformer Encoder for Named Entity Recognition
[5]RoBERTa: A Robustly Optimized BERT Pretraining Approach
[6]Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
[7]Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics
[8]BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
[9]Attention is All You Need
[10]Self-Attention with Relative Position Representations
[11]Revisiting Pre-Trained Models for Chinese Natural Language Processing
[12]SpanBERT: Improving Pre-training by Representing and Predicting Spans
[13]Rethinking Positional Encoding in Language Pre-training
[14]NEZHA: Neural Contextualized Representation for Chinese Language Understanding
[15]DeBERTa: Decoding-enhanced BERT with Disentangled Attention
[16]Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
[17]On Layer Normalization in the Transformer Architecture
WAIC AI开发者论坛:后深度学习的AI时代
7月8日—10日,AI 开发者论坛将通过三大核心模块:
AI开发者论坛
、
WAIC· 开发者黑客松
和
WAIC· 云帆奖
展示本年度人工智能领域最前沿的研究方向和技术成果。
本次论坛主题涵盖大规模语言智能、SysML(机器学习系统)、多模态机器学习及大规模自动生成技术、RISC-V技术及生态、AI 原生计算机系统、量子人工智能、GPGPU等热门话题,满足 AI 开发者多层次的学习需求。
识别下方二维码,立即报名。
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com