学界 | 一文详解ICLR 2019微软亚洲研究院6篇入选论文
编者按:ICLR 2019 于5月6日至9日在美国新奥尔良举行,本届投稿比去年增长了近60%,共收到1591篇,录取率为31.7%。由微软研究院与蒙特利尔大学 MILA 研究所合作的论文《Ordered Neurons: Integrating Tree Structures into Recurrent Neural Networks》获得了最佳论文奖。来自微软亚洲研究院的6篇论文入选了本届ICLR,内容涵盖多智能体的对偶学习、自然语言生成模型训练中的表征退化问题、基于知识蒸馏的多语言神经机器翻译、多视图立体场景重建等。本文将对这些工作进行介绍,感兴趣的读者可以在“阅读原文”中下载论文。
诊断和强化VAE模型
Diagnosing and Enhancing VAE Models
Bin Dai, David Wipf
论文地址:https://openreview.net/forum?id=B1e0X3C9tQ
变分自编码器(VAE)是当前比较流行的生成模型之一,但是生成质量相对较差,编码器和解码器的高斯假设被普遍认为是其生成质量不佳的原因之一。在这篇工作中,我们细致地分析了VAE的目标函数的性质,得到了如下结论:
VAE编码器和解码器的高斯假设并不影响其全局最优解,使用其它更复杂的形式并不能得到更好的全局最优解;
在达到全局最优解的情况下,VAE并不一定能模拟训练数据的概率分布。具体来说,当数据所在流形维度(r)等于其所处环境空间的维度(d)时,VAE的全局最优解可以得到训练数据的概率分布。但是当r小于d时,VAE的全局最优解并不能得到训练数据的概率分布。
考虑到实际的数据集是被束缚在环境空间的低维流形上,也就是r<d,所以任何形式的VAE也就没有能力学到数据的真实分布,这一点与编码器、解码器的具体形式无关。
尽管如此,我们还是可以得到一般情形下VAE全局最优解的性质,包括:
VAE可以学到数据所在的流形,也就是说,任意一个来自流形的数据通过VAE之后都将得到完美的重建;
如果VAE的隐空间维度(k)足够的话,也就是k>r,VAE将会使用r个隐空间维度来拟合数据流形,而用标准高斯噪声填充另其余的k-r个维度。
虽然VAE可以学到数据流形,但它学到的流形内的具体分布和真实分布是不同的。在实验中体现为VAE可以很好地重建训练数据,却不能很好地生成新的样本。
根据以上的理论分析,我们提出了双步VAE:我们用第一个VAE来学习流形位置,用第二个VAE来学习流形内的具体分布。具体来说,第一个VAE将训练数据转化为隐空间内的某种分布,该分布占据整个隐空间而非在隐空间的低维流形上。我们用第二个VAE来学习该隐空间内的分布,因为隐变量占据整个隐空间维度,所以根据我们的理论,第二个VAE可以学到第一个VAE隐空间内的分布。
双步VAE显著提高了普通VAE的生成效果,首次得到了质量(在FID指标上)可以和GAN相当的生成结果。我们也从实验上进行了验证。双步VAE 代码可在GitHub上找到:https://github.com/daib13/TwoStageVAE
DPSNet: 端到端的深度平面扫描网络
DPSNet: End-to-end Deep Plane Sweep Stereo
Sunghoon Im, Hae-Gon Jeon, Stephen Lin, In Kweon
论文地址:https://openreview.net/forum?id=ryeYHi0ctQ
多视角立体重建(Multi-view Stereo)是计算机视觉中的一个经典问题,具有十分重要的地位,在三维映射、物体建模以及自动驾驶导航等领域具有很高的应用价值。尽管目前基于深度卷积神经网络的方法已经在这一问题上展现了一定的潜力,但在如何针对多视角立体重建问题设计神经网络结构上,仍有很大的提升空间。
针对这一问题,本文提出了一种新的深度平面扫描网络架构(DPSNet),用于从多视角图片序列中重建场景的深度信息。受到传统的基于几何算法重构深度信息的思想启发,DSPNet采用平面扫描的思想对场景深度进行建模。这一过程包括以下三步:
(1)从多视角图像中提取多尺度深度特征,并基于平面扫描算法构建场景三维代价体素。构建的三维代价体素表达了三维场景中同一点在不同视角图片下的像素局部相似性。
(2)基于上下文相关信息聚合对三维代价体素进行修正和去噪,以获得更准确的多视角对应关系的估计。
(3)由三维代价体素对场景深度进行回归估计,生成最终结果。
实验结果表明,DSPNet对于无材质的均匀区域以及场景中不同物体的边界区域均能实现较好的重建,在不同类型的场景下均取得了目前最优的场景深度重建结果。

RELU神经网络正伸缩不变空间的随机梯度下降法
g-SGD: Optimizing RELU Neural Networks in Its Positively Scale-Invariant Space
Qi Meng, Shuxin Zheng, Huishuai Zhang, Wei Chen, Qiwei Ye, Zhi-Ming Ma, Nenghai Yu, Tie-Yan Liu
论文地址:https://openreview.net/forum?id=SyxfEn09Y7
ReLU神经网络具有正伸缩不变性,即一个隐节点的所有入边乘以一个正常数c,同时所有出边除以一个正常数c,ReLU神经网络的输出值不变。然而,ReLU神经网络的参数空间不是正伸缩不变的,这使得在神经网络参数空间的优化算法并不具有正伸缩不变性,这会导致优化过程对参数的尺度是敏感的。因此一个自然的问题是:是否能存在一个可以充分表达ReLU神经网络的正伸缩不变空间?本文通过对神经网络路径的研究找到了ReLU神经网络的正伸缩不变空间:g-空间,并在g-空间中设计了优化算法g-SGD。
下面首先介绍神经网络的路径(path)。将ReLU神经网络看做一个有向无环图,一条路径p即为输入节点至输出节点的一条通路,路径的值v(p) 被定义为其所经过的参数的乘积。ReLU神经网络的第k维输出可以表示为:
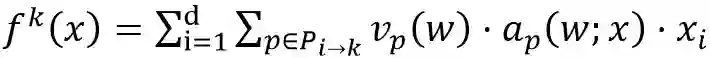
其中P_(i→k)表示连接第i个输入节以及第k个输出节点的所有路径的集合;a_p (w;x)取值为1或0,分别代表该路径的值在经过多层激活函数作用后是否流入输出。我们将所有神经网络正伸缩变换的集合记为g,用路径的值来表达神经网络的好处是路径的值是正伸缩不变的,即
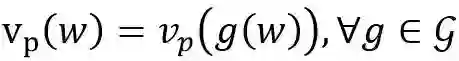
因此路径的值构成的空间也许是我们想要寻找的正伸缩不变空间。
然而,神经网络所有路径值是相关联的(如下图),这意味着所有路径的值不能作为独立的变量进行优化。为了找到一组互不相关的路径,我们用向量来表达路径:
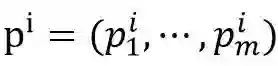
其中p_ j^i取值1或0,分别表示路径p^i是否经过参数w_ j。本文将所有路径向量构成的矩阵称为神经网络的结构矩阵,记为A。我们将基路径定义如下。
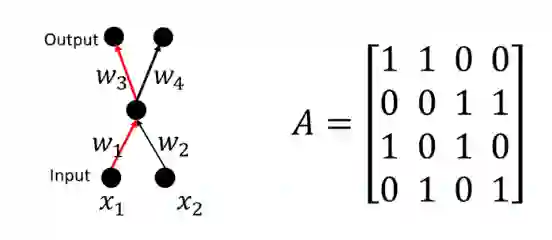
路径v(p^ij)的值等于w_i⋅w_j, 那么路径之间相互关联,例如v(p^24 )=(v(p^14 )⋅v(p^23 ))/v(p^13 ) 。矩阵A为该网络对应的结构矩阵。
定义 1 (基路径): 若路径集合
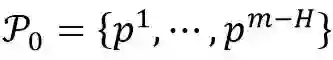
是结构矩阵A的极大线性无关组,那么P_0被称为基路径集合。
根据代数知识可以知道,基路径的值是相互独立的,并且其他路径的值均可以由基路径的值通过乘除计算得到(如上图)。通过对激活状态a_p (w;x)的分析,我们有如下定理。
定理 1: 给定参数为w和w'的两个ReLU神经网络,w~gw'的充要条件是∀p∈P_0, 都有v_p (w)=v_p (w').
根据定理1可得,基路径的值可以充分表达一个ReLU神经网络,并且基路径的值是正伸缩不变的。因此,我们将基路径的值构成的空间定义为ReLU神经网络的G-空间。
定义 1 (G-空间): ReLU神经网络的G-空间定义为
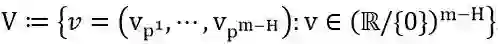
接下来,本文设计了ReLU神经网络G-空间的优化算法:G-SGD。G-SGD的目标是优化以基路径的值为参数的损失函数
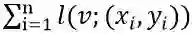
然而,直接计算损失函数对于基路径值的导数是困难的,为了高效地获得基路径的导数,本文设计了Inverse-Chain-Rule方法,利用参数w与基路径v之间的函数关系来获得v的导数。g-SGD的算法流程如下图所示。
对于一个ReLU神经网络,本文首先设计了骨架方法(Skeleton Method)找出网络的基路径。然后,g-SGD算法按照四个步骤迭代地更新网络的基路径值:
(1)神经网络进行后向传播(BP)来获得原参数w的导数;
(2)通过Inverse-Chain-Rule方法,利用w的导数计算出基路径值v的导数;
(3)利用v的导数根据随机梯度下降法更新v的值;
(4)为了能进行下一轮BP,需要将更新后基路径的值投影到参数w上,该投影方法称为Weight-Allocation方法。值得指出的是,g-SGD算法的计算复杂度与BP方法是同阶的。
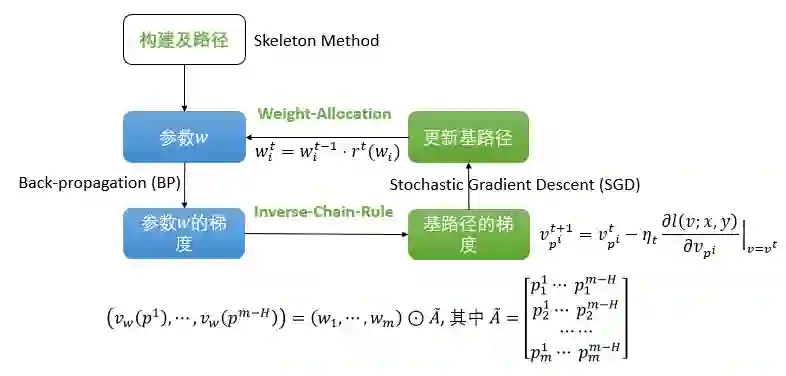
G-SGD算法流程图
最后,本文在图像分类任务上验证了G-SGD算法的有效性。实验选用的模型为深层卷积神经网络PlainNet-34和深层残差神经网络ResNet-34,数据集为CIFAR-10和CIFAR-100。下表展示了G-SGD算法和SGD算法的测试误差。结果表明,G-SGD算法相较于SGD算法可以到达更低的测试误差,体现了在G-空间优化的好处。
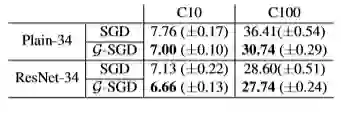
实验结果(CIFAR-10)
多智能体对偶学习
Multi-Agent Dual Learning
Yiren Wang, Yingce Xia, Tianyu He, Fei Tian, Tao Qin, ChengXiang Zhai, Tie-Yan Liu
论文地址:https://openreview.net/forum?id=HyGhN2A5tm
对称性在AI任务中广泛存在,例如,机器翻译中有英语-德语翻译和德语-英语翻译的对称;图像翻译中有照片转换到油画、油画转换到照片的对称;语音处理中有语音到文本(语音识别)和文本到语音(语音合成)的对称。基于这种特性,微软亚洲研究院机器学习组在NIPS 2016提出了一种新的学习范式——对偶学习,已被广泛应用在机器翻译、图像翻译、问答等许多领域。
对偶学习的基本思想,是利用任务的对称属性 (primal-dual),从两个对称的任务空间中获得有效的反馈/正则化,从而加强学习过程。传统对偶学习可以理解为两个智能体(agent)的博弈:一个智能体学习原始任务(prima task)f: X→Y,另一个智能体学习对偶任务(dual task)g:Y→X。在对偶学习中,我们首先将x∈X通过第一个智能体f映射为 y ̂ =f(x)∈Y,然后再利用第二个智能体g重构为x ̂ =g(y ̂ )∈X。x和x ̂ 之间的失真度Δ_x (x,x ̂ )作为反馈信号,协助引导和加强学习过程。
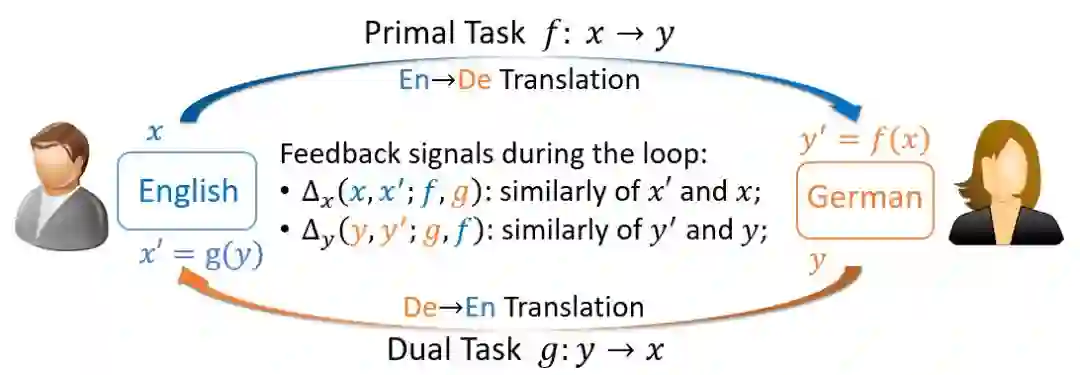
在这种双智能体的系统中,两个智能体f和g需要进行互相评价。具体而言,反向智能体g需要评价由正向智能体f生成的y ̂ =f(x),并为正向智能体提供反馈信号Δ_x (x,g(y ̂ )),反之亦然。在这个过程中,智能体的评价质量对引导学习过程而言非常重要。我们在现有对偶学习框架的基础上,引入多智能体共同作用于学习系统。同一个任务方向的不同智能体之间,有相似的模型容量和良好的多样性,它们的共同作用可以为学习过程提供更加可靠和鲁棒的反馈信号,从而帮助系统获得更好的性能。
我们将这种方法称为多智能体对偶学习(Multi-Agent Dual Learning, 缩写为MADL)。

MADL框架
考虑建立在两个空间X和Y之间的对偶任务,我们最终的目标是学习两个智能体,学习原始任务的f_0: X→Y,和学习对偶任务的g_0:Y→X。传统的对偶学习优化损失函数:
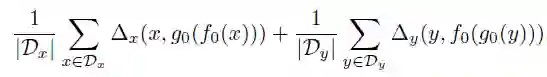
在多智能体对偶学习框架中,我们引入多对智能体f_i:X→Y,g_i:Y→X,(i=1,2,…N-1),其中每一个智能体都可由独立学习任务场景得到。在MADL中,多智能体共同作用,通过
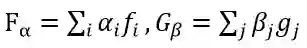
提供对偶反馈信号,帮助引导和增强我们最终的最终目标——f_0和g_0的学习。MADL的损失函数表达为:
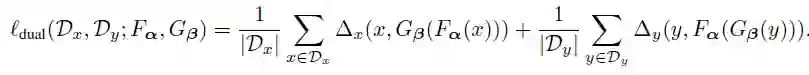
MADL在神经机器翻译中的应用
在机器翻译中,我们利用线下采样和重要性采样的方法估计梯度,具体算法如下:

我们在多个广泛应用的翻译任务上进行了实验验证,包括
IWSLT 2014 英德互译任务 (IWSLT2014,153K训练数据)
WMT 2014 英德互译任务(WMT2014 En-De,4.5M训练数据)
WMT 2016 无监督英德互译任务 (WMT2016 unsupervised En-De,仅无标数据)
其中,在WMT2014上,仅利用有标数据和增加无标数据的两个场景中,我们取得了相同环境配置下的最好性能;在WMT2016无监督翻译任务上,我们在英德/德英方向分别达到19.26/23.85 BLEU,超越了之前所有纯NMT系统。
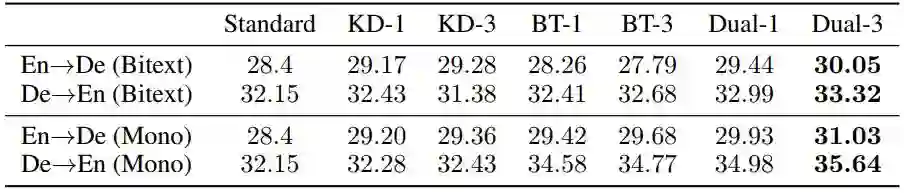
WMT 14 En-De
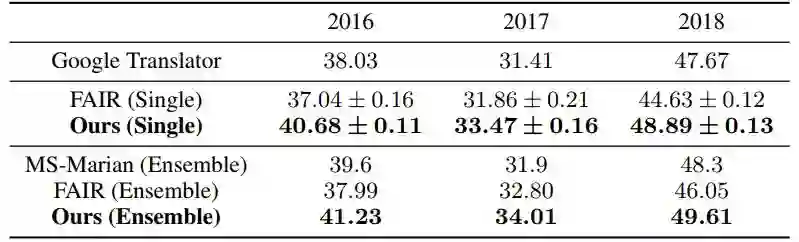
WMT {16, 17, 18} En-De

WMT 16 Unsupervised En-De
MADL在图像翻译中的应用
在图像翻译中,我们将MADL于CycleGAN结合,优化目标函数如下:
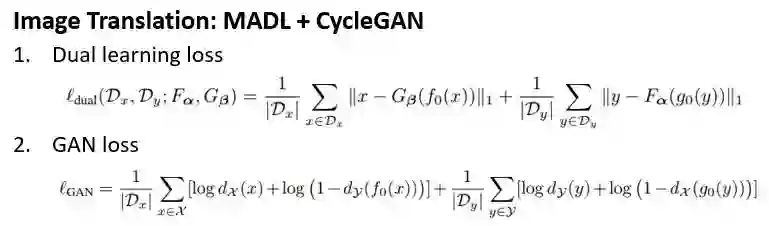
我们在照片和油画(梵高,塞尚,莫奈,浮世绘)的互相翻译,街景和标签互译两个任务上进行试验,都获得更好的翻译质量。

Case study (梵高—>照片)
基于知识蒸馏的多语言神经机器翻译
Multilingual Neural Machine Translation with Knowledge Distillation
Xu Tan, Yi Ren, Di He, Tao Qin, Zhou Zhao, Tie-Yan Liu
论文地址:https://openreview.net/forum?id=S1gUsoR9YX
代码地址: https://github.com/RayeRen/multilingual-kd-pytorch
多语言翻译模型(一个模型同时翻译多个语言对),由于能减少离线训练多个模型的代价,以及减少线上服务消耗,正受到越来越多的关注。当多语言模型同时处理几十、上百种语言对时,翻译精度通常低于单语言翻译模型(一个模型只翻译一个语言对)。基于这个现象,我们提出通过知识蒸馏的方法将性能较优的单语言翻译模型的知识转移到多语言模型中来,以提升多语言翻译模型的精度。
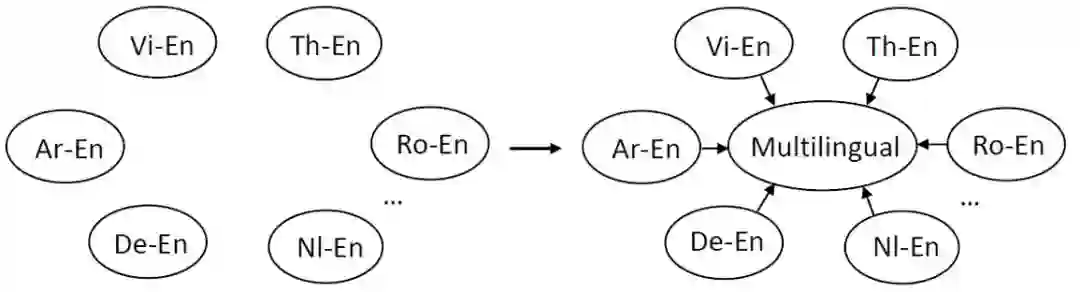
我们将这个场景下的知识蒸馏表示成多个单语言模型的老师以及一个多语言模型的学生,如上图所示。我们通过知识蒸馏将每个单语模型的知识蒸馏到多语言模型中,其中每个语言的知识蒸馏过程如下所示:
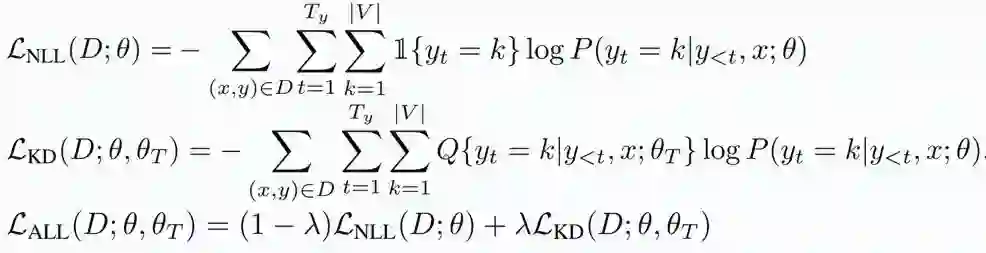
其中L_NLL(D; θ)代表在真实训练集上的对数似然损失函数,L_KD(D; θ, θ_T )代表知识蒸馏的损失函数,最终的损失函数L_ALL(D; θ, θ_T )是两者的加权平均。D代表训练数据集,θ代表学生模型的参数,θ _T代表老师模型的参数,T_y代表目标句子的长度,|V|代表目标语词表大小,Q代表老师模型的概率分布。
在多语言的知识蒸馏过程中,我们还提出了两种蒸馏策略以保证算法的性能:选择性蒸馏和Top-K蒸馏。
选择性蒸馏:当多语言翻译模型(学生)的精度超过某个单语言模型(老师)一定阈值时,我们去掉这个语言对应的蒸馏损失函数,在这个语言上只使用原来的对数似然损失函数。这样能防止差的老师把学生教坏。
Top-K蒸馏:在蒸馏过程需要将老师输出的概率分布放入GPU显存计算蒸馏损失,而一般翻译模型的词表大小在几万的量级,这样会极大的增大GPU显存以及计算开销。因此,我们只把老师输出的概率分布中最大的K个概率重新归一化成一个新的概率分布加载到GPU中,这样既节省显存和计算开销,同时实验显示不损失精度。
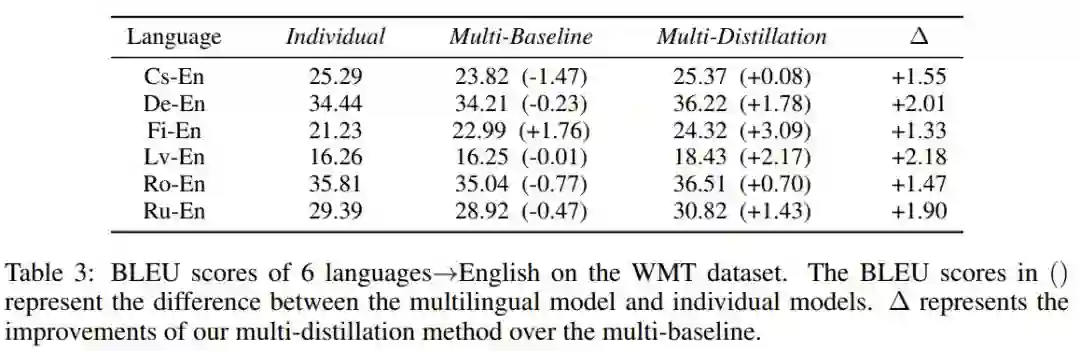
我们在IWSLT/WMT/TED Talks三个多语言翻译数据集上验证方法的效果。下表是在WMT数据集上的结果,传统的多语言的基线方法(Multi-Baseline)相比单语言模型(Individual)有一定程度的性能损失,而我们的方法(Multi-Distillation)相比单语言模型都有性能提升,比多语言的基线方法有1-2个BLEU分的提升,显示出我们方法的有效性。更多数据集的实验结果以及关于方法的分析,请查阅论文。
自然语言生成模型训练中的表达退化问题
Representation Degeneration Problem in Training Natural Language Generation Models
Jun Gao, Di He, Xu Tan, Tao Qin, Liwei Wang, Tie-Yan Liu
论文地址:https://openreview.net/forum?id=SkEYojRqtm
近些年来,基于神经网络的算法在自然语言生成任务中取得了重大进展,其中包括语言模型、机器翻译、对话系统等一系列领域。主要模型框架是在给定的上下文和其他语义信息基础上预测下一个单词。一种标准的方法是利用深度神经网络将输入编码为一个固定大小的向量,我们称之为隐状态,然后将其乘以单词嵌入表达矩阵。输出值进一步作为softmax函数的输入以给出下一个单词在所有候选词上的分布。在研究这些基于神经网络的模型时,我们观察到一些有趣且令人惊讶的现象。我们发现,当我们通过最大化似然函数对自然语言生成任务的神经网络进行优化时,尤其是在训练数据集较大的情况下,大部分学习到的单词嵌入词向量倾向于退化并且分布到一个狭窄的锥体当中。
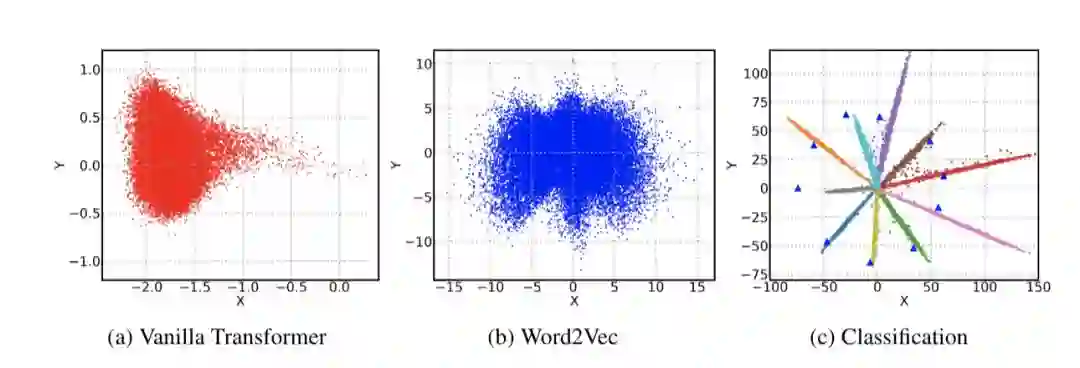
这种现象与其他分类任务有很大不同,并且会显著降低模型的表达能力。从softmax输出层的角度看,这些参数需要有多样化的分布,才能达到更大的分类间距(margin);从嵌入词向量的角度,这些参数应该有足够的能力来刻画自然语言中巨大的语义变化。然而,根据我们的实验观测,虽然模型的复杂性(例如模型参数维度)提供了足够的表达能力,实际学习到的模型却只有有限的表达能力。
本文从理论上分析了该问题产生的条件和原因,并且提出通过增大任意两个词向量之间cosine夹角的方法来解决该问题。
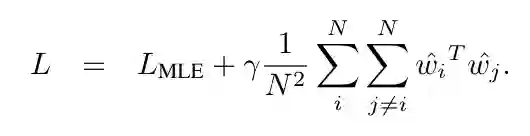
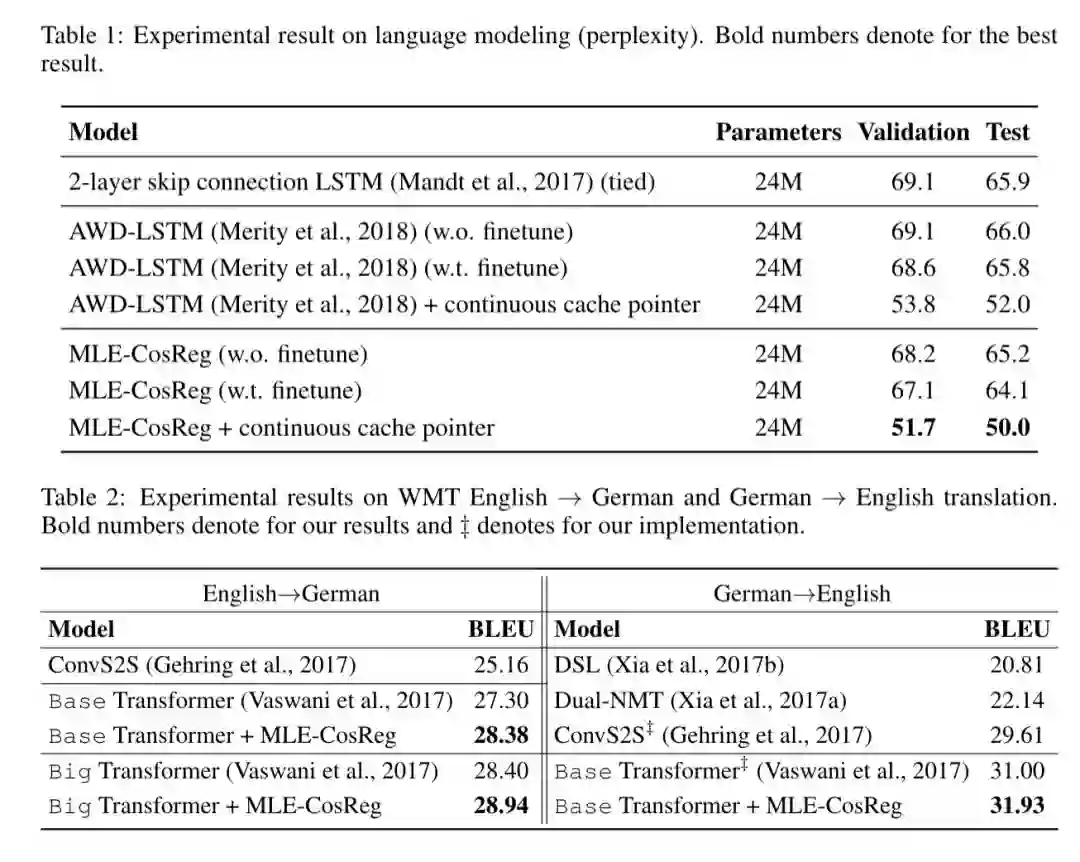
基于WMT-2014 En-De/De-En 机器翻译以及WikiText-2 语言模型的实验结果表明,我们的方法可以很大程度上缓解表达退化问题,并获得比baseline更好的性能,有效地提高模型的表达能力。

点击文末阅读原文可以打包下载这六篇论文

