WWW 2019微软亚洲研究院6篇入选论文一览

编者按:WWW 2019(The Web Conference)于5月13-17日在美国旧金山召开,今年会议共收到投稿1247篇,录取225篇,录取率为18%。微软亚洲研究院共有6篇论文入选,内容包括推荐系统知识图谱中的多任务特征学习、知识图卷积网络、中文分词与中文实体识别、云服务故障预测和诊断、深度学习在移动端APP上的应用情况等,感兴趣的读者可以在“阅读原文”中下载论文。
在信息爆炸时代,推荐系统的目标是对用户需求进行建模,为用户推荐其可能感兴趣的物品,如电影、音乐、餐馆等,满足其个性化偏好。由于用户交互数据的稀疏性,传统的协同过滤方法已经不能很好地适应真实的推荐场景,引入更多的辅助信息对提升推荐系统的性能至关重要。
在以下两篇论文中,我们以知识图谱为辅助信息提出了两种不同的模型。知识图谱是一种异构图,每个节点是一个实体,边则表述了实体之间的关系。对于推荐系统而言,如果知识图谱中的实体集合包含了物品集合,知识图谱就提供了物品之间丰富的语义关联。这种关联可以用来辅助推荐系统的决策,提升推荐结果的准确率、多样性和可解释性。
知识图谱增强推荐中的多任务特征学习
Multi-Task Feature Learning for Knowledge Graph Enhanced Recommendation
Hongwei Wang, Fuzheng Zhang, Miao Zhao, Wenjie Li, Xing Xie, Minyi Guo
论文链接:https://arxiv.org/abs/1901.08907
在该论文中,我们将推荐系统和知识图谱建模视为两个分离但是相关的任务,设计了一个多任务学习的框架,利用知识图谱建模任务来辅助推荐系统任务(下图a)。这两个任务之所以相关,是因为推荐系统中的一个物品会和一个或多个知识图谱中的实体相对应,因此,它们在各自的向量空间中的表征应该有相关性。为了表达这种相关性,我们在提出的模型中设计了一个“交叉-压缩”单元,这个单元显式地对物品表征和实体表征的高阶交互进行建模,并自动控制两个任务之间的知识的交叉迁移。
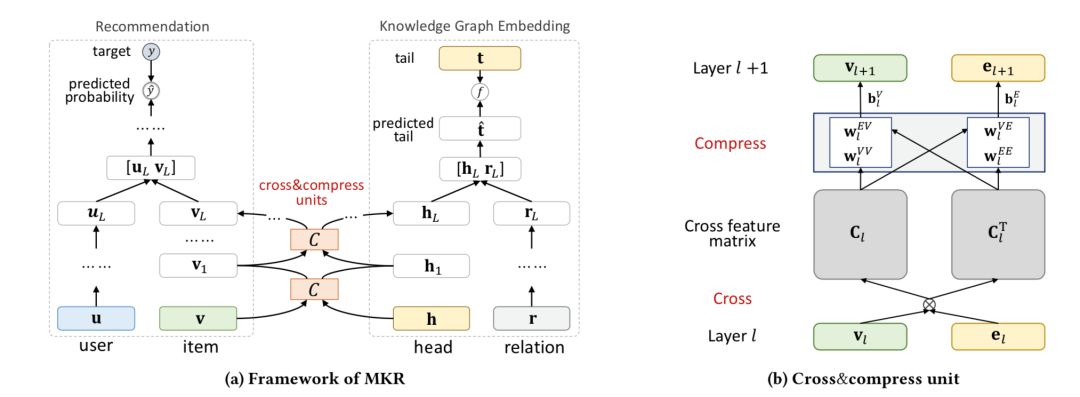
交叉-压缩单元(上图b)首先对输入的物品表征向量和实体表征向量的每一个维度的交互都进行建模,得到一个交叉矩阵及其转置;然后再对交叉矩阵及其转置进行压缩,重新得到物品和实体表征向量。通过交叉-压缩单元,物品向量和实体向量之间得以充分地交互,知识图谱的信息也可以流入推荐系统中,辅助提升其泛化能力。
我们通过理论分析,证明了交叉-压缩单元具有足够的能力来拟合物品向量和实体向量之间的高阶交互。我们也可以证明该框架是多种模型的泛化推广的结果,包括factorization machines、deep&cross network和cross-stitch network。实验结果表明,我们提出的模型在多个真实场景中比对比方法有明显的性能提高,例如,在电影推荐数据集MovieLens-1M中有11.6%的点击率提升,在图书推荐数据集Book-Crossing中有66.4%的召回率提升。另外,实验结果也表明我们的方法在用户-物品交互非常稀疏时也有良好的表现。
推荐系统的知识图卷积网络
Knowledge Graph Convolutional Networks for Recommender Systems
Hongwei Wang, Miao Zhao, Xing Xie, Wenjie Li, Minyi Guo
论文链接:https://arxiv.org/abs/1904.12575
与上面的方法不同,在本文中,我们对知识图谱的建模更加偏向于结构信息。图卷积网络(graph convolutional networks,GCN)是最近提出的一种图表征学习方法,它在学习节点表征时被证明具有优越的性能。本文是GCN在知识图谱建模中的推广。
由于知识图谱是异构图,而GCN只能对普通的同构图进行建模,因此我们需要将知识图谱进行转化。为此,我们提出使用一个“用户-关系评分函数”,在给定一个用户的情况下,将知识图谱中边(即关系)的种类转化成了权值信息。对于转化后的知识图谱,我们首先对每个节点的多跳邻居进行采样(见下图a),得到了固定大小的邻居集合。然后,我们逐层将邻居节点的表征进行加权聚合,并当作该节点在下一轮中的表征(见下图b)。这里的加权系数即为我们在上一步中得到的边的权值信息。经过k层聚合之后,一个节点的最终表征就融合了其最多k跳的邻居节点的信息,这有助于在知识图谱中探索和扩展用户的兴趣。
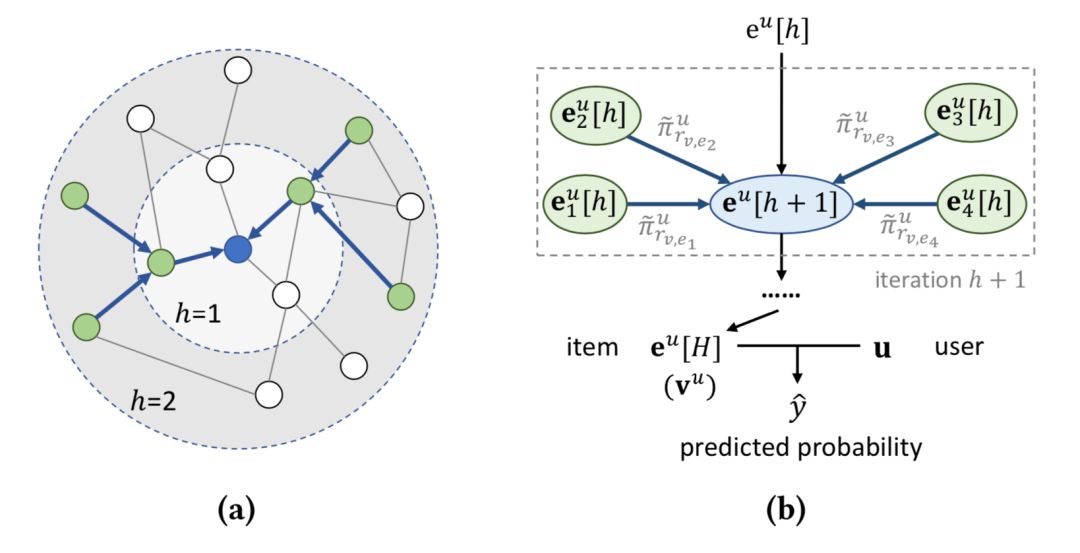
我们在三个真实的推荐系统数据集(MovieLens-20M,Book-Crossing,Last.FM)上进行了实验,结果表明我们的方法取得了优秀的性能表现。例如在点击率预测中,KGCN实现了在三个数据集上的平均4.4%,8.1%和6.2%的提升,在top-k推荐中,KGCN的召回率曲线也均高于对比方法。
结合分词的中文命名实体识别
Neural Chinese Named Entity Recognition via CNN-LSTM-CRF and Joint Training with Word Segmentation
Fangzhao Wu, Junxin Liu, Chuhan Wu, Yongfeng Huang, Xing Xie
论文链接:https://github.com/liujunxin/CNER-IN-WWW19
命名实体识别是指文本中抽取实体的名称并将其分类到特定类别的任务,被广泛应用于实体链接、关系抽取、自动问答等一系列下游任务中。相比英文命令实体识别,中文实体识别存在更大的挑战。首先,中文文本缺少显式的词语分隔符,比如英文中的空格等,因此实体边界的识别更加困难;其次,中文句子的局部和全局上下文信息对于实体识别都非常重要;另外,相比于英文命名实体识别,中文命名实体识别的标注数据更加缺乏。
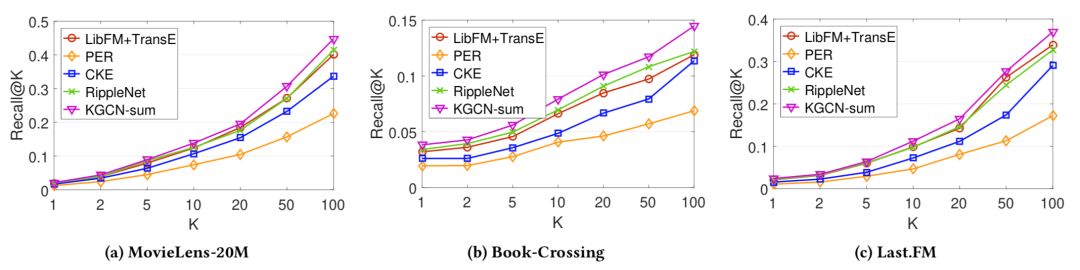
为了解决这些问题,本论文提出了一种结合汉语分词的中文命名实体识别框架(如下图所示),通过联合训练中文命名实体识别模型和汉语分词模型来提升中文命名实体识别模型对中文实体边界的识别能力。同时,本论文提出了一种CNN-LSTM-CRF的中文命名实体识别模型,用来更好地对中文句子的局部和全局上下文信息进行建模。此外,本论文提出了一种基于同类实体替换的自动标注数据构造方法,能够从已有的少量标注数据中构造更多的伪标注样本,显著提升模型的泛化能力。
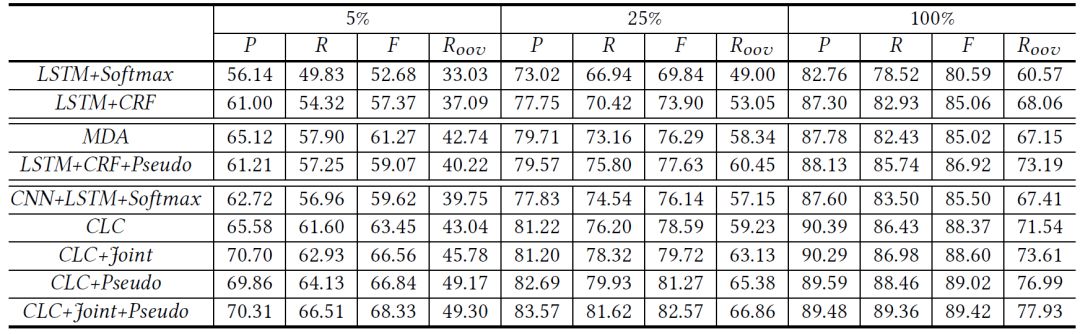
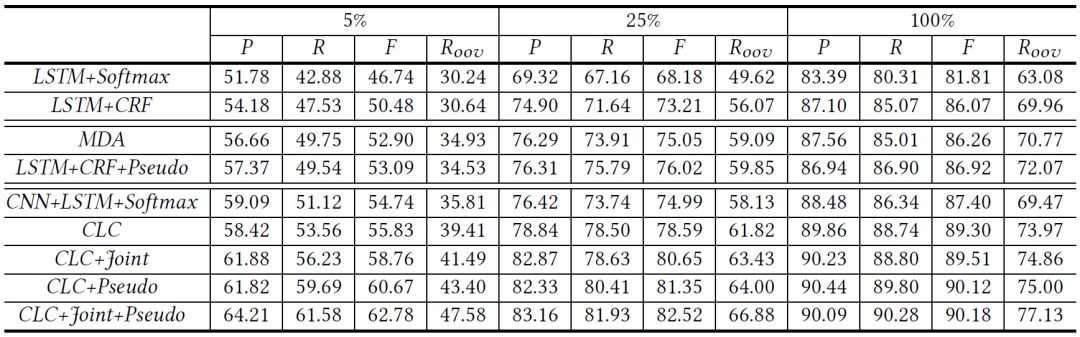
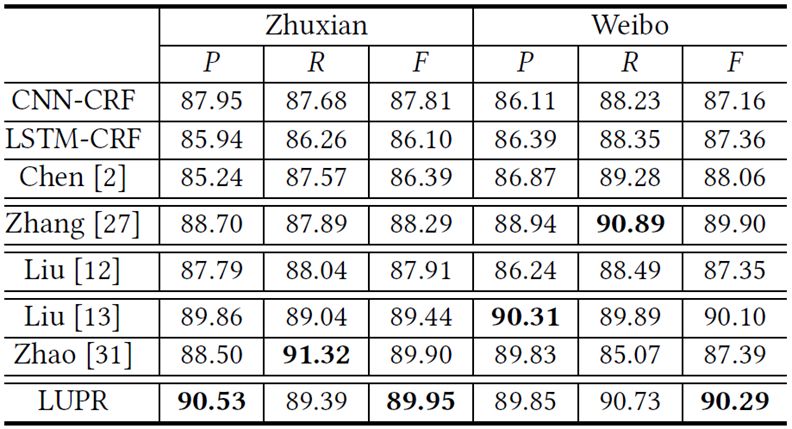
本论文在第三届和第四届SIGHAN中文处理竞赛的命名实体识别数据集上进行了实验。如下表所示,CNN-LSTM-CRF模型在中文命名实体识别任务上的性能要显著优于目前流行的LSTM-CRF模型。同时,结合汉语分词的联合框架可以有效提升中文命名实体识别的效果。此外,本论文提出的伪标注数据构造方法可以显著提升不同中文命名实体识别模型的性能,尤其是在未登录实体(OOV)上的表现,证明这些自动构造的伪标注数据有效提升了模型的泛化能力。
结合词典和无标注数据的中文分词
Neural Chinese Word Segmentation with Lexicon and Unlabeled Data via Posterior Regularization
Junxin Liu, Fangzhao Wu, Chuhan Wu, Yongfeng Huang, Xing Xie
论文链接:https://github.com/liujunxin/CWS-IN-WWW19
近年来,基于神经网络的方法被广泛应用于中文分词,并取得了不错的效果。然而这些方法通常依赖于大量的有标注数据来训练模型,并且很难正确识别那些极少或没有出现在训练数据中的词语。由于词语分布的长尾特征,构造一个能完全并充分覆盖所有词语的数据集是一个非常艰巨的任务。
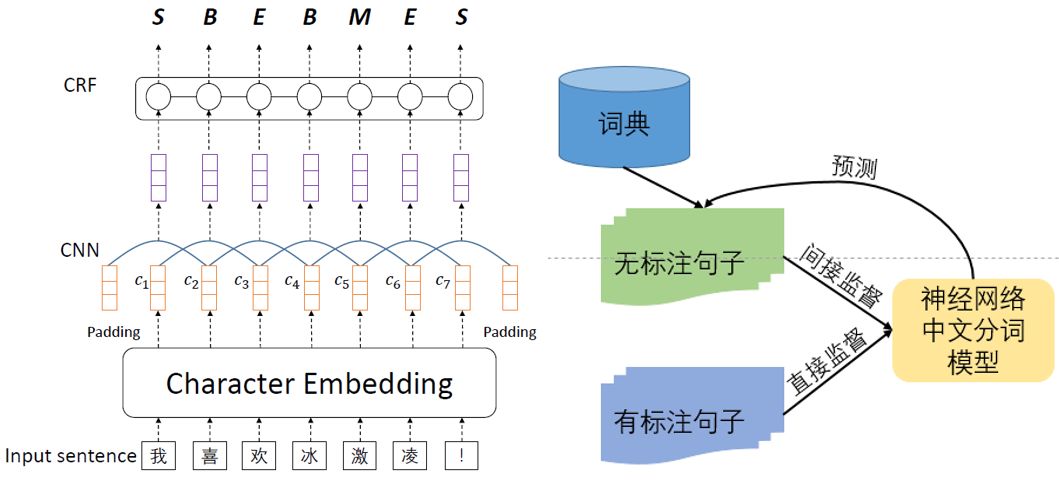
由于存在很多大规模、高质量的汉语词典,并且无标注的汉语句子相对容易获取,本论文提出了一种能充分利用汉语词典和无标注数据的中文分词方法,以降低对标注数据的依赖,提升分词效果。我们提出了一个基于后验正则 (posterior regularization) 算法的框架,能够将中文词典和无标注数据生成间接监督信息并用于模型训练,从而约束中文分词模型的预测空间。我们使用CNN-CRF模型作为基础的神经网络分词模型(如左下图所示),同时利用词典和无标注数据产生的间接监督信息和有标注数据中包含的直接监督信息来训练神经网络分词模型,并通过多次迭代来逐步优化模型的效果。
该论文在第三届SIGHAN中文处理竞赛的两个中文分词任务数据集上进行实验。实验结果(如下表所示)表明,论文提出的方法能够显著地提升中文分词的效果,并降低对标注数据的依赖。
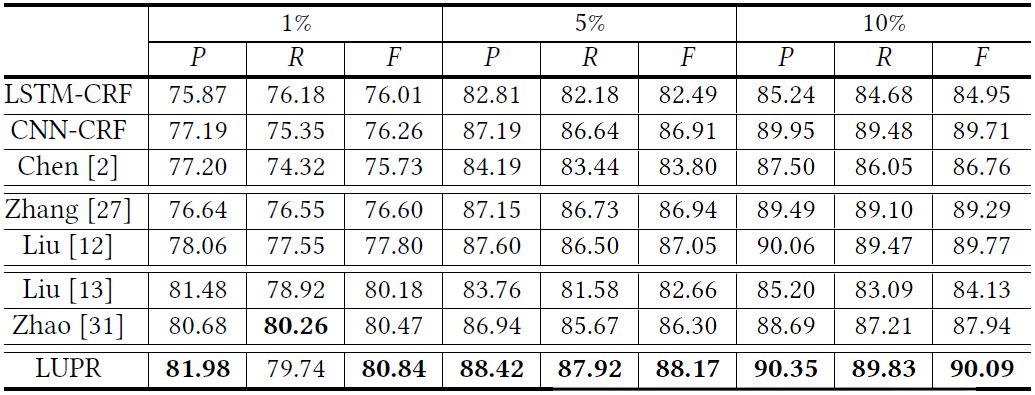
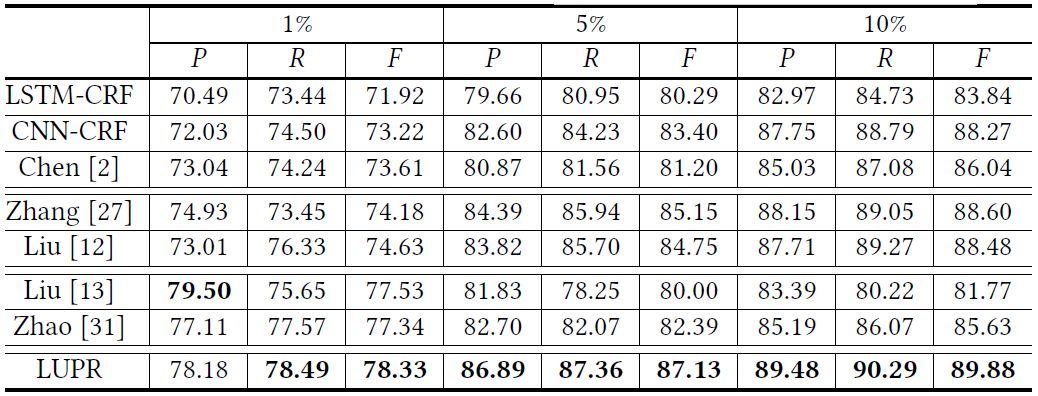
此外,这一方法还可用于中文分词的领域迁移。下表是从新闻领域向小说和微博领域进行迁移的实验结果,通过我们的框架将目标领域的词典的无标注数据融入到模型训练中,可以有效提升中文分词模型的领域迁移性能。
云服务系统的中断预测和诊断
Outage Prediction and Diagnosis for Cloud Service Systems
Yujun Chen, Xian Yang, Qingwei Lin, Hongyu Zhang, Feng Gao, Zhangwei Xu, Yingnong Dang, Dongmei Zhang, Hang Dong, Yong Xu, Hao Li, Yu Kang
论文链接:http://chenjohn.cn/files/2019/www_2019_chen.pdf
在大型云系统中,系统故障会极大地影响系统可用性。为了维护系统的正常运行,在检测到故障时,需要高效的故障管理机制来及时诊断和止损。目前大部分针对大型复杂系统(如数据中心、网格系统和防御系统)的预测和诊断故障的方法只考虑某个单一子系统的行为,而忽略了相关系统的影响。虽然集中研究单一子系统也有利于提升系统的可用性,但对于Azure这样的大型云系统是不够的。
像Azure这样的大型系统包含许多子系统(即服务),每个子系统由许多相互关联的组件和服务组成。同时,服务是组件上层的一个概念。也就是说,整个复杂系统是由若干个服务组成,一个服务又有诸多小的组件构成。每个组件或服务都有自己的监控方式,可以定期收集检查组件运行状态的信号。这些来自组件/服务的信号反映了系统各个方面的健康状态,例如云节点可用资源、节点/数据中心流量、响应延迟、温度和功耗等等。
我们在该论文中提出一种新的方法来解决大型复杂系统的故障预测和诊断问题,关注大型系统中各个组件存在的关联性及其对故障检测与修复的帮助。针对组件和服务关联性问题,我们借助因果分析方法FCI中的条件独立检验确定各个组件或服务收集的时域信号是否存在相关性。通过因果分析时域信号的关联性,将不同层次之间的组件信号和服务信号进行关联性构建,得到组件和服务的关联图。再借助树分类器(XGBoost)利用时域信号特征和相关的组件与服务信息进行故障的预测工作。在实际使用时,我们提出的方法不仅可以在故障预测中取得较好的效果,还能够对组件或服务发生的故障进行诊断,定位最本质的故障信息。
深度学习在移动端app上的应用情况
A First Look at Deep Learning Apps on Smartphones
Mengwei Xu, Jiawei Liu, Yuanqiang Liu, Felix Xiaozhu Lin, Yunxin Liu, Xuanzhe Liu
论文地址:https://arxiv.org/pdf/1812.05448.pdf
代码地址:https://github.com/xumengwei/MobileDL
为弥补深度学习研究和工程实践之间的差距及对深度学习在移动端应用这一新热点的研究空缺,我们对Google Play上16,500个最流行的安卓应用程序进行了首次实证研究,利用静态分析工具揭示了最早期使用深度学习的应用程序是哪些,它们使用深度学习的用途及方式。一方面,这一研究成果描绘了智能手机使用深度学习技术的前景,另一方面,它也敦促开发者对智能手机上部署的深度学习模型进行优化。
我们设计了一个半自动化运行的分析工具来实现研究目标。首先从给定的定安卓应用程序集中识别出使用了深度学习的应用程序,然后用由工具aapt提取manifest 文件并从相应的Google Play网页中获取元信息,用Model Extractor模块从assets文件夹中提取深度学习模型。然而在支离破碎的深度学习框架的生态系统下,深度学习模型大多采用不同的格式,因而Model Extractor对每一种框架都有一个验证器。但许多模型并没有以明文形式存储在apk文件中,对于这种情况,模型提取器尝试对应用程序进行反向工程,并提取可分析的模型。
研究结果表明,深度学习的早期采用者是排名最靠前的应用程序;深度学习多被用作应用程序的核心构建块;针对移动端的深度学习框架正受到越来越多的关注;大多数应用程序使用的深度学习模型缺少明显的优化;移动设备上使用的深度学习模型比预期的要轻量;移动设备上使用的模型未受到很好的保护。
论文下载
下载地址:https://www.msra.cn/wp-content/uploads/2019/05/WWW2019.zip

长按扫码,下载论文
你也许还想看:



感谢你关注“微软研究院AI头条”,我们期待你的留言和投稿,共建交流平台。来稿请寄:msraai@microsoft.com。






