基于LDA的主题模型实践(三)
前面花了两大篇幅讲解LDA的原理:
LDA模型原理
http://mp.weixin.qq.com/s?__biz=MzA4NTIyMjY0Mg==&mid=207386308&idx=1&sn=f2fad036a3813939a38ecee3e65a7928#rd
2)LDA求解方法Gibbus采样
http://mp.weixin.qq.com/s?__biz=MzA4NTIyMjY0Mg==&mid=207482843&idx=1&sn=fc79a3e1c339047fe96d5fb3e25ced2f#rd
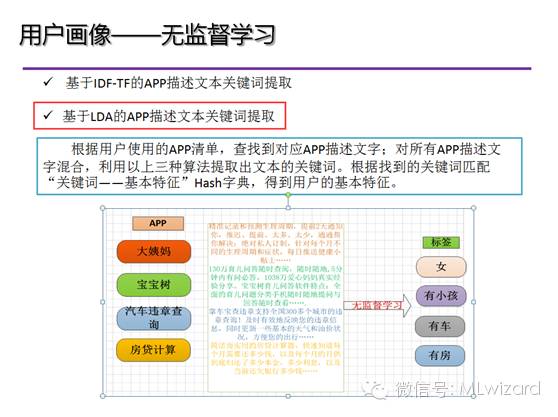
在了解了模型基本原理和求解过程之后,这次我们结合“基于无监督算法的用户画像”来演示LDA算法的实际应用,其主要思路是使用LDA对用户使用APP的描述信息对用户进行聚类,并且给出相应的关键词主题定义。
让我们先回顾一下无监督学习用户画像的思路:
具体用户画像的文章,请参考:
http://mp.weixin.qq.com/s?__biz=MzA4NTIyMjY0Mg==&mid=207159018&idx=1&sn=9ff0aac1d48e2ab10e7479f4e87a20b7#rd
LDA算法的输入输出:
Input:

Parameters:
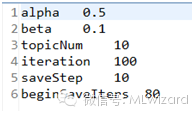
Output:

结合用户手机APP的数据,那么基于LDA无监督学习的用户画像过程如下:
1、输入用户使用APP及描述信息
2、对输入文本进行分词
3、把分好词文本输入LDA模型中聚类
4、输出文本测试结果
对收集到数据清洗去杂处理后,以每行一个用户及app名称和描述存储

把处理好的信息用HanLp分词包用crf方法分词
调整LDA模型参数a,b,主题数,以及迭代次数
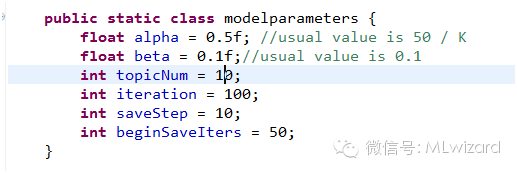
设置完参数,初始化LDA模型
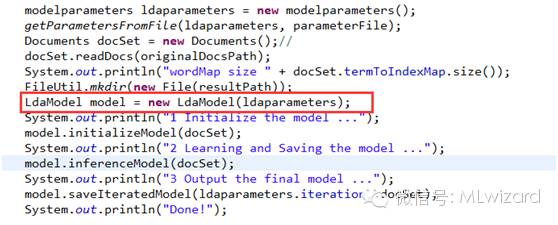
初始化过程是对每一个词先赋予一个随机主题
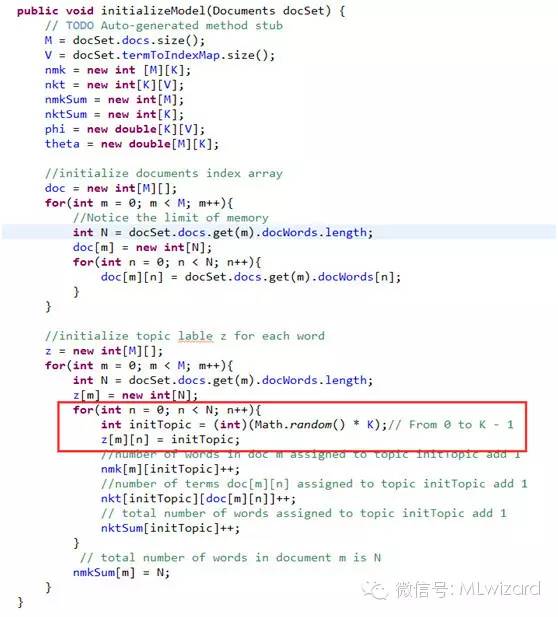
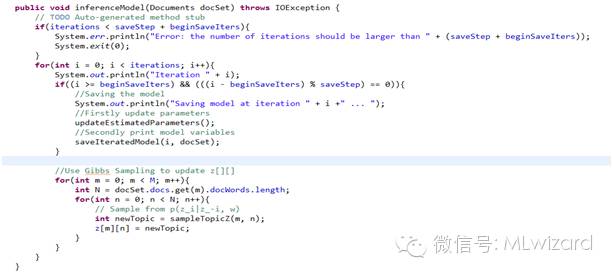
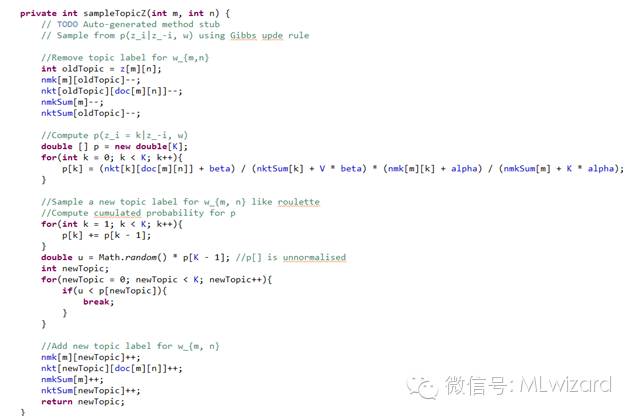
吉布斯采样达到LDA分布的马尔科夫链平稳,求出LDA最优解
输出结果如下:
如上图所示:
1)把文档聚成10个主题,每个主题下有对应的关键词表
2)关键词属于对应主题的概率,全部关键词概率和为1
3)根据关键词归纳出主题标签
例如:
① topic0中对应关键词表:医院、治疗、患者;可见topic0是和“医疗”相关的
② topic2中对应关键词表:市场、中国、企业、公司;可见topic2是和“经济”相关的
③ topic4中对应关键此表:工作、专业、学生、学校;可见topic4是和“学生求职”相关





