LibRec 每周算法:LDA主题模型
主题模型就是用来发现文档所属主题并归类的算法,它是一种非监督机器学习技术,可以用来识别大规模文档集或预料库中的潜在隐藏的主题信息。例如基因数据、图像处理和文档主题提取等。确定主题和主题分析是主题模型解决的问题。
文档的主题提取是机器学习和自然语言处理等领域是用来在一系列文档中发现抽象主题的一种统计模型。比如某篇新闻在“汽车”主题的概率是60%,“科技”主题的概率是20%,“财经”主题的概率是10%,其他主题的概率是10%。目前最为流行的叫做隐含狄利克雷分布(Latent Dirichlet Allocation),简称LDA。
LDA模型
怎么生成模型?我们可以认为一篇汽车主题的文档肯定是汽车主题相关的词语组织起来的,那么一篇文档就是“以一定概率选择了某个主题,并从这个主题中以一定概率选择某些词语”,文档和单词是可见的,而主题是隐藏的。每个词语在文档中出现的概率为:

LDA定义了如下生成过程:
对于每篇文档,从主题分布中抽取一个主题。
从上述抽到的主题所对应的单词分布中抽取一个单词。
重复上述过程直至遍历文档中的每个单词。
概率公式可以用矩阵表示:
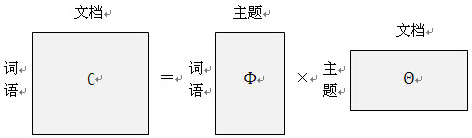
第一个矩阵表示每个文档里面每个词语出现的概率,第二个矩阵表示每个文档里面每个主题出现的概率,第三个矩阵表示每个主题里面每个词语出现的概率。
算法实现
1、特征抽取
分词:根据确定主题的原理,我们实际是对文档中词语进行计算概率,所以首先要提取词语,常用的分词工具有很多比如jieba、Hanlp、ICTCLA等。
去停用词:通过停用词库过滤对分类无价值的词比如的、啊、吧等。
数据的预处理:一般采用TF-IDF算法进行归一化处理,TF-IDF的主要思想是:如果某个单词在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力。
TF-IDF算法原理请参考另一篇《贝叶斯分类》
2、模型训练
LDA主要完成两个任务,给定现有文档集合D,要确定超参数α,β值;或者给一篇新的文档,能够依据前面的超参数来确定隐藏变量θ,z分布。其实后面一个任务可以归到前面中,因为前面可以顺带求出隐变量分布。
概率模型图:

从图中可以看出,LDA是一个三层的贝叶斯模型。各个变量的意义如下:
α,β 是文档集级别的参数,每个文档都一样,每生成一个文档集采样一次。
θ 是文档级别的变量,每个文档对应一个θ,每生成一个文档时采样一次。
z和w都是词语级别的变量,w由z和β共同生成,每生成一个词语时采样一次。
LDA模型是根据语料集中学习训练两个参数α和β,学习出α和β就可以生成文档。α和β的意义分别是:
α是狄利克雷分布的参数,用于生成一个主题θ向量;
β代表k*v的矩阵,代表一个确定的主题-词分布矩阵。
我们的目标就是使用最大似然估计来确定参数α,β。
公式推导:
(1)给定α,β,根据文档生成的过程,可以得到,主题分布的参数θ,N个主题的集合z,N个单词的集合w,的联合分布:
(2)要消掉上式中的隐变量θ,z,需对连续型变量θ 求积分,对离散型变量z 求和,得到文档w 的边缘分布:
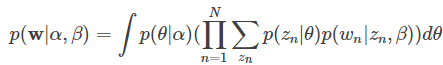
(3)那么就可以通过求乘积进一步得到文档集D的边缘分布:

至此,我们对一个文档集建立了LDA模型,模型的参数是α,β,我们还引入了两个隐变量θ,z,接下来要做的就是消掉隐变量,求解参数,确定LDA模型。
3、EM算法
LDA一般有两种方法,一是基于Gibbs采样算法求解,二是基于变分推断EM算法求解。我们选择EM算法,EM训练LDA有一个潜在的图结构。
EM即最大期望算法(Exception Maximization),它是在概率模型中寻找参数最大似然估计或者最大后验估计的算法,其中概率模型依赖于无法观测的隐藏变量。EM方法解决这样的问题:估计两个参数A和B,这两个参数都是未知的,知道了参数A就能得到参数B,反过来知道了参数B就能得到参数A,这时我们就可以先给A一个初始值,然后计算出B,然后再根据计算出的B再计算A,这样反复迭代下去,一直到收敛为止。EM算法主要应用在机器学习中非监督算法的数据聚类领域。
具体应用到LDA,采用EM方法的步骤如下:
(1)初始化:对语料中每个主题中的每个词语出现的次数随机初始化,每个文档中每个主题出现的次数随机初始化,根据这些次数利用Dirichlet分布计算出主题分布的先验分布α(每个主题在文档中出现的概率分布),词语分布的先验分布β(每个词语在某个主题下出现的概率分布);
(2)E-STEP:对于文档中的每个单词,计算出是由哪个主题产生的,因为可能有多个主题都会产生这个单词,那么它到底是属于哪个主题呢?计算出每个主题产生这个单词的概率:

然后找出概率最大的那个主题,认为这个单词就是这个主题产生的;
(3)M-STEP:利用E-STEP 步求得的隐藏变量的期望,对参数模型进行最大似然估计。每次E- STEP获取最优变分参数α和β,计算似然函数,M- STEP最大化这个似然函数,更新模型参数α和β,不断迭代直到收敛。
4、基于EM的推荐算法
基于EM的概率图推荐算法在LibRec中有很多实现,大家可在LibRec源码工程中阅读,下图是算法列表:

主题模型在推荐中的应用
使用主题模型计算物品(文档也可以是物品)的相似度时,可以先计算出物品在主题上的分布,然后利用两个物品的主题分布计算物品的相似度。比如,如果两个物品的话题分布相似,则认为两个物品具有较高的相似度,反之则认为两个物品的相似度较低。在推荐系统中它能够基于用户的行为对物品进行聚类,也就是把物品划分到不同主题,这些主题可以理解为用户的兴趣点。
已知的用户行为数据集,使用主题模型对其建模后,我们可以得到如下图所示的模型:

在LibRec中有基于LDA的推荐算法,请查看源码LDARecommender.java参考文献《Latent Dirichlet Allocation for implicit feedback》
效果评估
困惑度(perplexity):Perplexity可以粗略的理解为“对于一篇文章,我们的LDA模型有多不确定它是属于某个Topic的”。优化策略是Topic越多,Perplexity越小,但是这样越容易过拟合。
公式如下:

参考文献
http://www.cnblogs.com/pinard/p/6873703.html
http://blog.csdn.net/happyer88/article/details/45936107
http://blog.csdn.net/v_JULY_v/article/details/41209515





