达观数据NLP技术的应用实践和案例分析




达观文本挖掘系统整体方案
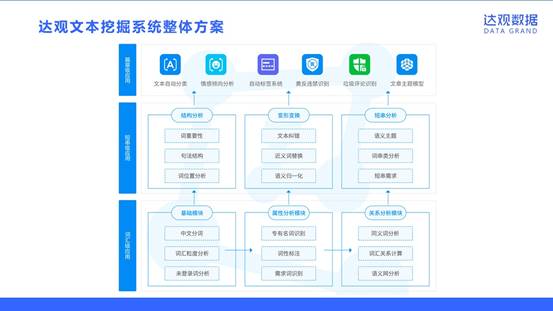
达观文本挖掘系统整体方案包含了NLP处理的各个环节,从处理的文本粒度上来分,可以分为篇章级应用、短串级应用和词汇级应用。
篇章级应用有六个方面,已经有成熟的产品支持企业在不同方面的文本挖掘需求:
垃圾评论:精准识别广告、不文明用语及低质量文本。
黄反识别:准确定位文本中所含涉黄、涉政及反动内容。
标签提取:提取文本中的核心词语生成标签。
文章分类:依据预设分类体系对文本进行自动归类。
情感分析:准确分析用户透过文本表达出的情感倾向。
文章主题模型:抽取出文章的隐含主题。
为了实现这些顶层应用,达观掌握从词语短串分析个层面的分析技术,开发了包括中文分词、专名识别、语义分析和词串分析等模块。
文本挖掘任务类型的划分

文本挖掘任务大致分为四个类型:类别到序列、序列到类别、同步的(每个位置都要产生输出)序列到序列、异步的序列到序列。
其中,同步的序列到序列的例子包括中文分词,命名实体识别和词性标注。一部的序列到序列包括机器翻译和自动摘要。序列到类别的例子包括文本分类和情感分析。类别(对象)到序列的例子包括文本生成和形象描述。
序列标注应用:中文分词
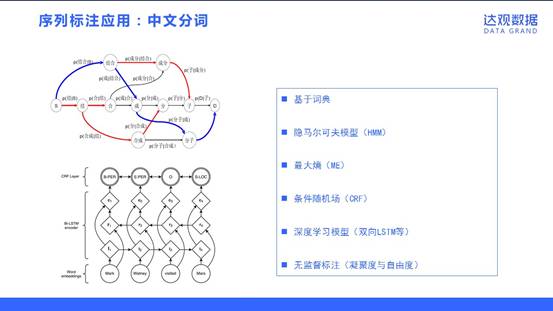
同步的序列到序列,其实就是序列标注问题,应该说是自然语言处理中最常见的问题。序列标注的应用包括中文分词、命名实体识别和词性标注等。序列标注问题的输入是一个观测序列,输出的是一个标记序列或状态序列。举中文分词为例,处理“结合成分子”的观测序列,输出“结合/成/分子”的分词标记序列。针对中文分词的这个应用,有多种处理方法,包括基于词典的方法、隐马尔可夫模型(HMM)、最大熵模型、条件随机场(CRF)、深度学习模型(双向LSTM等)和一些无监督学习的方法(基于凝聚度与自由度)。
序列标注应用:NER(命名实体识别)

命名实体识别:Named Entity Recognition,简称NER,又称作“专名识别”,是指识别文本中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等。通常包括实体边界识别和确定实体类别。
对与命名实体识别,采取不同的标记方式,常见的标签方式包括IO、BIO、BMEWO和BMEWO+。大部分情况下,标签体系越复杂准确度也越高,但相应的训练时间也会增加。因此需要根据实际情况选择合适的标签体系。
英文处理

在NLP领域,中文和英文的处理在大的方面都是相通的,不过在细节方面会有所差别。其中一个方面,就是中文需要解决分词的问题,而英文天然的就没有这个烦恼;另外一个方面,英文处理会面临词形还原和词根提取的问题,英文中会有时态变换(made==>make),单复数变换(cats==>cat),词根提取(arabic==>arab)。
在处理上面的问题过程中,不得不提到的一个工具是WordNet。WordNet是一个由普林斯顿大学认识科学实验室在心理学教授乔治·A·米勒的指导下建立和维护的英语字典。在WordNet中,名词,动词,形容词和副词各自被组织成一个同义词的网络,每个同义词集合都代表一个基本的语义概念,并且这些集合之间也由各种关系连接。我们可以通过WordNet来获取同义词和上位词。
词嵌入

在处理文本过程中,我们需要将文本转化成数字可表示的方式。词向量要做的事就是将语言数学化表示。词向量有两种实现方式:One-hot 表示,即通过向量中的一维0/1值来表示某个词;词嵌入,将词转变为固定维数的向量。
word2vec 是使用浅层和双层神经网络产生生词向量的模型,用来训练以重新建构语言学之词文本,网络以词表现,并且需猜测相邻位置的输入词。word2vec中词向量的训练方式有两种,cbow(continuous bags of word)和skip-gram。cbow和skip-gram的区别在于,cbow是通过输入单词的上下文(周围的词的向量和)来预测中间的单词,而skip-gram是输入中间的单词来预测它周围的词。
文档建模

要使计算机能够高效地处理真实文本,就必须找到一种理想的形式化表示方法,这个过程就是文档建模。文档建模一方面要能够真实地反映文档的内容,另一方面又要对不同文档具有区分能力。文档建模比较通用的方法包括布尔模型、向量空间模型(VSM)和概率模型。其中最为广泛使用的是向量空间模型。

利用机器学习进行模型训练
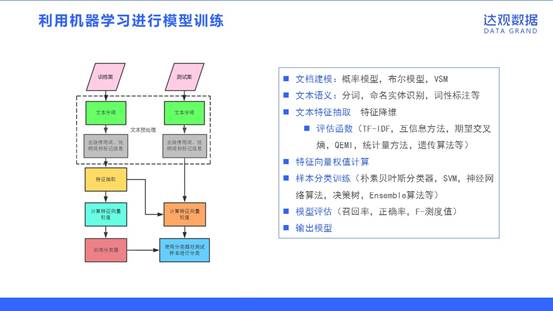
文本分类的流程如图所示,包括训练、文本语义、文本特征处理、训练模型、模型评估和输出模型等几个主要环节。其中介绍一下一些主要的概念。
文档建模:概率模型,布尔模型,VSM
文本语义:分词,命名实体识别,词性标注等
文本特征处理:特征降维,包括使用评估函数(TF-IDF,互信息方法,期望交叉熵,QEMI,统计量方法,遗传算法等);特征向量权值计算。
样本分类训练(朴素贝叶斯分类器,SVM,神经网络算法,决策树,Ensemble算法等)
模型评估(召回率,正确率,F-测度值)
输出模型
向量空间模型

向量空间模型是常用来处理文本挖掘的文档建模方法。VSM概念非常直观——把对文本内容的处理简化为向量空间中的向量运算,并且它以空间上的相似度表达语义的相似度,直观易懂。当文档被表示为文档空间的向量时,就可以通过计算向量之间的相似性来度量文档间的相似性。它的一些实现方式包括:
N-gram模型:基于一定的语料库,可以利用N-Gram来预计或者评估一个句子是否合理。
TF-IDF模型:若某个词在一篇文档中出现频率TF高,却在其他文章中很少出现,则认为此词具有很好的类别区分能力。
Paragraph Vector模型:其实是wordvector的一种扩展。Gensim中的Doc2Vec 以及Facebook开源的Fasttext工具也是采取了这么一种思路,它们将文本的词向量进行相加/求平均的结果作为Paragraph Vector。
文本特征提取算法

目前大多数中文文本分类系统都采用词作为特征项,作为特征项的词称作特征词。这些特征词作为文档的中间表示形式,用来实现文档与文档、文档与用户目标之间的相似度计算。如果把所有的词都作为特征项,那么特征向量的维数将过于巨大。有效的特征提取算法,不仅能降低运算复杂度,还能提高分类的效率和精度。文本特征提取的算法包含下面三个方面:
从原始特征中挑选出一些最具代表文本信息的特征,例如词频、TF-IDF方法。
基于数学方法找出对分类信息共现比较大的特征,主要例子包括互信息法、信息增益、期望交叉熵和统计量方法
以特征量分析多元统计分布,例如主成分分析(PCA)
文本权重计算方法
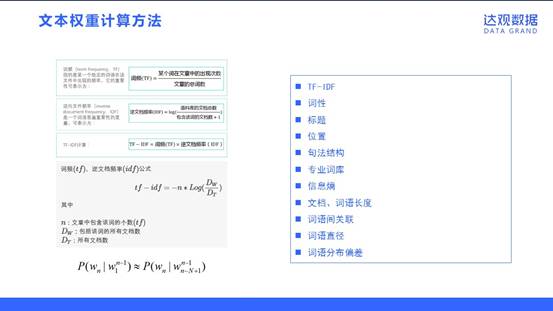
特征权重用于衡量某个特征项在文档表示中的重要程度或区分能力的强弱。选择合适的权重计算方法,对文本分类系统的分类效果能有较大的提升作用。特征权重的计算方法包括:
1. TF-IDF
2. 词性
3. 标题
4. 位置
5. 句法结构
6. 专业词库
7.信息熵
8. 文档、词语长度
9. 词语间关联
10. 词语直径
11. 词语分布偏差
其中提几点,词语直径是指词语在文本中首次出现的位置和末次出现的位置之间的距离。词语分布偏差所考虑的是词语在文章中的统计分布。在整篇文章中分布均匀的词语通常是重要的词汇。
分类器设计
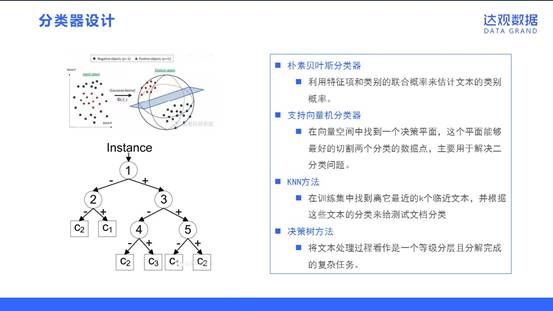
由于文本分类本身是一个分类问题,所以一般的模式分类方法都可以用于文本分类应用中。常用分类算法的思路包括下面四种:
朴素贝叶斯分类器:利用特征项和类别的联合概率来估计文本的类别概率。
支持向量机分类器:在向量空间中找到一个决策平面,这个平面能够最好的切割两个分类的数据点,主要用于解决二分类问题。
KNN方法:在训练集中找到离它最近的k个临近文本,并根据这些文本的分类来给测试文档分类
决策树方法:将文本处理过程看作是一个等级分层且分解完成的复杂任务。
分类算法融合
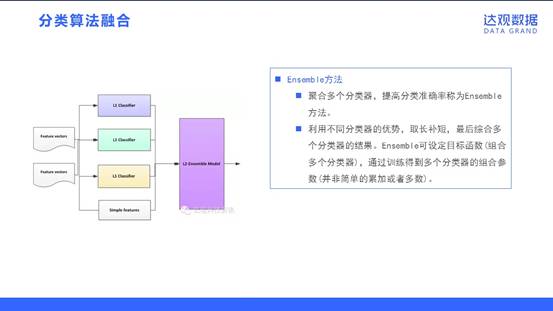
聚合多个分类器,提高分类准确率称为Ensemble方法。
利用不同分类器的优势,取长补短,最后综合多个分类器的结果。Ensemble可设定目标函数(组合多个分类器),通过训练得到多个分类器的组合参数(并非简单的累加或者多数)。
我们这里提到的ensemble可能跟通常说的ensemble learning有区别。主要应该是指stacking。Stacking是指训练一个模型用于组合其他各个模型。即首先我们先训练多个不同的模型,然后再以之前训练的各个模型的输出为输入来训练一个模型,以得到一个最终的输出。在处理ensemble方法的时候,需要注意几个点。基础模型之间的相关性要尽可能的小,并且它们的性能表现不能差距太大。
CNN文本分类
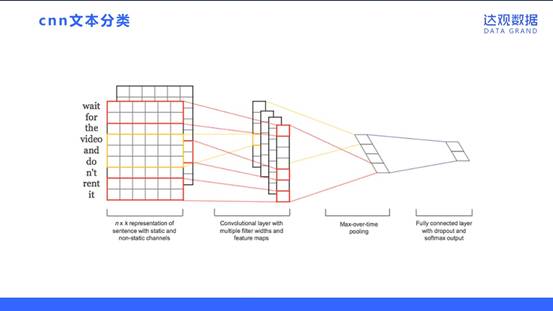
采取DNN方法进行文本分类,相比传统方法会在一些方面有优势。基于向量空间模型的文本分类方法是没有考虑到词的顺序的。基于卷积神经网络(CNN)来做文本分类,可以利用到词的顺序包含的信息。如图展示了比较基础的一个用CNN进行文本分类的网络结构。CNN模型把原始文本作为输入,不需要太多的人工特征。下图是CNN模型的一个实现,共分四层,第一层是词向量层,doc中的每个词,都将其映射到词向量空间,假设词向量为k维,则n个词映射后,相当于生成一张n*k维的图像;第二层是卷积层,多个滤波器作用于词向量层,不同滤波器生成不同的feature map;第三层是pooling层,取每个feature map的最大值,这样操作可以处理变长文档,因为第三层输出只依赖于滤波器的个数;第四层是一个全连接的softmax层,输出是每个类目的概率,中间一般加个dropout,防止过拟合。
Attention Model与seq2seq
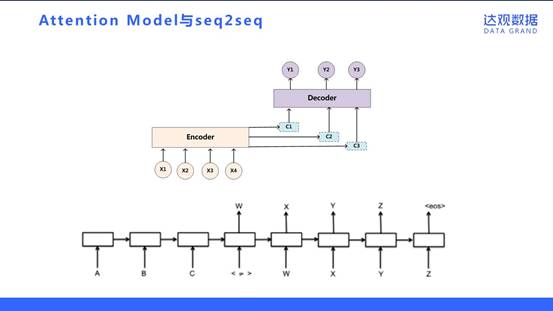
Attention Model是传统自编码器的一个升级版本。传统RNN的Encoder-Decoder模型,它的缺点是不管无论之前的context有多长,包含多少信息量,最终都要被压缩成固定的vector,而且各个维度维度收到每个输入维度的影响都是一致的。为了解决这个问题,它的idea其实是赋予不同位置的context不同的权重,越大的权重表示对应位置的context更加重要。Attention Model是当前的研究热点,它广泛地可应用于文本生成、机器翻译和语言模型等方面。

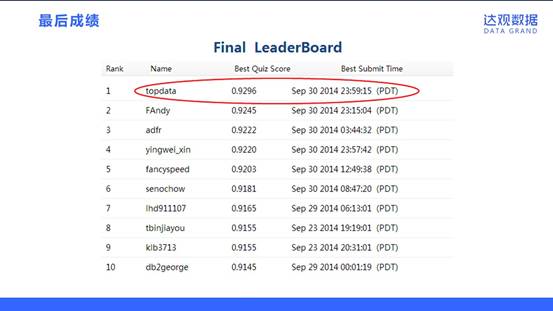
CIKM竞赛题目

我们达观数据团队参加的是2014年举办的CIKM CUP比赛。数据由百度提供,场景是用户在搜索引擎上真实完整的查询过程。用户与搜索引擎的一轮完整交互过程称为一个Search Session,在Session里提供的信息包括:用户查询词(Query),用户所点击的搜索结果的标题(Title),如果用户在Session期间续的搜索和点击均会被记录。
预测训练样本Query的查询意图包括八个大类:“VIDEO”,“NOVEL”,“GAME”,“TRAVEL”,“LOTTERY”,“ZIPCODE”,“OTHER”和“UNKNOWN”。每条样本会对应多个分类。
有个细节值得一提,就是为了避免不同国家参赛者对数据有理解的区别,提供的文本数据按单字进行了加密。
题目基础分析

在拿到题目之后,我们进行了初步的分析,得到的结论包括以下几点:
类别不完全互斥,存在交叉:例如搜“极品飞车”,既可能是指一款电脑游戏(CLASS=GAME),也有可能是同名的电影(CLASS=VIDEO)。
样本分布不均匀:从类别方面来看,训练样本多寡不均;从Query频次方面来看,少数热门Query出现频次极高,大量冷门Query特征稀有。
训练样本里存在两个特殊类别(“OTHER”,“UNKNOWN”):“OTHER”和其他6个已知类别并列,且不存在任何交叉。“UNKNOWN”可看做未标注样本,量非常大。
Query以短文本为主,Query有对应的很多点击Title。
提供了Session信息,同一session的query和title具有紧密的联系关系。
文本特征抽取
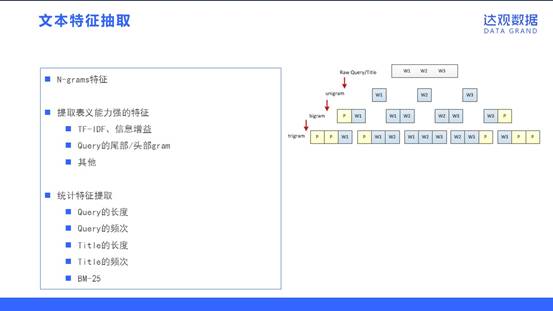
在进行文本特征抽取模块的开发过程中,我们率先采取了 N-grams特征作为baseline版本的基础特征,将unigram、bigram和trigram的特征都抽取出来进行模型训练。
在分析数据时,我们提取了一些表义能力强的特征作为扩展:TF-IDF、信息增益;Query的尾部/头部gram;其他。
另外,我们也提取了部分统计特征加入到文本的特征表示,包括Query的长度,Query的频次,Title的长度,Title的频次和BM-25。
query分析
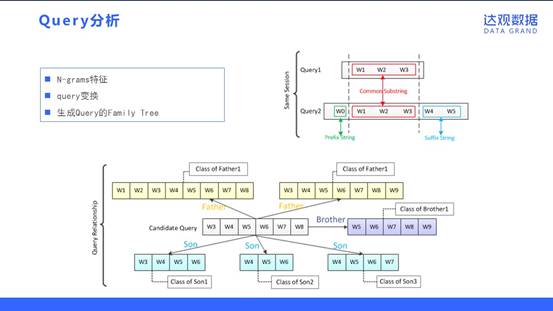
在分析Sessionlog的过程中,一个有意思的发现是往往用户的查询词存在递进关系。尤其在前面的Query查询满意度不高的情况下,用户往往会主动进行Query变换,期望获得更满意的结果。而此时Query变换前后的Diff部分能强烈的表达用户的查询意图。
如图,通过在同Session的上下文中(半径为R的范围内)提取出存在一定相似度的Query1和Query2,找到Diff部分的前缀(Prefix String)和后缀(Suffix String),它们可以认为是Query的需求词/属性词集中的部分,形成特征后对提高精度起到了很好的帮助。
另外,我们挖掘Query和Query间的传递关系并形成了一个家族树。家族树的概念是如果两个Query之间存在真包含关系,即Query1 ⊂ Query2,则Query1为Son,Query2为Father;Father和Son是多对多关系,两个Query如果有共同的Father且互相没有包含关系则为Brother。显然通过FamilyTree我们可以将Query亲属的Category作为该Query的特征向量的一部分来发挥作用
Query-title分析
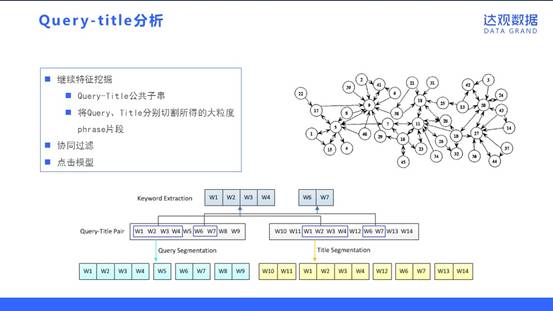
我们发现Query和Title往往是存在共同的词汇(公共子串)。搜索引擎通常会把Title里和Query相同的词汇重点提示给用户(例如百度文字飘红,Google加粗文字),这些Query-Title中相同的词汇往往是最为重要的语料。
同时,我们利用了推荐的思想来处理。协同过滤既可以自定义距离计算公式的方法(Distance-based)来计算,也可以采用基于矩阵分解(Model-based)方法来计算,后者精度往往更高。因此比赛中我们采用了SVD分解的方法来解析Query-Title关系,实践中我们发现SVD++算法没有在SVD基础上有提升,Title或Query的特征作为隐式反馈引入后反而会降低,因此我们将特征放入Global bias Feature里使用。
训练过程步骤

训练过程步骤如下:
使用Train pig抽取特征,形成特征向量后训练L1层模型
使用训练好的L1层模型,预测Testpig,将预测结果形成L2层的输入特征向量
结合其他特征后,形成L2层的特征向量,并使用Testpig训练L2层模型
使用全部训练样本(Tain pig +Test pig)重新训练L1层模型
将待测样本Test抽取特征后先后使用上述训练好的L1+L2层Ensemble模型来生成

新闻分类

定制行业专业语料,定期更新语料知识库,构建行业垂直语义模型。
计算term权重,考虑到位置特征,网页特征,以及结合离线统计结果获取到核心的关键词。
使用主题模型进行语义扩展
监督与半监督方式的文本分类
垃圾广告过滤

垃圾广告过滤作为文本分类的一个场景有其特殊之处,那就是它作为一种防攻击手段,会经常面临攻击用户采取许多变换手段来绕过检查。
处理这些变换手段有多重方法:
对变形词进行识别还原,包括要处理间杂特殊符号,同音、简繁变换,和偏旁拆分、形近变换。
语言模型识别干扰文本,如果识别出文本是段不通顺的“胡言乱语”,那么他很可能是一段用于规避关键字审查的垃圾文本。
通过计算主题和评论的相关度匹配来鉴别。
基于多种表达特征的分类器模型识别来提高分类的泛化能力。
情感分析
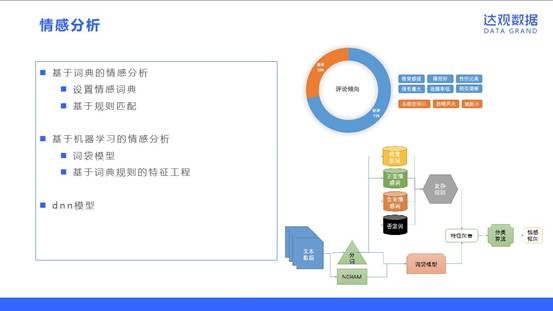
情感分析的处理办法包括:
基于词典的情感分析,主要是线设置情感词典,然后基于规则匹配(情感词对应的权重进行加权)来识别样本是否是正负面。
基于机器学习的情感分析,主要是采取词袋模型作为基础特征,并且将复杂的情感处理规则命中的结果作为一维或者多维特征,以一种更为“柔性”的方法融合到情感分析中,扩充我们的词袋模型。
使用dnn模型来进行文本分类,解决传统词袋模型难以处理长距离依赖的缺点。
其他应用

Nlp在达观数据的其他一些应用包括:
标签抽取
观点挖掘
应用于推荐系统
应用于搜索引擎
欢迎大家多多了解!

此技术讲解为“达观杯”个性化推荐挑战赛赛事直播内容。为了对比赛的选手有所帮助,达观数据组织了四次线上相关技术分享,以下是本次赛事中历次技术分享的录播链接,大家可参考学习!如果比赛困难或疑问,欢迎私信小科/达观数据或加群131818435随时交流。
请大家注意比赛时间,及时提交作品,谢谢。
推荐阅读
直播录屏:http://pan.baidu.com/s/1mhTOxRi 密码:3w1h
直播录屏:https://pan.baidu.com/s/1mimgcnI 密码:xebw
直播录屏:https://pan.baidu.com/s/1hseLjRA 密码:hcua