BAT机器学习面试1000题系列(第121~125题)

上期思考题及参考解析
120.请对比下Sigmoid、Tanh、ReLu这三个激活函数
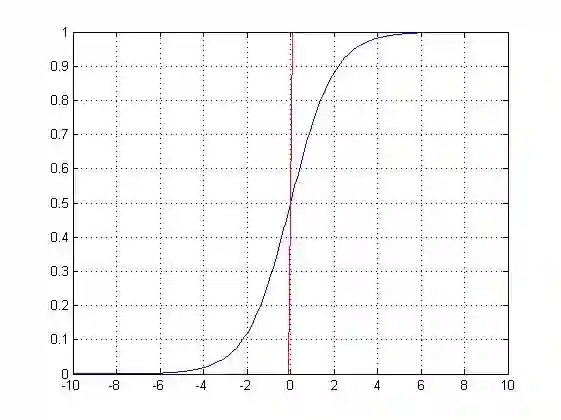
logistic函数,应用在Logistic回归中。<span style="color: rgb(51, 51, 51); font-family:;" new="" times="" 14px;"="">logistic回归的目的是从特征学习出一个0/1分类模型,而这个模型是将特性的线性组合作为自变量,由于自变量的取值范围是负无穷到正无穷。因此,使用logistic函数将自变量映射到(0,1)上,映射后的值被认为是属于y=1的概率。
假设函数
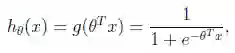
其中x是n维特征向量,函数g就是logistic函数。
而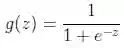

可以看到,将无穷映射到了(0,1)。
而假设函数就是特征属于y=1的概率。
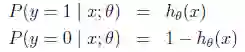
从而,当我们要判别一个新来的特征属于哪个类时,只需求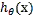
更多详见:https://mp.weixin.qq.com/s/7DgiXCNBS5vb07WIKTFYRQ
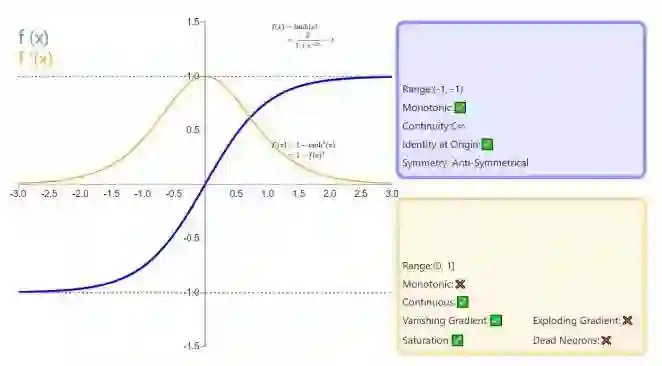
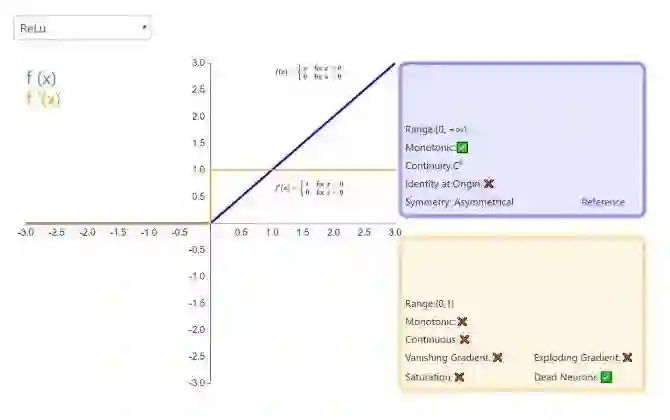
121.Sigmoid、Tanh、ReLu这三个激活函数有什么缺点或不足,有没改进的激活函数
@我愛大泡泡,来源:http://blog.csdn.net/woaidapaopao/article/details/77806273
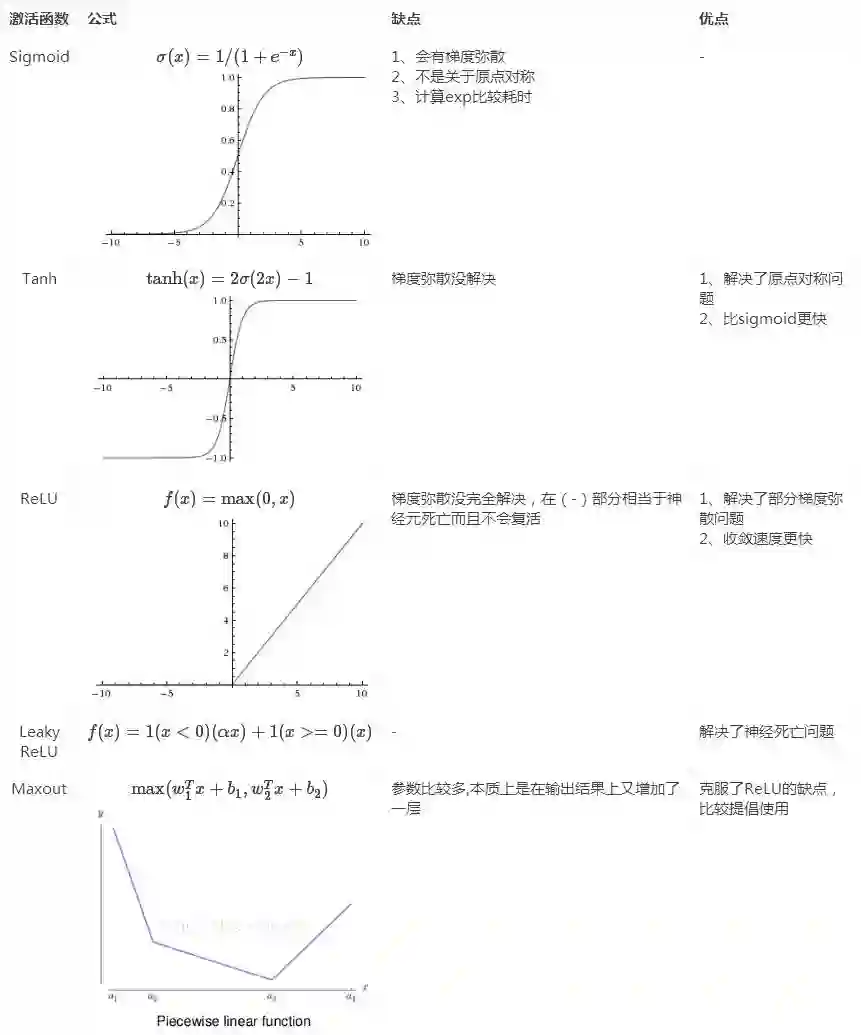
122.怎么理解决策树、xgboost能处理缺失值?而有的模型(svm)对缺失值比较敏感?
https://www.zhihu.com/question/58230411
123.为什么引入非线性激励函数?
@Begin Again,来源:https://www.zhihu.com/question/29021768
如果不用激励函数(其实相当于激励函数是f(x) = x),在这种情况下你每一层输出都是上层输入的线性函数,很容易验证,无论你神经网络有多少层,输出都是输入的线性组合,与没有隐藏层效果相当,这种情况就是最原始的感知机(Perceptron)了。
正因为上面的原因,我们决定引入非线性函数作为激励函数,这样深层神经网络就有意义了(不再是输入的线性组合,可以逼近任意函数)。最早的想法是sigmoid函数或者tanh函数,输出有界,很容易充当下一层输入(以及一些人的生物解释)。
124.请问人工神经网络中为什么ReLu要好过于tanh和sigmoid function?
@Begin Again,来源:https://www.zhihu.com/question/29021768
第一,采用sigmoid等函数,算激活函数时(指数运算),计算量大,反向传播求误差梯度时,求导涉及除法,计算量相对大,而采用Relu激活函数,整个过程的计算量节省很多。
第二,对于深层网络,sigmoid函数反向传播时,很容易就会出现梯度消失的情况(在sigmoid接近饱和区时,变换太缓慢,导数趋于0,这种情况会造成信息丢失),从而无法完成深层网络的训练。
第三,Relu会使一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生(以及一些人的生物解释balabala)。当然现在也有一些对relu的改进,比如prelu,random relu等,在不同的数据集上会有一些训练速度上或者准确率上的改进,具体的大家可以找相关的paper看。
多加一句,现在主流的做法,会多做一步batch normalization,尽可能保证每一层网络的输入具有相同的分布[1]。而最新的paper[2],他们在加入bypass connection之后,发现改变batch normalization的位置会有更好的效果。大家有兴趣可以看下。
[1] Ioffe S, Szegedy C. Batch normalization: Accelerating deep network training by reducing internal covariate shift[J]. arXiv preprint arXiv:1502.03167, 2015.
[2] He, Kaiming, et al. "Identity Mappings in Deep Residual Networks." arXiv preprint arXiv:1603.05027 (2016).
本期思考题:

125.为什么LSTM模型中既存在sigmoid又存在tanh两种激活函数?
在评论区留言,一起交流探讨,让更多小伙伴受益。
参考答案在明天公众号上公布,敬请关注!
往期题目:
【关注本公众号,点击菜单“有奖游戏”,答题抽奖】

课程咨询|微信:julyedukefu
七月热线:010-82712840