TUM大牛组最新工作:不需要3D包围盒,单目实现3D车辆检测!
点击上方“计算机视觉life”,选择“星标”
快速获得最新干货
Learning Monocular 3D Vehicle Detection without 3D Bounding Box Labels
Technical University of Munich ,Artisense
来源:GCPR 2020
编译:wyc
1摘要
基于深度学习的三维物体探测器的训练需要三维边界框标签的大数据集,这些数据集必须通过手工标记生成。我们提出了一个学习无三维边界盒标签的单目三维目标检测的网络结构和训练过程。通过将物体表示为三角形网格并采用可微形状绘制,我们定义了基于深度图、分割mask以及由预先训练的现成网络生成的Ego-motion的损失函数。我们在真实世界的KITTI数据集上对所提出的算法进行了评估,并与需要三维边界框标签进行训练的最新方法相比,取得了很好的性能,并且优于传统的基线方法。
2背景及贡献
作者的灵感来自与19年的AAAI谷歌的一篇Depth prediction without the sensors: Leveraging structure for unsupervised learning from monocular videos,由此作者想到了如何通过深度估计的监督实现3D目标检测自监督从而达到舍弃3Dbox的目的。
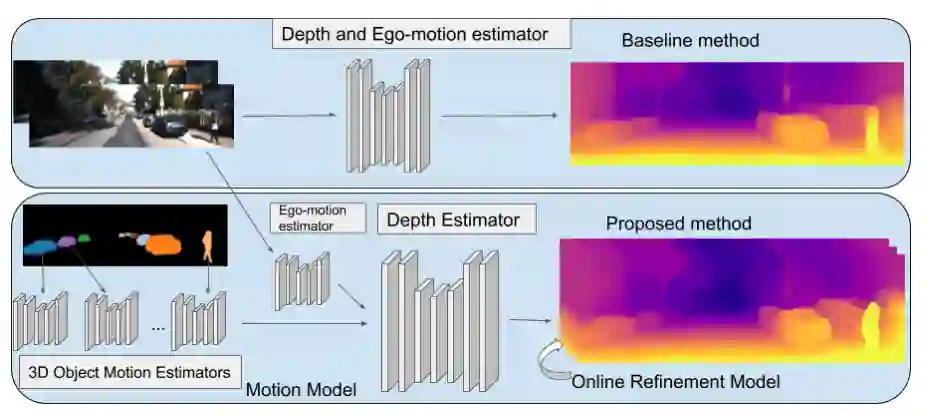

本文提出了一种基于可微形状渲染的单目3D车辆检测器。模型的主要输入是二维分割掩模和深度图,从预先训练的现成网络中获得。因此,我们的方法不需要三维边界框标签来监督。二维地面真实和激光雷达点云只需要训练预先训练的网络。因此,我们克服了手工标记数据集的需要,这些数据集的获取很麻烦,并有助于更广泛的适用于三维目标检测。实验表明,尽管没有使用三维边界盒标签进行训练,但我们的模型仍取得了与最先进的监控单目3D目标检测相当的结果。我们进一步证明,用stereo深度代替输入的单目深度可以产生具有竞争力的立体3D检测性能,这显示了我们的3D检测框架的通用性。
3方法

3.1整体结构
3.2形状重表示(Shape Representation)
作者引用了Joint object pose estimation and shape reconstruction in urban street scenes using 3d shape priors中对于物体shape的描述方法。平均顶点位置用 , 个顶点位移矩阵用 表示, 将形状系数记为 ,将规范坐标系中的变形顶点位置记为 。变形的顶点位置是线性组合:
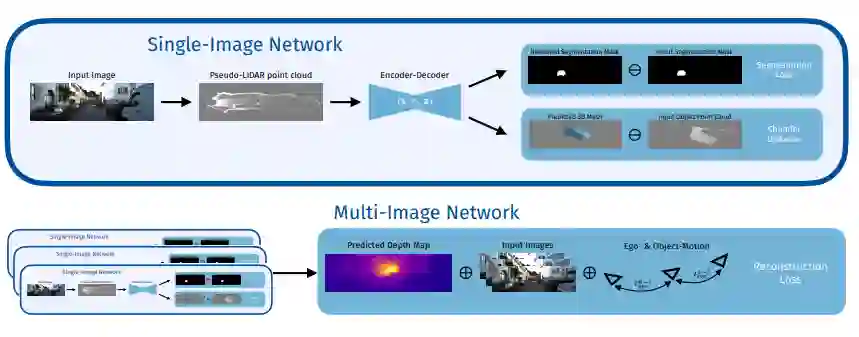
3.3单张图像网路(Single-Image Network)
输入的深度图被反向投影到一个点云中,该点云将架构与深度源解耦,如[33]所示。用对象分割蒙版过滤点云以获得对象点云。对于单眼图像的深度图,对象点云通常在遮挡边界处具有离群值,这些离群值基于其深度值被滤除。
然后,Frustum PointNet编码器[26]预测车辆的位置 ,方向 和形状 。将形状系数z应用到规范的对象附加坐标系中,基于方程式1根据我们建议的形状流形获得变形网格。变形网格绕y轴旋转ry并通过x平移 以获得参考坐标系中的网格。
分别渲染参考坐标系中的变形网格,以获得预测分割Mask 和预测深度图 。合并了车辆的预测姿势和形状的渲染深度图 仅在多图像网络中使用。对于输入分割蒙版定义的不属于车辆的图像区域,将输入深度图用作背景深度,否则从变形的网格渲染深度。为了渲染预测的深度图和分割掩膜,中提出的可微分渲染器的最新实现。
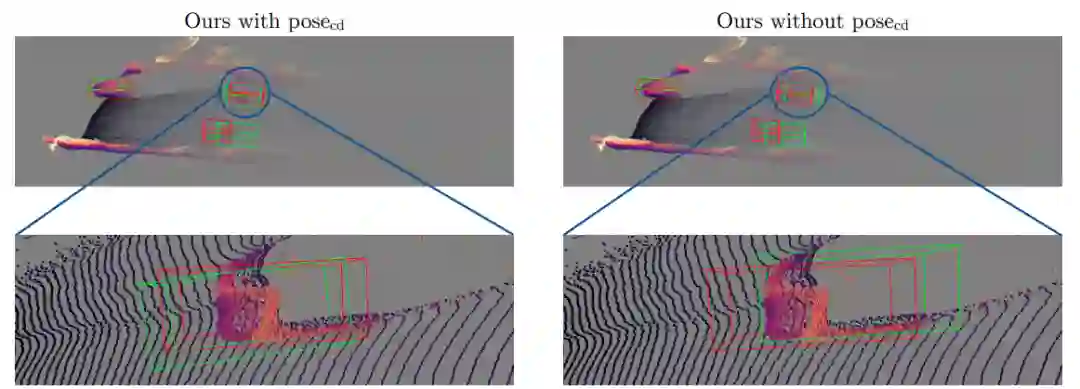
3.4Pose的影响
3.5Loss Functions
为了训练没有三维边界框标签,我们使用三个损失,分割损失 ,切角距离 和光度重建损失 。前两个是为单个图像定义的,光度重建损失依赖于三个连续帧的时间照片一致性。总损失是每帧的单个图像损失与重建损失的加权:
其中:
Segmentation Loss
Chamfer Distance
3.4Multi-Image Reconstruction Loss
多图像网络的灵感来自于最近成功的单目图像的自监督深度预测,它依赖于将时间上连续的图像差分地扭曲到一个公共帧来定义重建损失。将单图像网络应用于同一车辆的三个连续图像 ,并在中间帧定义重建损失。重建损失的公式Depth prediction without the sensors所示,我们使用其预先训练的网络来估计翘曲所需的自我运动和物体运动。
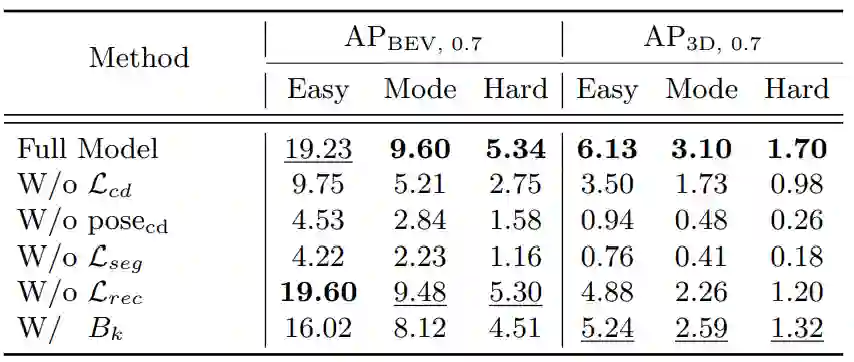
实验
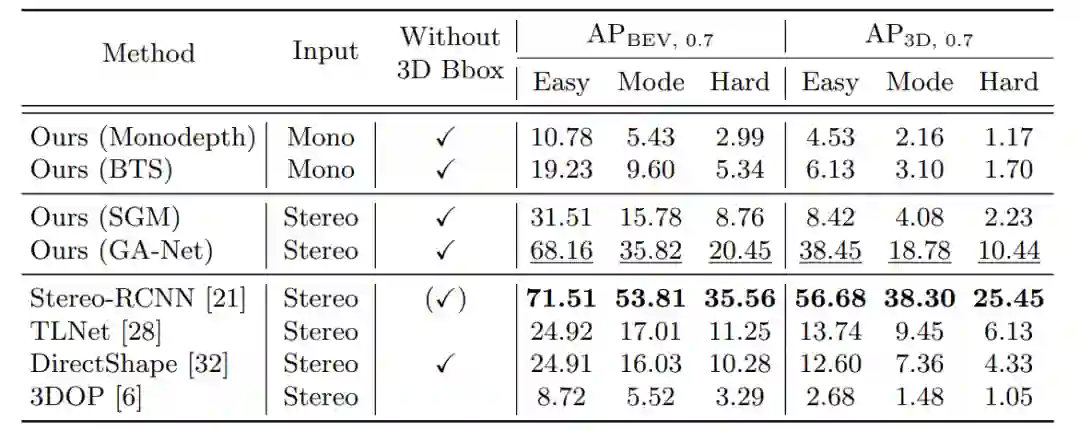
1.不同深度的without 3D Bbox 的3D目标检测精度
从0到1学习SLAM,戳↓

交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
投稿、合作也欢迎联系:simiter@126.com

扫描关注视频号,看最新技术落地及开源方案视频秀 ↓




