打破静态融合操作常规!腾讯提出新的MLP架构DynaMixer

极市导读
与Vision Transformer和CNN相比,Vision MLP的模型的成功表明,token和通道之间简单的信息融合操作就可以为深度识别模型产生良好的表示能力。然而,现有的Vision MLP模型通过静态融合操作来融合token,对要混合的token 内容缺乏适应性。因此,本文提出了一种有效的Vision MLP架构,称为 DynaMixer,采用动态信息融合机制。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

论文链接:https://arxiv.org/pdf/2201.12083.pdf
从摘要读论文
最近,Vision MLP 模型在主流视觉识别任务上取得了可喜的表现。与 Vision Transformer 和 CNN 相比,Vision MLP 的模型的成功表明,token 和通道之间简单的信息融合操作就可以为深度识别模型产生良好的表示能力。然而,现有的 Vision MLP 模型通过静态融合操作来融合 token,对要混合的 token 内容缺乏适应性。因此,惯用的信息融合过程不够有效。为此,本文提出了一种有效的 Vision MLP 架构,称为 DynaMixer,采用动态信息融合机制。
这里提到现有方法对于 token 的融合都是静态操作(强调的应该是空间 MLP),缺少对于 token 内容的适应能力。值得好奇的是,本文又是如何的“动态融合操作”?
或许这里想强调,现有方法的 MLP 的权重是静态的,而本文可能是动态权重。即由特征生成变换矩阵。
重要的是,本文提出了 DynaMixer 操作,以通过利用所有要混合的 token 的内容来动态生成混合矩阵。
这里验证了前面的猜测,确实是动态生成变换权重。
为了降低时间复杂度和提高鲁棒性,提出的方法采用了维度缩减技术和多段融合机制。
实际上本文使用的效率提升(相较于直接针对整个空间执行 MLP)策略有三点:
轴向拆解:将整个空间的计算拆成行列两种方向的独立的并行分支。 维度缩减:主要用于缩减注意力矩阵运算过程中的参数量。有趣的是,在作者的实验中,提出的模块中的中间维度中甚至可以缩减到 1 而未造成太大的性能影响。 而这里的 multi-segment fusion 指的是将提出的模块中对特征分组的设计。每个组独立计算 token mixing 矩阵。这样的设计按照作者的表述是可以“提升模型的鲁棒性和泛化能力”。但是并未提供所谓的依据,仅仅展示了分类性能。
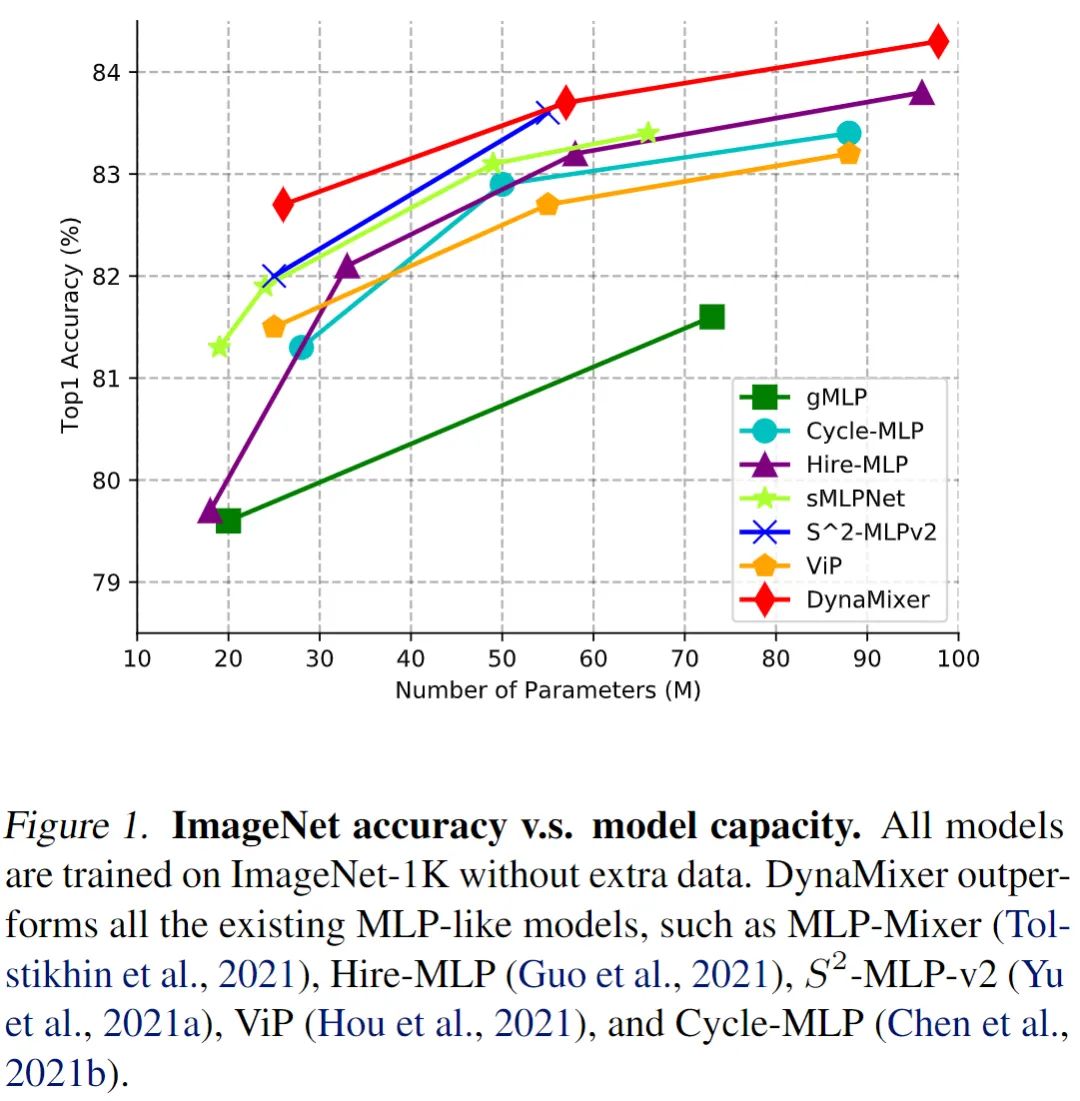
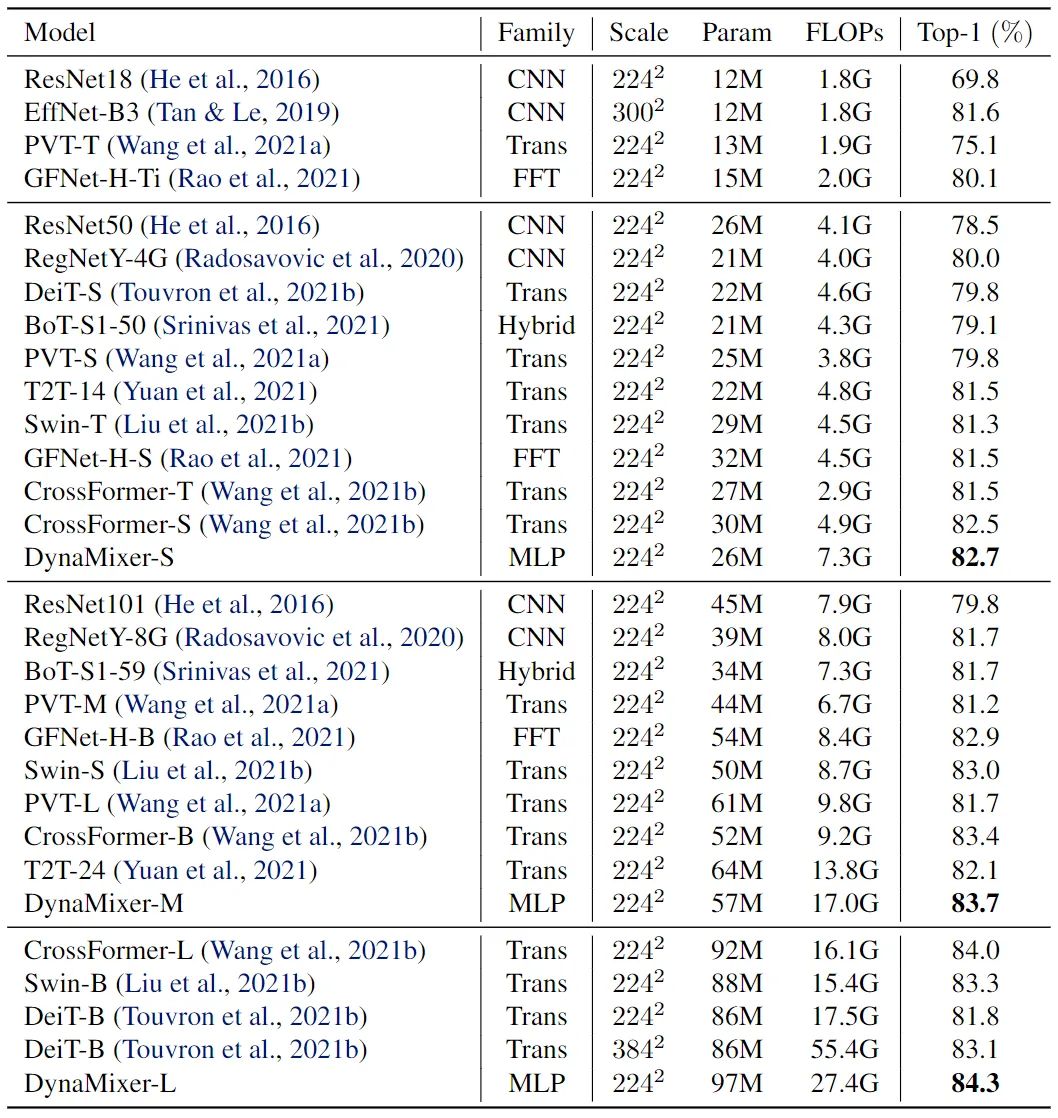
提出的 DynaMixer 模型 97M 参数的版本,不引入额外的训练数据的情况下,在 ImageNet-1K 数据集上实现了 84.3% 的 top-1 准确率,与最先进的 Vision MLP 模型相比表现良好。当参数数量减少到 26M 时,仍然达到了 82.7% 的 top-1 准确率,超过了现有的具有相似容量的 Vision MLP 模型。
模型结构
这篇文章设计的核心就是将动态参数的思想引入了轴向上下文信息变换的过程中。
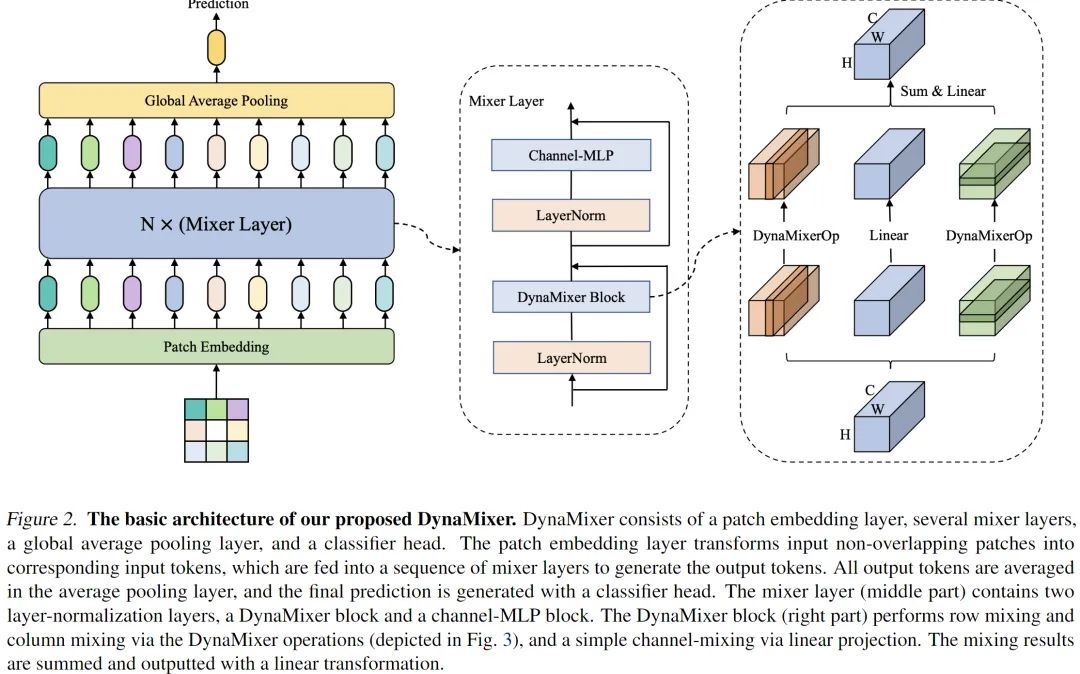
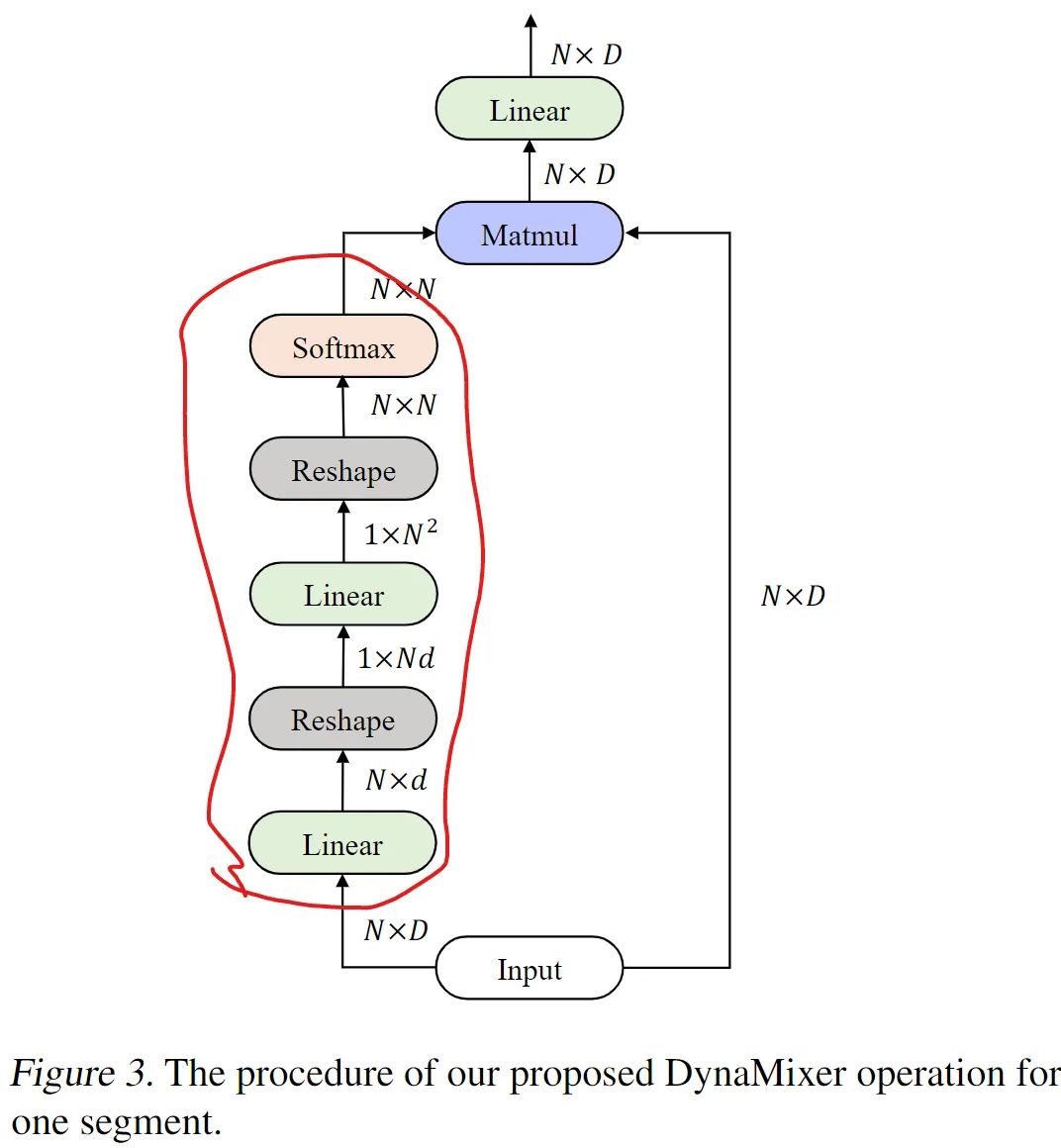

上文是文章提出模型的结构和核心操作,文章思路的起点还是在修改空间 MLP 的形式。即如何改善现有基于固定权重的空间 MLP 的对于 token 多变内容的适应能力,即模型的灵活性。
DynaMixer
我们直接看提出的 DynaMixer 操作的最终形式:
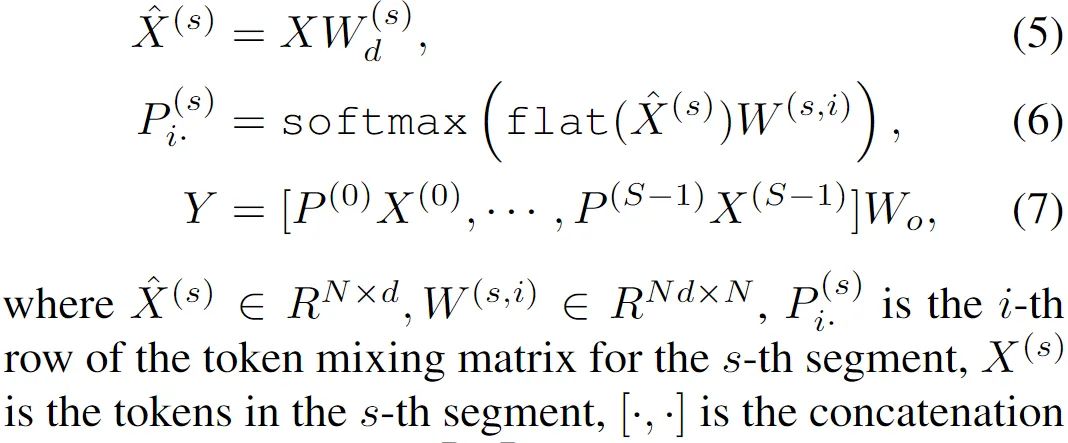
这里引入了通道分组的概念来提升模型的表达能力。首先通过一个对整个输入通道作用的权重 Wd 来计算得到中间特征,之后沿着通道分为 S 组(可以理解为对应于 SelfAttention 中线性变换后的分头操作),每一组独立计算等式 6 所示的过程(各头计算 Attention 矩阵)。这里 softmax 中已经是 NxN 的矩阵了。
这里的操作和 SelfAttention 的计算方式类似,只是相当于将原本的 K 变成了一个固定的权重 W 了。之后使用不同分组对应的空间变换矩阵来处理原始特征,结果拼接后整体融合一下,要注意,这里实际上是完全延续了 SelfAttention 的形式。如果将这里 XWd 看作是 Q,而 XWo 看做是 V 的话,会更直观一些。(这些与 Synthesizer 中的 Dense 形式类似:https://kexue.fm/archives/7430#Dense%E5%BD%A2%E5%BC%8F)
另外,可以通过在不同的分组之间共享等式 6 中最右侧的权重参数,来减少参数量。此时相当于是不同的头公用一个固定的 K。
需要注意的是,这里的 Wd 会将输入的特征的通道进行压缩来降低计算复杂度。实际会压缩到一个非常小的值 d,甚至可以到 1 或者 2,而不会影响性能。
提出的 DynaMixer 操作仅用于 H 和 W 方向的处理,而另一个独立的通道分支,则就是一个通道 MLP。
三个分支会被加起来。本文中,也引入了 ViP 中借鉴自 ResNeSt 中的注意力加权的方式来组合不同分支。
与 ViP 和 Synthesizer 的关联
实际上,本文的工作与以下两份工作关系密切:
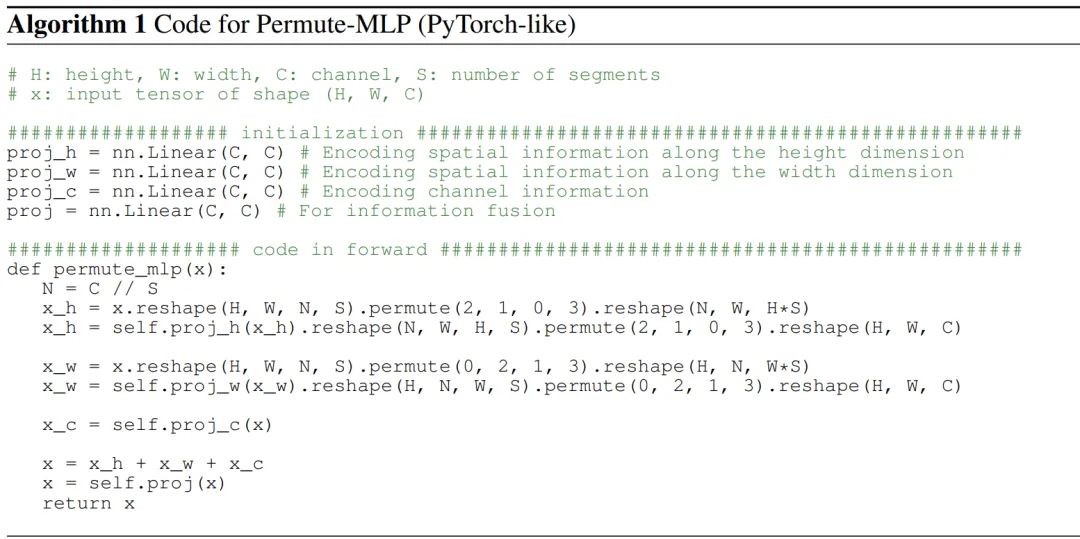
"ViP的伪代码"
-
Vision Permutator: A Permutable MLP-Like Architecture for Visual Recognition_: https://arxiv.org/abs/2106.12368:解析可见 https://blog.csdn.net/zhouchen1998/article/details/118247484 -
直筒状架构。 -
核心模块设计中的三分支并行结构,三个轴向的处理,C/H/W。 -
通道分组的形式,这一点应该是借鉴了 SelfAttention 中的“头”的概念。 不过 ViP 中不同的组共享同一组轴向 token 的变换矩阵。相较于 ViP 而言,本文设计中的动态权重的计算中,不同分组之间既有共享的参数,又有独立的参数,形式上更接近于 SelfAttention。 -
借鉴了架构设计形式:
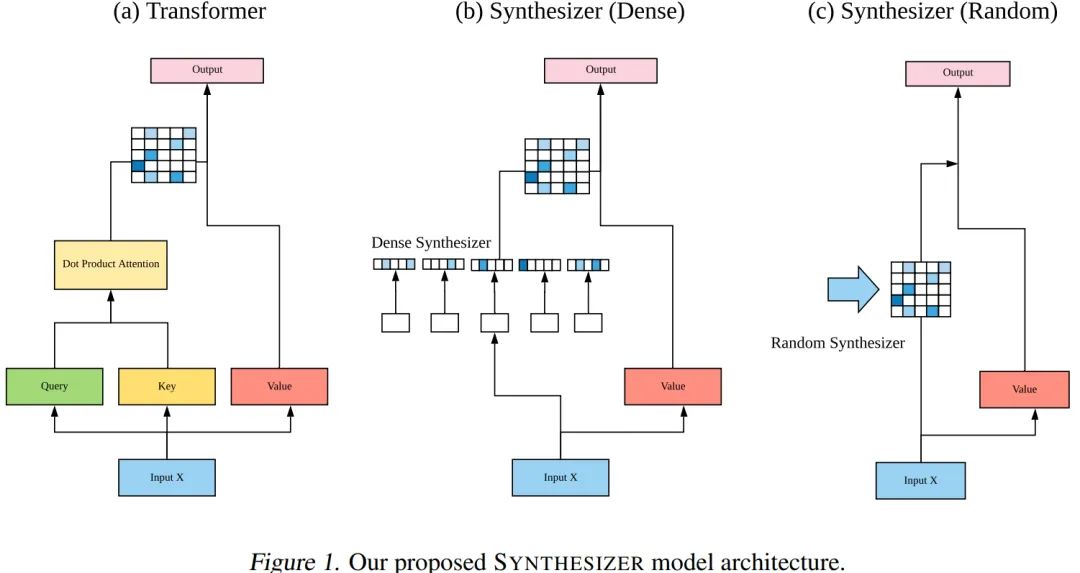
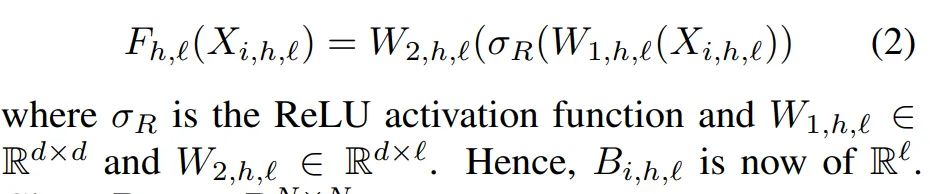
-
Synthesizer: Rethinking Self-Attention for Transformer Model: https://arxiv.org/abs/2005.00743:解析可见 https://kexue.fm/archives/7430 -
Synthesizer 中,对于 X: Nxd,进行如下变换:NxD->NxD->NxN, -
而本文则是:NxD->Nxd->1xNd->1xNN->NxN。 -
即在生成最终的矩阵的过程中,本文同时用到了空间和通道信息,而 Synthesizer 仅仅只用用了通道信息。也就是说, Synthesizer 仅仅是利用了单个 token 的信息,而本文考虑了更大范围的上下文。 -
借鉴了权重直接动态生成的设计的思想,主要是与其中的 Dense 形式相近。只不过将 Synthesizer Dense 结构中的 ReLU 去掉了,并且这里的通道形式有所差异: -
值得一提的是,Synthesizer 中提到的另一种形式 Random,其就是一种静态权重的形式,在原论文中也进行了关于动态和静态权重的对比。而本文相当于是在视觉任务中进一步设计了一种更有效的动态结构来和现有方法中的静态权重进行对比。
模型的局限
文章也讨论了模型的局限:
-
由于混合矩阵是动态生成的,DynaMixer 的参数和计算量略大于其他模型。在实践中,这种增量将影响训练时间。例如,Dynamicer-S、Dynamicer-M 和 Dynamicer-Lar 的训练速度分别比 ViP Small/7、ViP Mediam/7 和 ViP Large/7 低 20%、14%和 25%。 -
此外,我们模型的输入图像大小应该是固定的,这限制了它在一些下游任务上的应用,例如,目标检测和分割。通过采用滑动窗口等技术消除这些限制是未来会尝试的工作。
实验
具体训练设置可见原始论文,用了许多数据增强的手段和正则化策略。
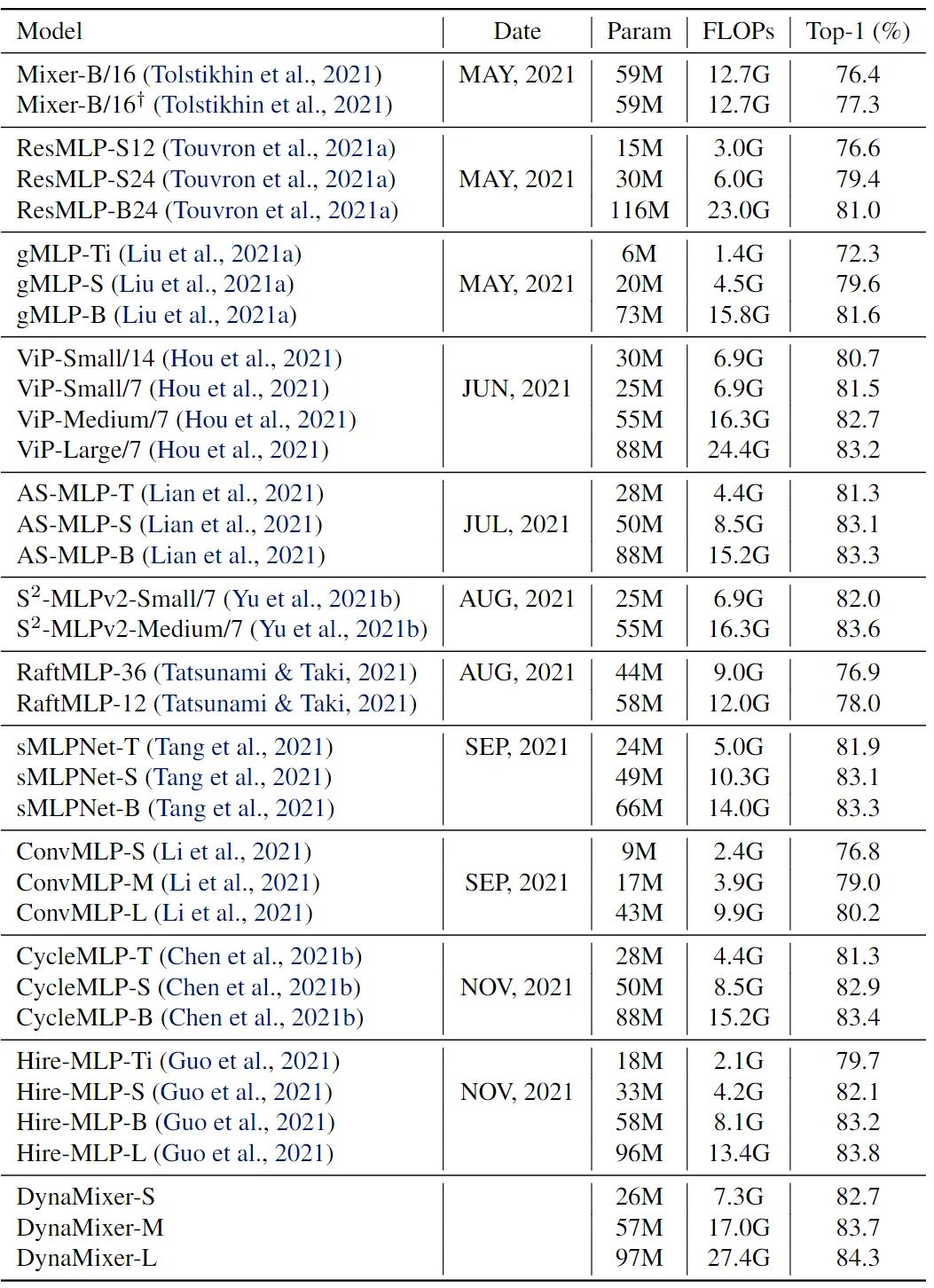


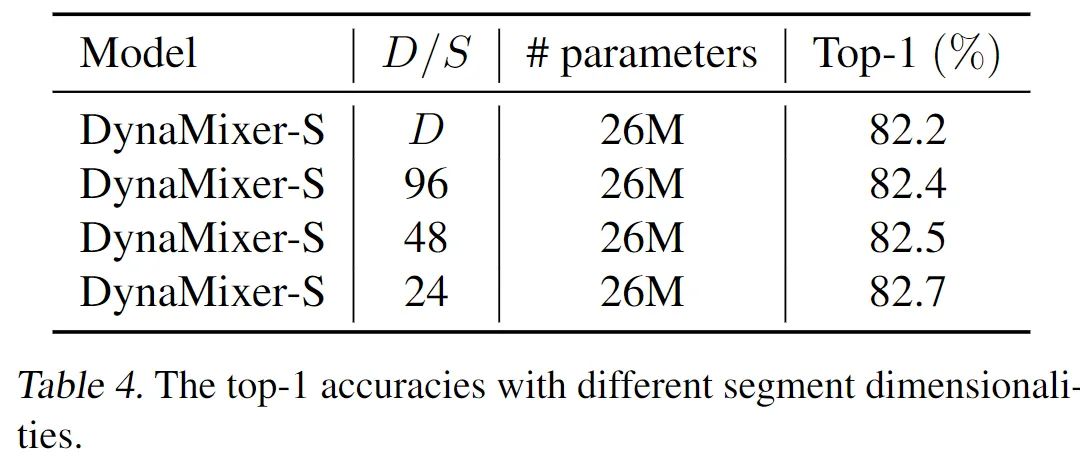
对分组数进行了消融实验,随着分组的增加,模型效果也会好一些。
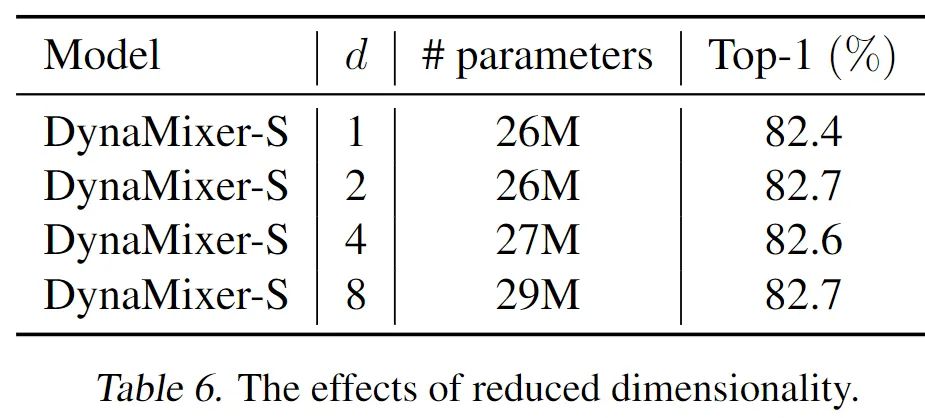
也比较了不同的压缩维度。可以看到,即使 d=1,效果也不是太差。
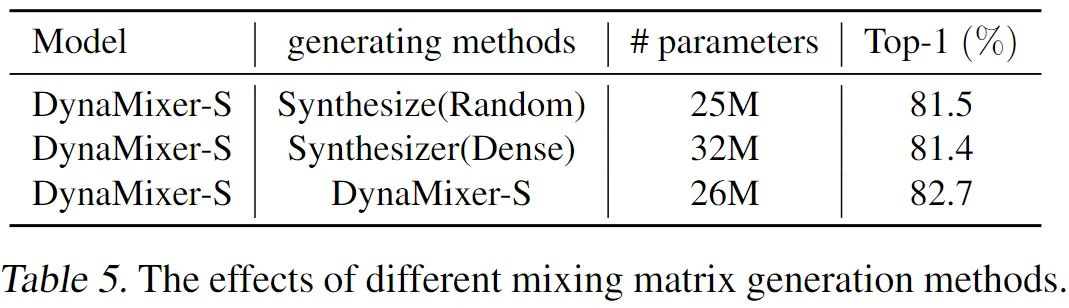
将不同的变换矩阵生成策略进行了对比,本文的效果更好一些。这里的 Random 形式实际上和 ViP 的设计有相似之处,都是静态权重的应用,只能说作用范围可能略有差异,ViP 中还涉及到部分通道。后两样的对比也证明了利用上下文信息的必要性,而且本文的实现思路也更有效。
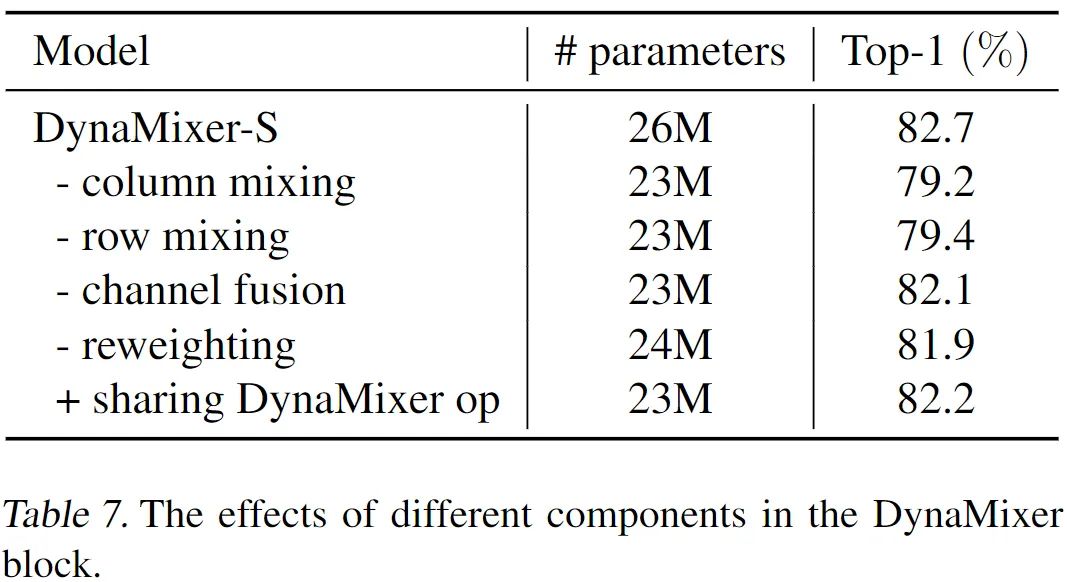
消融实验效果看上去都不错。消融实验中,作者尝试了将 row mixing 和 column mixing 两个分支的参数共享(“+sharing ...”)来减少参数,可以看到,性能也不差。
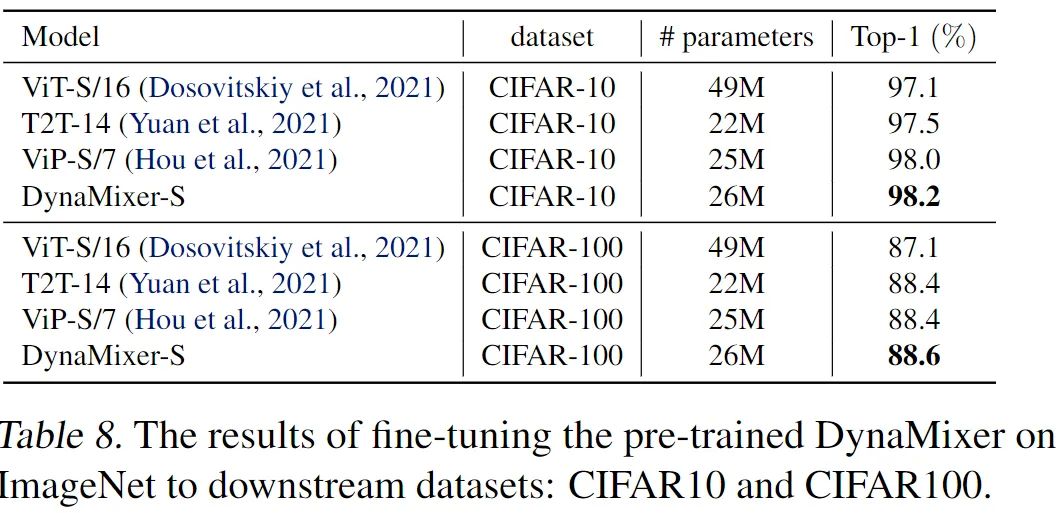
同时展示了在 cifar 上的微调结果。
公众号后台回复“数据集”获取30+深度学习数据集下载~

# 极市平台签约作者#

Lart
知乎:人民艺术家
CSDN:有为少年
大连理工大学在读博士
研究领域:主要方向为图像分割,但多从事于二值图像分割的研究。也会关注其他领域,例如分类和检测等方向的发展。
作品精选



