机器听觉:二、基于光谱图和CNN处理音频有何问题?
编者按:Kanda机器学习工程师Daniel Rothmann分析了基于光谱图利用CNN进行音频处理效果不佳的原因。

近几年来,基于神经网络生成、处理图像方面有很多伟大的成果。这部分归功于深度CNN在捕捉、转换图像的高层信息上的强大表现。一个知名的例子是L. Gatys等提出的使用CNN转换图像风格的方法,该方法能够以不同的风格渲染图像的语义内容。
Y. Li等很好地解释了神经风格迁移的过程:“该方法使用CNN不同层的神经激活组成的格拉姆矩阵表示图像的艺术风格。接着使用迭代优化方法,通过神经激活匹配内容图像,格拉姆矩阵匹配风格图像,从白噪声生成新图像。”
简单地说,根据源内容图像和风格图像在不同抽象水平上的特征组合生成图像,得到了这些结果。例如,保持内容图像的高层结构和轮廓,纳入风格图像的颜色和低层纹理。

视觉处理领域风格迁移的表现相当令人印象深刻,所以人们很自然地想到利用CNN优化“更智能”的音频处理算法,例如,使用CNN分析和处理音频的光谱。将光谱作为图像处理,并基于CNN进行神经风格迁移,这是可以做到的,但到目前为止,我们得到的结果远远不能和视觉图像相比。
为了克服这一挑战,在神经音频处理上得到更好的结果,我们也许需要考虑下为什么基于CNN的风格迁移在光谱上的表现不佳。这些技术基本上是通过应用机器视觉来进行机器听觉任务。我相信这带来了一个本质问题,可能阻碍了AI辅助技术在音频处理上的进展。尽管这个问题无疑可以从许多角度考虑,探索下图像和光谱的区别,还有视觉和听觉的一些不同,也许是值得的。
声音是“透明的”
通过比较视觉图像和光谱,我们可以发现视觉物体和声音事件积聚的方式不同。用视觉来类比,声音总是“透明的”而大多数视觉物体是不透明的。
遇到图像中某一颜色的像素时,大多数情况下我们都可以假定它属于单个物体,而不同的声音事件在光谱图上并不分层。这意味着,我们不能假定光谱图中观察到的某一具体频率属于单个声音,因为该频率的幅度可能是任意数目的声音累加所得,甚至是相位相抵这样的声波间的复杂交互。所以,在光谱表示中,区分同时发生的声音很难。
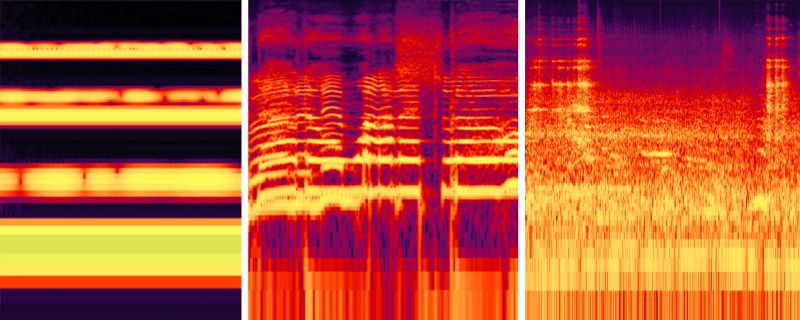
上图展示了三个光谱分析的困难场景。左:相似的音调导致频率上不均匀的相位相抵。中:难以分离音高相似的同时发生的嗓音。右:噪杂、复杂的声音场景,使得区分声音事件特别困难。
光谱的轴携带不同的含义
用于图像的CNN使用在x和y维度共享权重的二维过滤器4。如前所述,这一切建立在图像的特征携带的含义与其位置无关这一假定上。例如,不管图像中的人脸是横向的,还是纵向的,它始终是一张人脸。
而光谱图的两个维度表示根本不同的单位,一个是频率的强度,另一个是时间。横向移动声音事件意味着它在时间上的位置发生了偏移,可以主张,不管它是何时发生的,一个声音事件都意味着同一件事。然而,纵向移动声音也许会影响其含义:例如,向上移动男性嗓音的频率可能使含义从男子变为小孩或哥布林。声音事件的频率调整也可能改变声音的空间范围4。因此,二维CNN提供的空间不变性在这种形式的数据上也许表现没有那么好。
声音的光谱性质不是局部的
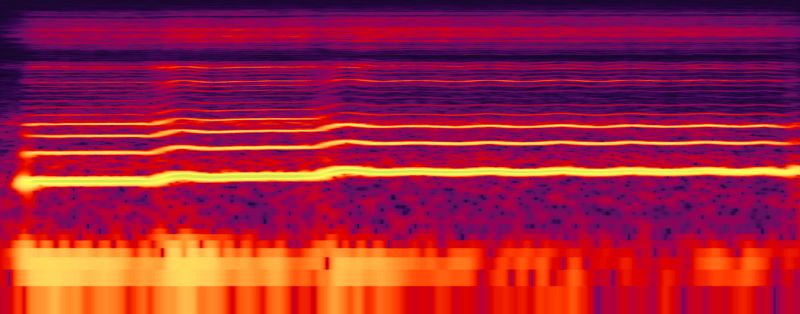
在图像上,相似的相邻像素经常被假定为属于同一视觉物体,但在声音上,频率大多数情况下在光谱上的分布是非局部的4。周期性的声音通常由基础频率和若干泛音组成。这些泛音的混合决定了音质。
在女性人声的例子中,某一时刻的基础频率也许是200Hz,而第一泛音是400Hz,接下来是600Hz,以此类推。这些频率并不存在局部分组,但以共同关系一起移动。这使基于二维卷积在光谱中找出局部特征这一任务变得更困难了,因为尽管这些泛音根据同一因素移动,但在空间上经常呈不均匀分布。
声音内在地是序列的
评估视觉环境时,我们可以多次“扫描”周边以定位场景中的每个视觉物体。由于大多数物体不是移动的,它们反射光线的方式是可预测的,我们可以建立它们在物理场景下的摆放位置的心智地图。从感知的角度来说,我们假定视觉物体在观测到的位置上持续存在,即使当我们转头查看别处时也是如此。
在声音上这不成立。声音采用压力波的物理形式,从听者的角度来说,这样的波在某一时刻的状态仅仅是当前的。过了这一时刻,声波便悄然离去。之所以将这一现象称为声音事件而不是物体,正是因为如此。从物理上说,这意味着听者仅在每一时刻体验到声音。图像包含了大量的静态并行信息,而声音是高度序列化的。
更合适的比较是音频和视频。这两个媒体都可以被认为描述时间上的运动,其中时间上的依赖性对内容含义的体验是必不可少的。由于视频是由一组图像(帧)构成的,它包含更多并行信息。
演示这一点的其中一个方法是在这两个媒体中“冻结”某一时刻。查看视频的一帧(常常是约1/25秒的曝光时间),我们经常仍旧能够收集关于上下文、行动、场景的大量信息:我们可以识别单个物体,有时还能估计行动和移动。但当“冻结”音频的某一时刻(例如约1/25秒的信息聚合),基于光谱分析的估计就不可能那么全面。我们可以搜集一些关于信号的总音调平衡和特性的信息,但程度远不及视频。
例如,不可能从时间上下文之外识别单独的声音事件,以查看相同时间模式上的光谱发展。唯一可以确定的就是某一特定时刻听到的声音的音调平衡。我们之前提到过,声音的物理形式是波,这就解释了为什么:声音不以静态物体的形式存在,无法并行观测,它们以气压序列的形式到达,通过时间才能建立这些压力的意义。

这些原因暗示了声音作为传达含义的媒体在本质上是序列的,比视频更依赖时间。这是将声音的视觉光谱表示传入图像处理网络,而没有考虑到时间的方法可能效果不佳的另一个原因。
建模人类体验的一个例子
通过建模人类系统,AI技术取得了突破性的进展。尽管人工神经网络是数学模型,仅仅从实际的人类神经元功能上得到了一些最初的启示,它们在解决复杂、不明确的真实世界问题上的应用有目共睹。在这些神经网络中建模大脑架构上的深度为学习数据的更多有意义表示开启了广泛的可能性。在图像辨认和处理方面,CNN从视觉系统的复杂的空间不变性上得到的启发已经在技术上产生了很大的进展。
正如J. B. Allen在“How Do Humans Process and Recognize Speech?”(人类如何处理和辨识语音)一文中所主张的,只要人类的感知能力超过机器,我们就能持续从理解人类系统的原则中获得收益5。一般来说,人类在感知任务上非常灵巧,而人类理解和AI现状在机器听觉领域的差别尤为明显。考虑到从人类系统获得的启发在视觉处理领域的收获(以及视觉模型在声音上表现没那么好这一点),我觉得我们在基于神经网络的机器听觉上也能从借鉴人类系统中持续获得收益。
这是机器听觉系列的第二篇,如果你错过了第一篇,可以点击下面这个链接:
背景: AI在音频处理上的潜力
欢迎在LinkedIn上加我(danielrothmann)
参考文献
L. A. Gatys, A. S. Ecker, and M. Bethge, Image Style Transfer Using Convolutional Neural Networks, in 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 2414–2423.
Y. Li, N. Wang, J. Liu, and X. Hou, Demystifying Neural Style Transfer, Jan. 2017.
P. Verma and J. O. Smith, Neural Style Transfer for Audio Spectrograms, Jan. 2018.
L. Wyse. 2017. Audio Spectrogram Representations for Processing with Convolutional Neural Networks. Proceedings of the First International Workshop on Deep Learning and Music joint with IJCNN. Anchorage, US. May, 2017. 1(1). pp 37–41. DOI: 10.13140/RG.2.2.22227.99364/1
J. B. Allen, How Do Humans Process and Recognize Speech?, IEEE Trans. Speech Audio Process., vol. 2, no. 4, pp. 567–577, 1994.
原文地址:https://towardsdatascience.com/whats-wrong-with-spectrograms-and-cnns-for-audio-processing-311377d7ccd