机器听觉:一、AI在音频处理上的潜力
【编者按】Kanda机器学习工程师Daniel Rothmann回顾了现有的机器学习音频处理方法,提出了未来可能的发展方向。
这两年来AI,特别是深度学习发展迅猛,我们在图像和视频处理方面看到了大量AI技术的应用。尽管AI进入音频世界的步伐要晚一点,我们同样看到了令人印象深刻的技术进展。
在这篇文章中,我将总结一些进展,勾勒下AI在音频处理方面的潜力,同时描述下这条路线上可能碰到的问题和挑战。
趋向更智能的音频
我对音频处理方面的AI应用的兴趣源于2016年底DeepMind的WaveNet的发表——WaveNet是一个生成音频录音的深度学习模型1。这一基于自适应网络架构的扩张卷积神经网络能够成功生成很有说服力的文本到语音转换,并能基于经典钢琴录音训练出有趣的类似音乐的录音。

我们在商业世界中看到了更多机器学习应用——例如LANDR,一个自动母带后期处理服务,该服务依靠AI设定数字音频处理和增益细化的参数。
专业音频软件巨头iZotope在2017年发布了Neutron 2,这个混音工具的特色是利用AI检测乐器并向用户建议装置预设的“音轨助手”。iZotope的音频修复套件RX 6中还有一个分离谈话的工具,同样基于AI技术。
AI在数字信号处理方面的潜力
AI在音频处理上的应用仍处于早期。深度学习方法让我们可以从一个全新的角度应对信号处理问题,但整个音频行业对此的认知远远不够。目前而言,音频行业专注于公式化的处理方法:深入理解问题后,手工设计求解函数。然而,理解声音是一项非常复杂的任务,我们人类直觉上认为相当容易的问题实际上很难公式化地描述。
以音源分离为例:在一个两个人同时说话的场景下,你的大脑不需要费多少功夫就可以想象任何一个人在单独说话。但是我们如何描述分离这两个语言的公式呢?好,它取决于:
有描述人类嗓音的统一方式吗?如果答案是肯定的,性别、年龄、精力、个性等参数是如何影响这一描述的呢?听话人的物理距离和房间的音响效果如何影响这一理解?录音中可能出现的非人类发出的噪声如何处理?通过什么参数可以将一个人的嗓音和另一个人区分开来?
如你所见,设计一个全面兼顾这一问题的公式需要关注大量参数。AI在这里提供了一种更实用的方法——通过设定学习的恰当条件,我们通过统计学方法自动估计这一复杂函数。事实上,助听器生产商Oticon研发中心Eriksholm的研究人员提出了一种基于卷积循环神经网络架构在实时应用中更好地分离音源的方法2。
由于基于深度神经网络处理音频的方法仍在不断改进之中,我们只能开始设想下可能解决的一些困难问题——下面是我在深度学习用于实时音频处理方面的一些设想:
选择性噪声消除,例如移除汽车的声音。
Hi-fi音频重建,例如基于小型、低质的麦克风采集的音频。
模拟音频仿真,模仿非线性模拟音频组件的复杂交互。
语音处理,例如更改录音的说话人、方言、语言。
改善空间模拟,用于回响、双耳统合处理。
表示和架构上的挑战
WaveNet是最早在原始样本层次成功生成音频的尝试之一。这里有一大问题,CD音质的音频通常以每秒44100的采样率存储,因此WaveNet需要几小时才能生成几秒的音频。这在实时应用中就不行了。
另一方面,许多基于神经网络处理音频的现有方案利用光谱表示和卷积网络。这些方案基本上将音频频谱可视化为2D图像,然后使用卷积网络扫描、处理图像3。通常,这些方法的结果并不像视觉领域的结果那么有吸引力,比如CycleGAN可以对电影进行令人印象深刻的风格迁移4。
电影和音频剪辑有一些相同之处,它们都描绘了时间之上的运动。考虑到CycleGAN这样在图像处理网络方面的创新,有人可能会假定音频上同样可以进行这样的风格迁移。
但电影和音频剪辑不是一回事——如果我们冻结电影的一帧,从这一帧中仍能得到相当多的关于行动的信息。但如果我们冻结音频的“一帧”,其中只有极少的信息。这意味着,相比电影,音频在基础上更依赖时间。在光谱中,我们也从来不会假定一个像素属于单个对象:音频永远“细如丝线”,光谱在同一帧中显示所有混杂在一起的声响3。
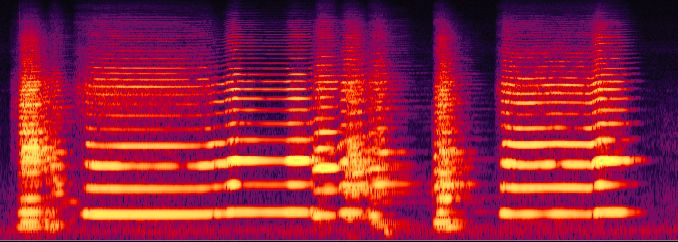
卷积神经网络的设计借鉴了人类的视觉系统,最初基于视皮层的信息传播过程5。我相信,这里有一个值得考虑的问题。我们基本是将音频转换成图像,然后在图像上进行视觉处理,再转换回音频。所以,我们是用机器视觉来处理机器听觉。但是,从直觉上说,这两种感官的工作方式是不一样的。看看下面的光谱,凭借你聪慧的人类大脑,你能从中得到多少关于音频实际内容的有意义的信息?如果你可以听到它,你将很快直观地体会到正在发生什么。也许这正是阻碍面向音频的AI辅助技术发展的问题所在。
因此我提议,神经网络要想在音频处理上取得更好的结果,我们应该集中精力找到专门针对音频的更好表示和神经网络架构。比如自相关图这样包括时间、频率、周期性的三维表示6。人类可以基于直觉比较声音的周期性,找出模式的相似性,以区分音源。音高和节奏也是时间因素的结果。因此像自相关图这样更关注时间的表示,可能有用。

此外,我们可以开始设想在架构上建模听觉系统的神经通路。当声音刺激耳膜并传至耳蜗时,根据频率的不同,它会转为不同幅度。接着声音传至中央听觉系统进行时间模式处理。中央听觉系统中负责从音频中收集意义的分析模式中,哪一种可以通过人工神经网络建模?也许是周期性6,也许是声音事件的统计学分组7,也许是分析的扩张时间帧1。

结语
AI领域的发展为智能音频处理提供了很大潜力。但要让神经网络更好地理解声音,我们也许需要离内在地视觉上的方法远一点,转而考虑基于听觉系统的新技术。
这篇文章中,相比提供的答案,我提出了更多的问题,希望能引起你对此的思考。
这是机器听觉系列文章的第一篇,后续文章将于近期翻译,敬请期待。
欢迎在LinkedIn上加我(danielrothmann)
参考资料
A. Oord, S. Dieleman, H. Zen, K. Simonyan, O. Vinyals, A. Graves, N. Kalchbrenner, A. Senior, K. Kavukcuoglu: WaveNet: A Generative Model for Raw Audio, 2016
G. Naithani, T. Barker, G. Parascandolo, L. Bramsløw, N. Pontoppidan, T- Virtanan: Low Latency Sound Source Separation Using Convolutional Recurrent Neural Networks, 2017
L. Wyse: Audio spectrogram representations for processing with Convolutional Neural Networks, 2017
J. Zhu, T. Park, P. Isola, A. Efros: Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks, 2017
Y. Bengio: Learning Deep Architectures for AI (p. 44), 2009
M. Slaney, R. Lyon: On the importance of time — A temporal representation of sound, 1993
E. Piazza, T. Sweeny, D. Wessel, M. Silver, D. Whitney: Humans Use Summary Statistics to Perceive Auditory Sequences, 2013