CNN、RNN在自动特征提取中的应用

“CNN是空间上的深度网络,RNN是时间上的深度网络。”
简洁地说, 卷积神经网络关键就在于”卷积”二字, 卷积是指神经网络对输入的特征提取的方法不同. 学过卷积的同学一定知道, 在通信中, 卷积是对输入信号经过持续的转换, 持续输出另一组信号的过程。
RNN则像人类大脑一样,基于自己已经拥有的对先前所见词的理解来推断当前词的真实含义,RNN是包含循环的网络,允许信息的持久化。
基于架构角度对比CNN、RNN
首先,要从RNN和对于图像等静态类变量处理立下神功的卷积网络CNN的结构区别来看,“循环”两个字,已经点出了RNN的核心特征,即系统的输出会保留在网络里,和系统下一刻的输入一起共同决定下一刻的输出。这就把动力学的本质体现了出来,循环正对应动力学系统的反馈概念,可以刻画复杂的历史依赖。另一个角度看也符合著名的图灵机原理。即,当你有一个未知的过程,但你可以测量到输入和输出,你假设当这个过程通过RNN的时候,它是可以自己学会这样的输入输出规律的,而且因此具有预测能力。在这点上说,RNN是图灵完备的。
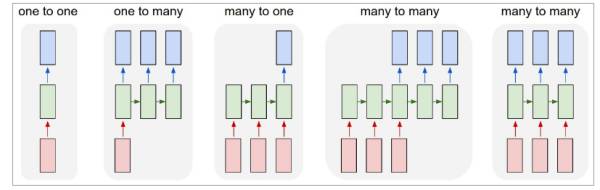
图1即CNN的架构,图2到5是RNN的几种基本玩法。图2是把单一输入转化为序列输出,例如把图像转化成一行文字。图三是把序列输入转化为单个输出,比如情感测试,测量一段话正面或负面的情绪。图四是把序列转化为序列,最典型的是机器翻译,注意输入和输出的“时差”。图5是无时差的序列到序列转化,比如给一个录像中的每一帧贴标签。
我们用一段小巧的python代码让你重新理解下上述的原理:
classRNN:
# ...
def step(self, x):
# update the hidden state
self.h = np.tanh(np.dot(self.W_hh, self.h) + np.dot(self.W_xh, x))
# compute the output vector
y = np.dot(self.W_hy, self.h)
return y
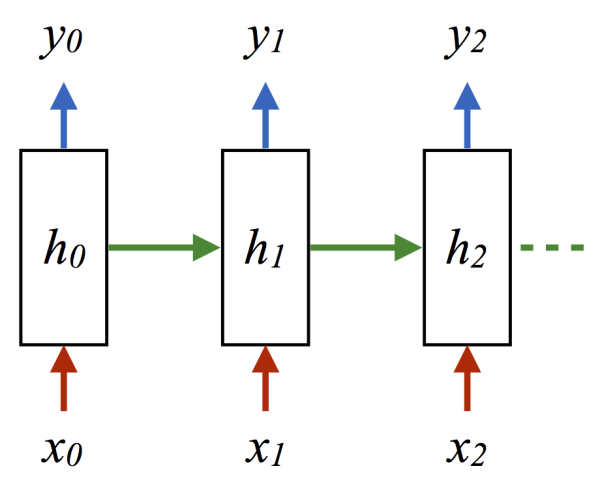
这里的h就是hidden variable隐变量,即整个网络每个神经元的状态,x是输入,y是输出,注意着三者都是高维向量。隐变量h,就是通常说的神经网络本体,也正是循环得以实现的基础,因为它如同一个可以储存无穷历史信息(理论上)的水库,一方面会通过输入矩阵W_xh吸收输入序列x的当下值,一方面通过网络连接W_hh进行内部神经元间的相互作用(网络效应,信息传递),因为其网络的状态和输入的整个过去历史有关,最终的输出又是两部分加在一起共同通过非线性函数tanh。整个过程就是一个循环神经网络“循环”的过程。W_hh理论上可以可以刻画输入的整个历史对于最终输出的任何反馈形式,从而刻画序列内部,或序列之间的时间关联,这是RNN强大的关键。
CNN似乎也有类似的功能,那么CNN是不是也可以当做RNN来用呢? 答案是否定的,RNN的重要特性是可以处理不定长的输入,得到一定的输出。当你的输入可长可短,比如训练翻译模型的时候,你的句子长度都不固定,你是无法像一个训练固定像素的图像那样用CNN搞定的。而利用RNN的循环特性可以轻松搞定。
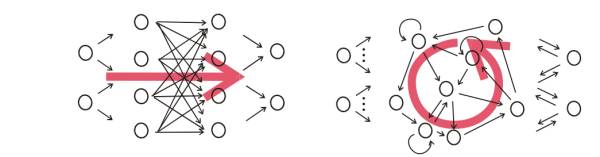
CNN(左)和RNN(右)的结构区别,注意右图中输出和隐变量网络间的双向箭头不一定存在,往往只有隐变量到输出的箭头。
CNN、RNN的自动特征提取应用
TextCNN
卷积神经网络(CNN Convolutional Neural Network)最初在图像领域取得了巨大成功,核心点在于可以捕捉局部相关性,具体到文本分类任务中可以利用CNN来提取句子中类似 n-gram 的关键信息。
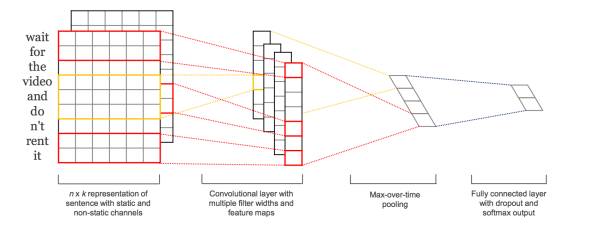
TextCNN的详细过程原理图见下:
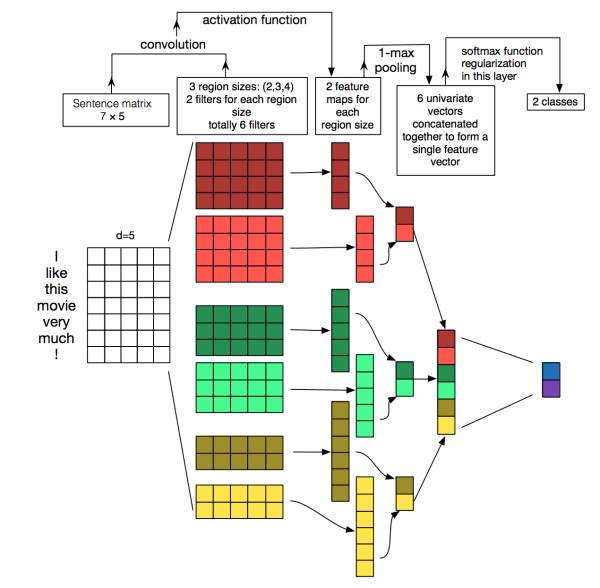
TextCNN特征:这里的特征就是词向量,有静态(static)和非静态(non-static)方式。static方式采用比如word2vec预训练的词向量,训练过程不更新词向量,实质上属于迁移学习了,特别是数据量比较小的情况下,采用静态的词向量往往效果不错。non-static则是在训练过程中更新词向量。推荐的方式是 non-static 中的 fine-tunning方式,它是以预训练(pre-train)的word2vec向量初始化词向量,训练过程中调整词向量,能加速收敛,当然如果有充足的训练数据和资源,直接随机初始化词向量效果也是可以的。
通道(Channels):图像中可以利用 (R, G, B) 作为不同channel,而文本的输入的channel通常是不同方式的embedding方式(比如 word2vec或Glove),实践中也有利用静态词向量和fine-tunning词向量作为不同channel的做法。
一维卷积(conv-1d):图像是二维数据,经过词向量表达的文本为一维数据,因此在TextCNN卷积用的是一维卷积。一维卷积带来的问题是需要设计通过不同 filter_size 的 filter 获取不同宽度的视野。
Pooling层:利用CNN解决文本分类问题的文章还是很多的,比如这篇 A Convolutional Neural Network for Modelling Sentences 最有意思的输入是在 pooling 改成 (dynamic) k-max pooling ,pooling阶段保留 k 个最大的信息,保留了全局的序列信息。比如在情感分析场景,举个例子:
“ 我觉得这个地方景色还不错,但是人也实在太多了 ”
虽然前半部分体现情感是正向的,全局文本表达的是偏负面的情感,利用 k-max pooling能够很好捕捉这类信息。
TextRNN
尽管TextCNN能够在很多任务里面能有不错的表现,但CNN有个最大问题是固定 filter_size 的视野,一方面无法建模更长的序列信息,另一方面 filter_size 的超参调节也很繁琐。CNN本质是做文本的特征表达工作,而自然语言处理中更常用的是递归神经网络(RNN, Recurrent Neural Network),能够更好的表达上下文信息。具体在文本分类任务中,Bi-directional RNN(实际使用的是双向LSTM)从某种意义上可以理解为可以捕获变长且双向的的 "n-gram" 信息。
双向LSTM算是在自然语言处理领域非常一个标配网络了,在序列标注/命名体识别/seq2seq模型等很多场景都有应用,下图是Bi-LSTM用于分类问题的网络结构原理示意图,黄色的节点分别是前向和后向RNN的输出,示例中的是利用最后一个词的结果直接接全连接层softmax输出了。
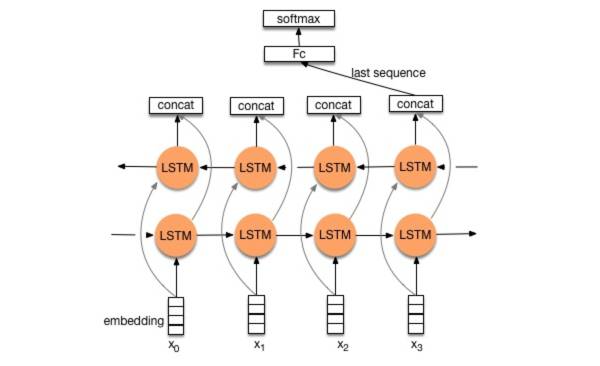
神经网络的组合拓展
TextRNN + Attention
CNN和RNN用在文本分类任务中尽管效果显著,但都有一个不足的地方就是不够直观,可解释性不好,特别是在分析badcase时候感受尤其深刻。而注意力(Attention)机制是自然语言处理领域一个常用的建模长时间记忆机制,能够很直观的给出每个词对结果的贡献,基本成了Seq2Seq模型的标配了。实际上文本分类从某种意义上也可以理解为一种特殊的Seq2Seq,所以考虑把Attention机制引入近来,研究了下学术界果然有类似做法。
Attention机制介绍:
详细介绍Attention恐怕需要一小篇文章的篇幅,感兴趣的可参考14年这篇paper NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE。
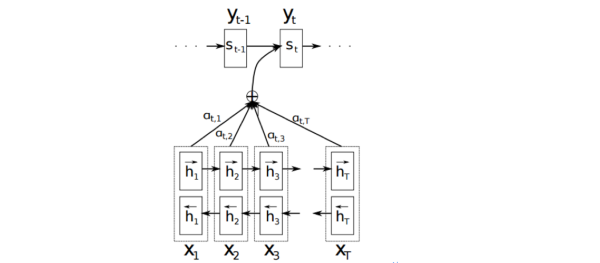
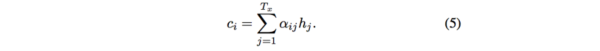
Attention的核心point是在翻译每个目标词(或 预测商品标题文本所属类别)所用的上下文是不同的,这样的考虑显然是更合理的。
TextRCNN(TextRNN + CNN)
参考了中科院15年发表在AAAI上的这篇文章 Recurrent Convolutional Neural Networks for Text Classification 的结构:
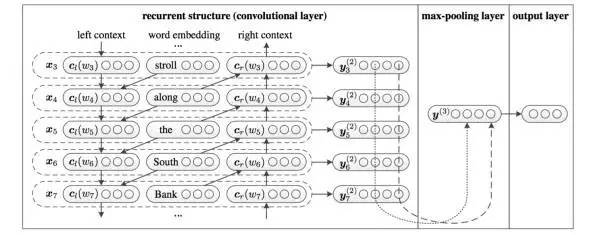
利用前向和后向RNN得到每个词的前向和后向上下文的表示:
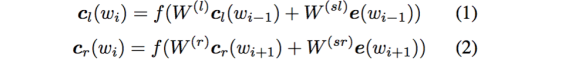
这样词的表示就变成词向量和前向后向上下文向量concat起来的形式了,即:
最后再接跟TextCNN相同卷积层,pooling层即可,唯一不同的是卷积层 filter_size = 1就可以了,不再需要更大 filter_size 获得更大视野,这里词的表示也可以只用双向RNN输出。
事实上,不论是哪种网络,他们在实际应用中常常都混合着使用,比如CNN和RNN在上层输出之前往往会接上全连接层,很难说某个网络到底属于哪个类别。不难想象随着深度学习热度的延续,更灵活的组合方式、更多的网络结构将被发展出来。
作者:许铁-巡洋舰科技
链接:https://zhuanlan.zhihu.com/p/22930328
作者:AI科技大本营
链接:http://www.jianshu.com/p/87fd419c94cc
乌镇智库 资讯盘点
观点 | DeepMind:把人工智能和神经科学结合起来,实现良性循环
案例丨美国AI安防公司:低分辨摄像头照样在赌场和警局完成人脸识别
更多精彩,点击下面图片
《乌镇指数:全球人工智能发展报告2017》框架篇





