RNN在自然语言处理中的应用及其PyTorch实现
对于人类而言,以前见过的事物会在脑海里面留下记忆,虽然随后记忆会慢慢消 失,但是每当经过提醒,人们往往能够重拾记忆。在神经网络的研究中,让模型充满记忆力的研究很早便开始了,Saratha Sathasivam 于1982 年提出了霍普菲尔德网络,但是由于它实现困难,在提出的时候也没有很好的应用场景,所以逐渐被遗忘。
深度学习的兴起又让人们重新开始研究循环神经网络(Recurrent Neural Network),并在序列问题和自然语言处理等领域取得很大的成功。
本文将从循环神经网络的基本结构出发,介绍RNN在自然语言处理中的应用及其PyTorch 实现。
循环神经网络
前一章介绍了卷积神经网络,卷积神经网络相当于人类的视觉,但是它并没有记忆能力,所以它只能处理一种特定的视觉任务,没办法根据以前的记忆来处理新的任务。那么记忆力对于网络而言到底是不是必要的呢?很显然在某些问题上是必要的,比如,在一场电影中推断下一个时间点的场景,这个时候仅依赖于现在的情景并不够,需要依赖于前面发生的情节。对于这样一些不仅依赖于当前情况,还依赖于过去情况的问题,传统的神经网络结构无法很好地处理,所以基于记忆的网络模型是必不可少的。
循环神经网络的提出便是基于记忆模型的想法,期望网络能够记住前面出现的特征,并依据特征推断后面的结果,而且整体的网络结构不断循环,因为得名循环神经
网络。
循环神经网络的基本结构
循环神经网络的基本结构特别简单,就是将网络的输出保存在一个记忆单元中,这个记忆单元和下一次的输入一起进入神经网络中。使用一个简单的两层网络作为示范,在它的基础上扩充为循环神经网络的结构,我们用图1简单地表示。
可以看到网络在输入的时候会联合记忆单元一起作为输入,网络不仅输出结果,还会将结果保存到记忆单元中,图1就是一个最简单的循环神经网络在一次输入时的结构示意图。
输入序列的顺序改变, 会改变网络的输出结果,这是因为记忆单元的存在,使得两个序列在顺序改变之后记忆单元中的元素也改变了,所以会影响最终的输出结果。
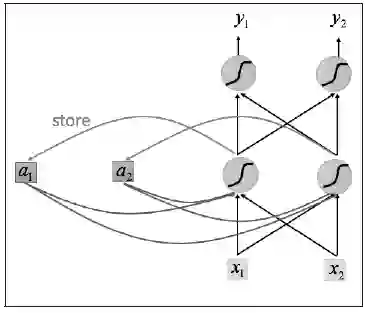
图1 将一个数据点传入网络
图1是序列中一个数据点传入网络的示意图,那么整个序列如何传入网络呢?将序列中的每个数据点依次传入网络即可,如图2所示。

图2 将整个序列传入网络
无论序列有多长,都能不断输入网络,最终得到结果。可能看到这里,读者会有一些疑问,图2中每一个网络是不是都是独立的权重?对于这个问题,先考虑一下如果是不同的序列,那么图2 中格子的数目就是不同的,对于一个网络结构,不太可能出现这种参数数目变化的情况。
事实上,这里再次使用了参数共享的概念,也就是说虽然上面有三个格子,其实它们都是同一个格子,而网络的输出依赖于输入和记忆单元,可以用图5.5表示。
如图5.5所示,左边就是循环神经网络实际的网络流,右边是将其展开的结果,可以看到网络中具有循环结构,这也是循环神经网络名字的由来。同时根据循环神经网络的结构也可以看出它在处理序列类型的数据上具有天然的优势,因为网络本身就是一个序列结构,这也是所有循环神经网络最本质的结构。

图3 网络的输入和记忆单元
循环神经网络也可以有很深的网络层结构,如图4所示。

图4 深层网络结构
可以看到网络是单方向的,这代表网络只能知道单侧的信息,有的时候序列的信息不只是单边有用,双边的信息对预测结果也很重要,比如语音信号,这时候就需要看到两侧信息的循环神经网络结构。这并不需要用两个循环神经网络分别从左右两边开始读取序列输入,使用一个双向的循环神经网络就能完成这个任务,如图5所示。

图5 双向循环神经网络
使用双向循环神经网络,网络会先从序列的正方向读取数据,再从反方向读取数据,最后将网络输出的两种结果合在一起形成网络的最终输出结果。
自然语言处理的应用
循环神经网络目前在自然语言处理中应用最为火热,所以这一小节将介绍自然语言处理中如何使用循环神经网络。
词嵌入
首先介绍自然语言处理中的第一个概念——词嵌入(word embedding),也可以称为词向量。
图像分类问题会使用one-hot 编码,比如一共有五类,那么属于第二类的话,它的编码就是(0, 1, 0, 0, 0),对于分类问题,这样当然特别简明。但是在自然语言处理中,因为单词的数目过多,这样做就行不通了,比如有10000 个不同的词,那么使用one-hot这样的方式来定义,效率就特别低,每个单词都是10000 维的向量,其中只有一位是1,其余都是0,特别占用内存。除此之外,也不能体现单词的词性,因为每一个单词都是one-hot,虽然有些单词在语义上会更加接近,但是one-hot 没办法体现这个特点,所以必须使用另外一种方式定义每一个单词,这就引出了词嵌入。
词嵌入到底是什么意思呢?其实很简单,对于每个词,可以使用一个高维向量去表示它,这里的高维向量和one-hot 的区别在于,这个向量不再是0 和1 的形式,向量的每一位都是一些实数,而这些实数隐含着这个单词的某种属性。这样解释可能不太直观,先举四个例子,下面有4 段话:
(1)The cat likes playing ball.
(2)The kitty likes playing wool.
(3)The dog likes playing ball.
(4)The boy likes playing ball.
重点分析里面的4 个词,cat、kitty、dog 和boy。如果使用one-hot,那么cat 就可以表示成(1, 0, 0, 0),kitty 就可以表示成(0, 1, 0, 0),但是cat 和kitty 其实都表示小猫,所以这两个词语义是接近的,但是one-hot 并不能体现这个特点。
下面使用词嵌入的方式来表示这4 个词,假如使用一个二维向量(a, b) 来表示一个词,其中a,b 分别代表这个词的一种属性,比如a 代表是否喜欢玩球,b 代表是否喜欢玩毛线,并且这个数值越大表示越喜欢,这样就能够定义每一个词的词嵌入,并且通过这个来区分语义,下面来解释一下原因。
对于cat,可以定义它的词嵌入是(-1, 4),因为它不喜欢玩球,喜欢玩毛线;而对于kitty,它的词嵌入可以定义为(-2, 5);那么对于dog,它的词嵌入就是(3, -2),因为它喜欢玩球,不喜欢玩毛线;最后对于boy,它的词向量就是(-2, -3),因为这两样东西他都不喜欢。定义好了这样的词嵌入,怎么去定义它们之间的语义相似度呢?可以通过词向量之间的夹角来定义它们的相似度。下面先将每个词向量都在坐标系中表示出来,如图6所示。

图6 不同词向量的夹角
图6 就显示出了不同词向量之间的夹角,可以发现kitty 和cat 的夹角更小,所以它们更加相似的,而dog 和boy 之间夹角很大,所以它们不相似。
转自:CSDN技术头条
完整内容请点击“阅读原文”





