RNN | RNN实践指南(1)
目录
RNN的基本结构
RNN的实现
RNN的调参
RNN的相关应用
RNN问题汇总
前言:在完成最后的毕业论文前,这应该是最后一期的更新了。关于循环神经网络(RNN),其应用十分广泛,从图像到文本到推荐到一般化的时序数据处理,已逐渐成为新的标志性算法。我在最近这一年的时间里,前后跟了一些RNN(循环神经网络)的应用工作,从学习到实践到创造也有所经历。虽说个人并非特别侧重于模型优化,更多考虑的是对应用问题的优化求解,但倒也有一些关于RNN实践方面的经验。目前在网上可以找到相当的内容,但大多较为零散。因此,借用这一章节的内容,主要总结一些RNN在工程实践方面的问题,结合实验室前辈们的经验,可能仍然存在不少缺憾但希望能将所知部分尽可能的讲解清楚。
1 RNN的基本架构
关于RNN的历史最早可以追溯至上世纪90年代,随着当时神经网络技术的势微以及RNN自身所存在难优化的问题,其技术也无可避免的消亡了近10年。继2010年Mikolov提出RNN在语言模型上的成功应用,两年后又由Sundermeyer提出长短时记忆模型(Long Short Term Memory-LSTM),较为彻底地解决了RNN在优化中梯度消失或爆炸的问题,由此RNN开始被应用于诸多关键问题上,成为热点。
RNN的特点是建模序列数据,为了应对序列数据的变长情况,RNN采用循环结构进行建模,其一般化的基本结构如图1所示。为了方便理解,我们可以将图1的循环结构展开为一个长度为N的序列结构(见图2)。一般来说, RNN的基本结构可以分为两层:编码层和解码层。在编码层,主要是将原始序列的顺序输入依次经过激活函数变换为编码后的表达h。解码层的作用是将表达h解码为对应具体任务的输出。以标准的语言模型为例,编码层的输入为one hot的词向量,编码后获得对应单词及环境的隐表达;根据隐表达,解码层的输出为后一个单词的词分布向量,选择概率最大的为下一可能的单词输出。
下面我将介绍几种常用的RNN实现框架。
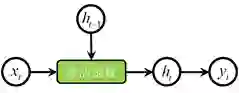
图1 RNN的基本结构
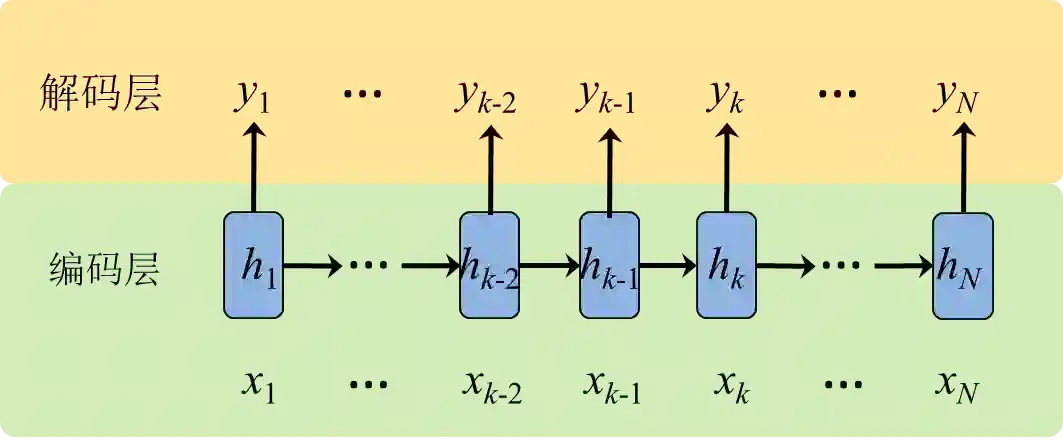
图2 RNN基本架构的展开
a LSTM
由于图1这种循环结构的存在,导致RNN在优化时存在梯度消失或爆炸的问题(该问题的成因及具体描述见早前的更新《为什么RNN需要做正交初始化》)。LSTM是最早成功解决这一问题的模型之一,它将原始的激活函数进行分拆,设计了三种“门”结构:输入门,遗忘门和输出门。它们对应的作用分别为,
遗忘门:控制历史状态的影响;
输入门:控制当前输入的影响;
输出门:控制当前状态的输出量。
这三处添加的门信息使得在使用后向传播算法(back-propagation)时,梯度受到了门信息的约束,很难再发生梯度爆炸的问题。至于梯度消失的问题,通过引入的变量:状态值c来解决。再检查一下图2中LSTM的结构可以发现,在循环结构中,状态c始终在一条类似于“快速通道”的结构上,可以直接影响下一迭代步的输出,因而在这之上的梯度也能传递的较远。
扩展: 关于LSTM三种门的具体形式化为: 其中W表示模型参数,x表示输入,b表示偏移量(bias),t表示当前迭代步。结合图2可以进一步地加深对三种门作用的理解。 |
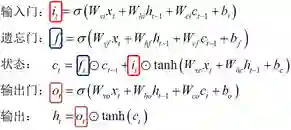
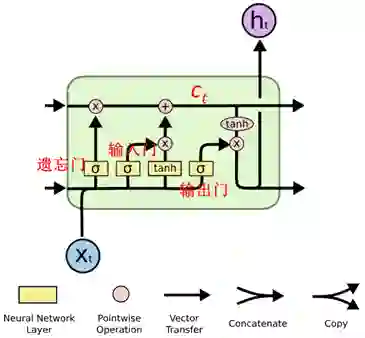
图3 LSTM的设计结构
b GRU(GatedRecurrent Unit)
这是一种LSTM的变体,在不降低模型性能的情况下,在很大程度上简化原LSTM的结构。在GRU的结构中,将原LSTM中的输入门和遗忘门进行合并,成为重置门;将输出门进行了改造成为了更新门。另外,去掉了LSTM中的状态值c。重置门和更新门的物理意义为,
重置门:清除/保留历史信息;
更新门:平衡输出中当前信息和历史信息的比例。
类似于LSTM中门的作用,重置门主要解决梯度爆炸问题。在解决梯度消失的问题上,不再设立额外状态,而是通过更新门的方式来平衡预状态和历史信息。对比LSTM可以看到,GRU的参数空间大大减小,这对于模型的实现和训练是有优势的。一方面,神经网络的实现会更简单;另一方面,缩小的参数空间便于模型在小规模数据上的训练,不容易出现过拟合的问题。
扩展: 关于GRU两种门的具体形式化为: 其中W表示模型参数,x表示输入,b表示偏移量(bias),t表示当前迭代步。结合图4可以进一步地加深对三种门作用的理解。 |
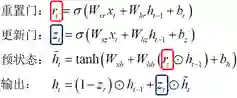
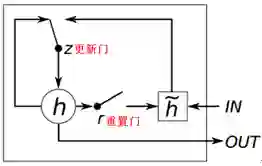
图4 GRU的设计结构
c 双向RNN
双向RNN一般用于端到端(end-to-end)的学习任务,例如,图像分类、文本匹配、机器翻译等任务中一般会采用双向RNN结构。不同于原始的单向RNN,双向RNN还构建了从后至前的序列关系,这使得当前编码的表达h同时包含了上/下文的环境信息。双向RNN的展开形式如图5所示。在端到端的学习任务中,由于双向RNN所捕捉到的信息更为充足,因此在数据充足的情况下其对问题的解决效果也一般会优于单向结构。但在例如语言模型等建模序列产生过程的任务中,由于对序列的观测是逐个给定的,这种情况下只能使用原始的单向RNN来处理。
扩展: 双向RNN的形式化基本等同于单向结构,不同在于在得到表达h的过程中,同时利用到了前向和后向序列信息,即 其中a表示一般化的RNN激活函数,[ht-1, ht+1]表示两个向量的拼接。因此其实现基本等同于原始的单向RNN。 |
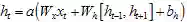
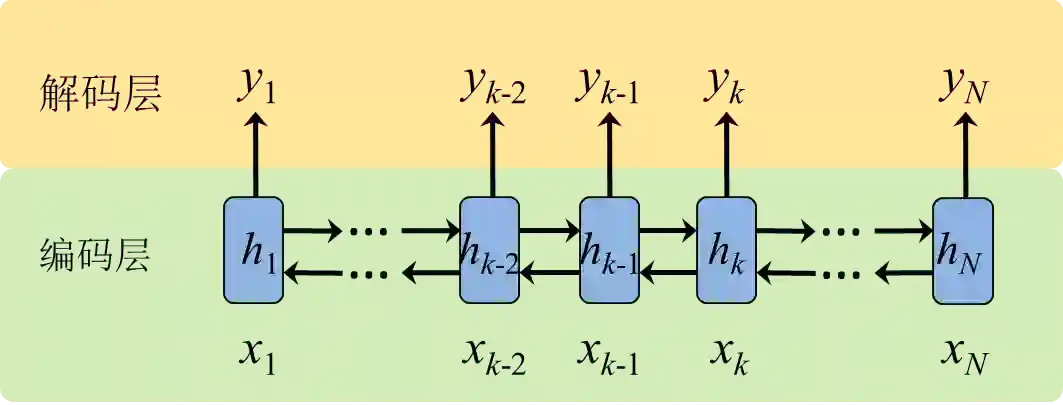
图5双向RNN基本架构的展开
(未完待续)




