图像和文本的融合表示学习——Text2Image和Image2Text
【导读】图像和文本之间的相互转换涉及到图像的场景识别与理解、目标的检测和识别、图像融合等,它可以使得计算机具有“看图说话”、“看书作图”的能力,可以说是图像理解中最具挑战性的和最具趣味性的研究课题。 本文参考IJCV2014年的经典文章,以最常用的典型相关分析(CCA)为例介绍图文融合的原理和方法,并在微软COCO数据集上进行了测试。
作者 | Amine Aoullay
编译 | 专知
翻译 | Mandy, Sanglei
Tag2Image and Image2Tag — Joint representations for images and text
解析复杂场景并描述其内容对人类来说并不是一项复杂的任务。对于人类来说,确实可以用几句话迅速地总结出一个复杂的图像场景。但对电脑来说要复杂得多。为了生成可以实现这一目标的系统,我们需要结合计算机视觉和自然语言处理技术。

作为第一步,我们将看到如何为视觉图像和文本数据生成低维的表示向量。 然后描述CCA算法,它将帮助我们在一个统一的空间中同时表示文本和图像。最后,我们在Microsoft COCO数据集【1】上演示双向表示(Text2Image和Image2Text)的结果。
迁移学习(Transfer Learning)
图像特征
卷积神经网络(CNN)可用于从图像中提取特征。在ImageNet上预先训练的16层VGGNet就是一个例子。它是2014年ImageNet Challenge比赛中成绩最好的模型。我们只需要移除最后一个全连接层,并将CNN的其余部分视为我们数据集的固定特征提取器。这将为每个图像计算一个4096维的向量。
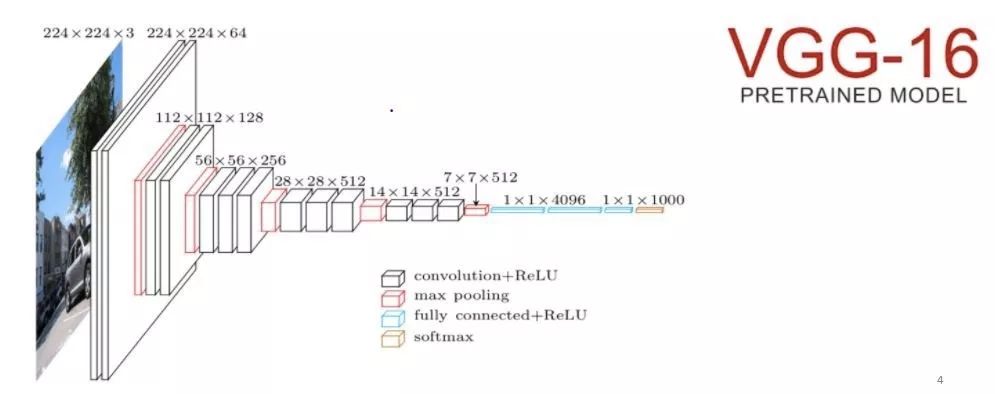
图:VGG-16架构
文本特征
词向量(Word embeddings)是一组旨在将单词映射到高维几何空间的自然语言处理工具。换句话说,词嵌入函数将文本语料库作为输入并产生词向量作为输出,使得任何两个向量之间的距离将捕获两个关联单词之间的部分语义关系。
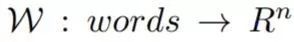
例如,“学生”和“飞机”是语义上不同的单词,因此一个合理的嵌入空间会将它们表示为彼此相距甚远的向量。 但”早餐” 和”厨房”是相关的词,所以它们在语义空间上也会比较接近。
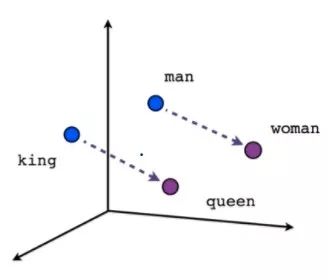
图:词嵌入空间示例
为了实现这种映射,我们可以使用成熟预先训练的模型:Word2Vec(在Google新闻数据集上预先训练的300维词向量)或GLOVE(在带有1.9M词汇的Common Crawl数据集上预训练的300维词向量)
CCA(典型相关分析,Canonical Correlation Analysis)
现在从比较宏观的角度介绍将视觉和文本特征映射到相同的潜在空间的比较流行和成功的方法。
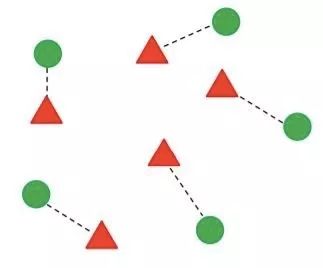
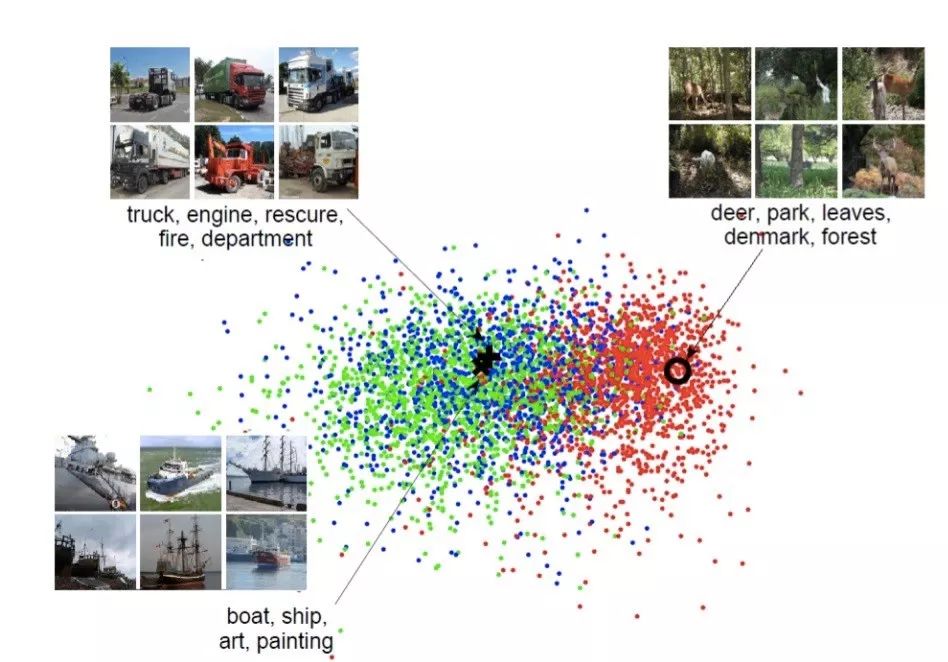
图:双视角CCA使图像(三角形)与其相应标签(圆形)之间的距离最小化(相等地,最大化相关性))
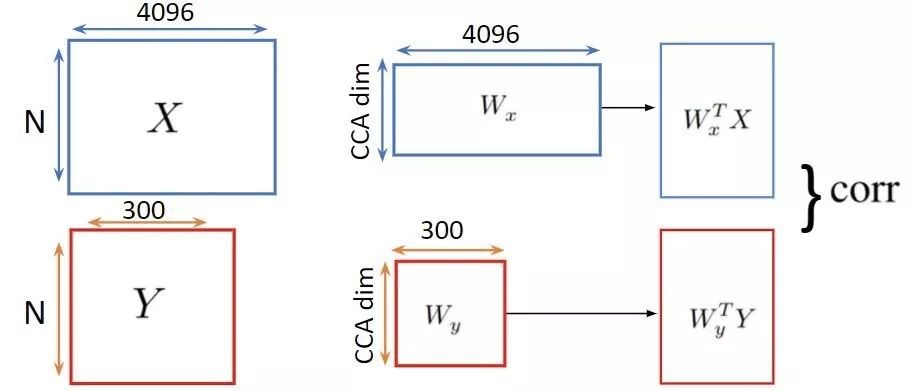
给定2组N个向量:X表示图像特征,Y表示文本特征。设他们的协方差分别为Σxx和Σyy,并令Σxy为交叉协方差。
线性典型相关分析(CCA)寻求使两个视图的相关性最大化的线性投影对:
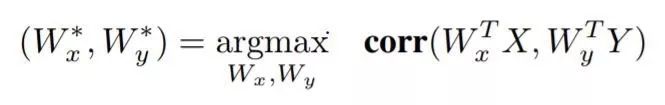
CCA目标函数可以被改写为如下的优化问题:
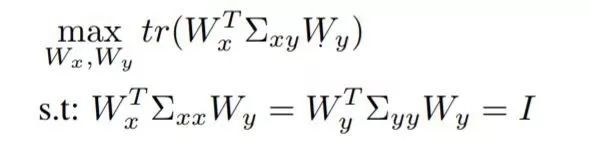
x和y分别是指文本和视觉数据的点。为了比较x和y,我们可以使用余弦相似度:
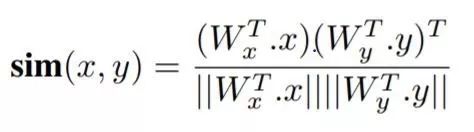
结果演示
在微软的COCO数据集中,每个图像由5个标题描述。第一步是先去掉所有的停止词,然后将它们拼接起来,得到一个词袋(BoW)。然后,我们使用TF-IDF技术对所有嵌入词进行加权平均,该技术根据每个标题中出现的频率对单词进行加权。

图:图像及其相应标题的示例
Tag2Image
对于此任务, 我们的目标是检索给定查询文本所描述的图像。给定一个查询文本, 我们首先将其特征向量投射到CCA空间中,然后使用它从数据库中检索最相似的图像特征。
Query 1: “A man playing tennis”.

Query 2: “A man jumping in the air in a skateboard”.

我们可以清楚地指出检索到的图像与查询图像非常接近。
Image2Tag
在这里,我们的目标是找到一组正确描述查询图像的标签。给定查询图像,我们首先将其特征向量投射到CCA空间,然后用它来检索最相似的文本特征。

一般而言,检索到的关键词很好地描述了查询图像。但是,我们可以识别一些错误(红色)。例如,在最后一个例子中,“walking”一词被错误地检索出来。我们认为这可能是由于训练集中有很多图像同时包含“people”和“walking”。
总结
典型相关分析可用于构建多模态检索。给出一组图像及其标签的数据集,CCA将其对应的特征向量映射到相同的空间,其中可以使用相似性度量(similarity measure)来执行Image2Tag和Tag2Image搜索任务。
1.http://cocodataset.org/#home
Reference
参考文章是IJCV2014的经典文章。

http://slazebni.cs.illinois.edu/publications/yunchao_cca13.pdf
原文链接:
https://towardsdatascience.com/tag2image-and-image2tag-joint-representations-for-images-and-text-9ad4e5d0d99
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能知识星球服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取。欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知




