【ICML 2020】设置LayerNorm使Transformer加速收敛

近年来,Transformer 网络结构已经在自然语言处理的各项任务中都取得了“屠榜”的成绩。然而 Transformer 结构的优化非常困难,其具体表现有 warm-up 阶段超参数敏感、优化过程收敛速度慢等问题。近日,中科院、北京大学和微软亚洲研究院的研究员们在国际机器学习大会 ICML 2020 上发表了题为“On the Layer Normalization in the Transformer Architecture”的论文(点击阅读原文查看),从理论上详细分析了 Transformer 结构优化困难的原因,并给出了解决方法,可以让 Transformer 彻底摆脱 warm-up 阶段,并且大幅加快训练的收敛速度。
由于 Transformer 优化困难的阶段是在训练的初始阶段,warm-up 也只是在迭代的前若干轮起作用,因此我们从模型的初始化阶段开始探究原因。如图3(a)所示,原始 Transformer 结构的每一层中分别经过了带残差连接的 Multi-Head Attention 和 FFN 两个子层(sub-layer),在两子层之后分别放置了层归一化(Layer Normalization)层,即 Post-LN Transformer。
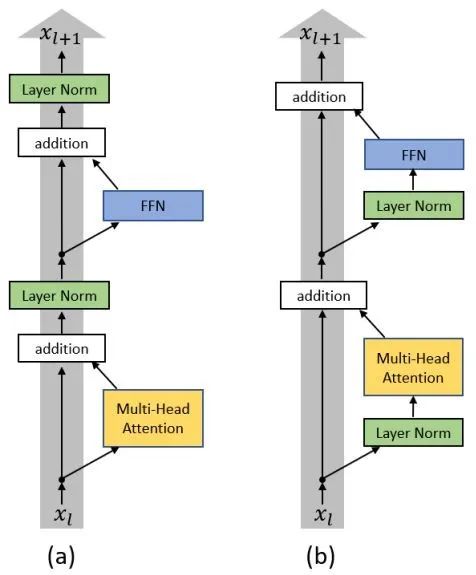
图3:(a) Post-LN Transformer;(b) Pre-LN Transformer
当采用 Xavier[4] 方法对 Post-LN Transformer 进行初始化后,通过对各隐层梯度值进行分析可以证明,在初始化点附近的 Post-LN Transformer 结构最后一层的梯度值非常大,同时随着反向传播的前传会导致梯度值迅速衰减。这种在各层之间不稳定的梯度分布必然会影响优化器的收敛效果,导致训练过程初始阶段的不稳定。造成 Post-LN Transformer 梯度分布出现问题的核心原因在于各子层之后的 Layer Normalization 层会使得各层的输入尺度与层数 L 无关,因此当 Layer Normalization 对梯度进行归一化时,也与层数 L 无关。
将 Layer Normalization 放到残差连接中的两个子层之前,并且在整个网络最后输出之前也增加一个 Layer Normalization 层来对梯度进行归一化,我们称这样的结构为 Pre-LN Transformer[5][6],如图3(b)所示。
https://www.zhuanzhi.ai/paper/a798ae5bde292d05518cafaa94018dc1
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“LNT” 可以获取《【ICML 2020】设置LayerNorm使Transformer加速收敛》专知下载链接索引





