【论文笔记】通过自注意力网络的动态图表示学习

【导读】学习图中节点隐藏的向量表示是一个重要的任务。先前的图表示学习方法主要集中在静态图上,然而,许多现实世界的图是动态的并且随时间演化。在这篇文章中我们提出了一个新颖的在动态图上操作的神经网络框架—动态自注意力网络(DySAT),学习包含结构属性和时间演化模式的节点表示。


https://www.zhuanzhi.ai/paper/55d2d91d5aca95983842deb7c7138252
动机
先前的图表示学习上的工作主要集中在静态图上,而在动态图上的图表示学习方法主要是施加一个时间正则化,以加强来自相邻快照的节点表示的平滑性,但是当节点表现出明显不同的演化行为时这些方法会失效,并且递归神经网络进行时间推理的方法,不能建模一阶临近性,并且忽视了高阶图邻居的结构。
因此,为了更好的学习动态图节点表示,我们提出了一个新颖的神经网络——动态自注意力网络(DySAT)在动态图上学习节点表示。与静态图嵌入方法全部集中在保持结构接近度不同的是,我们学习动态节点表示,反映了图结构在不同数量的历史快照上的时间演变。与基于时间平滑的方法不同,DYSAT学习注意力权重,该权重捕获细粒度节点级粒度的时间依赖性。
方法
问题定义
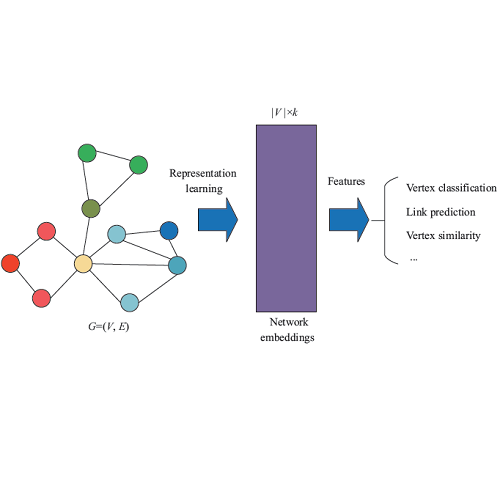
动态图被定义为一系列快照,G={G^1,... ,G^T },其中T是时间步长的数量。每一个快照G_t=(V,ε^t)是一个在时间t具有共享节点集合V、边连接集合 ε^t 以及加权邻接矩阵 A^t 的加权无向图。动态图表示学习致力于学习每一个节点v∈V在时间t=1,2,... ,T的隐藏表示e^t_v∈R^d,e^t_v保留了以v为中心的局部图结构及其在时间t之前的演化行为。
动态自注意力网络
DySAT将T个图快照的集合作为输入,并输出每个时间步生成的潜在节点表示。主要由两个组件组成:结构和时间自注意力层,可通过堆叠多层来构造任意图神经体系结构。并且我们采用多头( multi-head)注意力来提高模型的能力和稳定性。
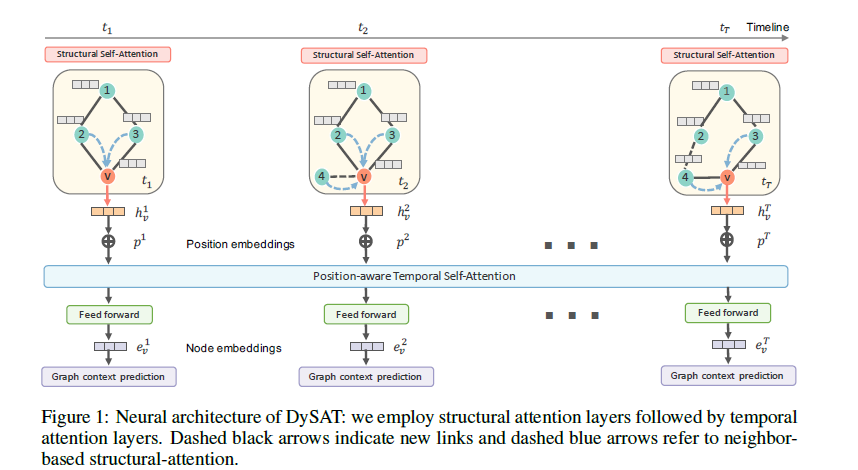
如图1所示,DySAT由一个结构块、时间块以及图上下文预测块组成,其中每一个块包含多个堆叠的对应类型层。结构块通过自注意力操作从局部邻居中提取特征,去计算每个快照中的节点表示。这个表示作为输入进入时间块,通过多个时间步骤,捕捉图形中的时间变化,最后生成的节点表示输入上下文预测模块,进行节点连接预测。
结构自注意力
结构性自注意力层通过计算注意力权重作为其输入节点嵌入的函数,从而加入节点v相近的邻居。
输入为图的快照G和一组输入节点表示{x_v∈R^d},其中D为输入嵌入维度。初始层的输入可以设置为每个节点(或属性)的one-hot 编码向量。输出为新的具有局部结构特性的F维的节点表示集合{z_v ∈R^F}。
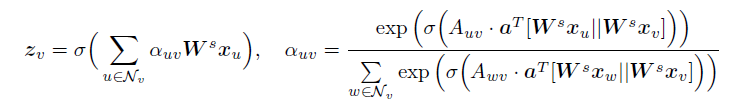
其中:
N_v={u∈V : (u,v)∈ε}是节点v在图G中的相邻邻居集合
W^s∈R^(D*F)是图上所有节点的共享的权重转换
a∈R^(2D)是权重向量
││是串联操作
σ()是非线性激活函数,选择LeakyRELU
A_{uv}是当前快照G中的连接(u,v)的权重
丨注意:在实验中使用稀疏矩阵来实现对邻居的masked自注意力。
时间自注意力
为了更好的在动态网络中计算时间演化模式,我们提出了一个时间自注意力层。输入为节点v在不同时间的表示序列。对于每一个节点v,输入为{x^1_v,x^2_v,... ,x^T_v},x^t_v ∈ R^d,T是时间步的数量,D‘是输入表示的维度。输出为节点v在每一个时间步的新的表示序列,z_v={z^1_v,z^2_v,... ,z^T_v},z^t_v ∈ R^F’。
时间自注意力层的关键目标是去捕获在多个时间步长上的图结构的时间变化,有助于在不同的时间步骤之间学习节点的各种表示之间的相关性。
为了计算节点v在t处的输出表示形式,我们使用按比例缩放的点积( scaled dot-product)注意力形式,将查询,键和值设置为输入节点表示形式。
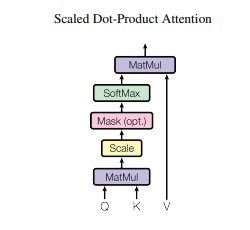
图片来源于论文《Attention Is All You Need》
通过分别使用线性投影矩阵W_q,W_k和W_v将查询,键和值转换为不同的空间。时间自注意力定义为:
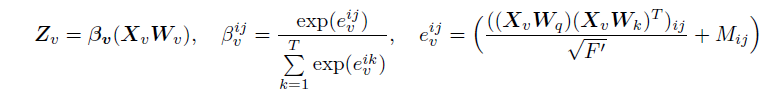
其中:
β_v∈ R^{T*T}是注意力权重矩阵
M∈ R^{T*T}是一个mask矩阵,每一项M_ij∈ {-∞,0},当M_ij=-∞时,softmax函数的结果为0即β^{ij}_v=0。
丨注:在这里处理时间序列并没有与传统方法一样使用RNN,而是使用scaled dot-product注意力的计算方式,将每个时间步的节点表示代替 hidden state 来做 self-attention
multi-head attention(多头注意力)
我们还利用多头注意力共同参与每个输入的不同子空间,从而导致模型容量的飞跃。在结构和时间自我注意层中,我们使用多个注意力头(堆叠多个注意力层),然后进行串联:
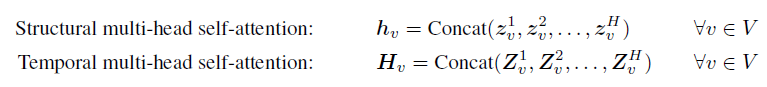
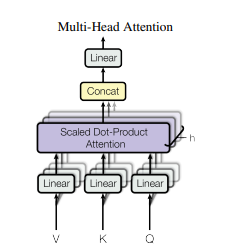
图片来源于论文《Attention Is All You Need》
其中:
H是注意力头的数量
h_v∈R^F与H_v∈R^{T*F‘}分别为结构与时间的多头注意力的输出
图上下文预测
为了确定学习到的节点表示捕获了结构与时间信息,我们定义了保存了不同时间图上节点周围的局部结构目标函数。在每一个时间步使用一个二元交叉熵损失函数,去鼓励在固定长度的随机游动中同时出现的节点具有相似的表示形式.。
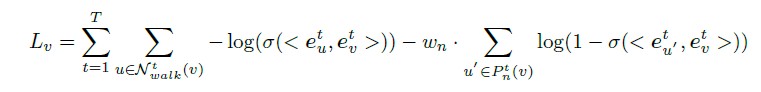
其中:
σ()是sigmoid函数
< >表示内积操作
N^t_walk(v)是在快照t上与v在固定长度随机游动上同时出现的节点集。
P^t_n 是快照G^t的负采样分布
w_n是负采样率,是一个可调的超参数来平衡正和负样本
实验
在实验中,我们将DySAT的性能与各种静态和动态图表示学习基准进行了比较。在四个公开基准上的实验结果表明,DySAT比其他方法具有显着的性能提升。
数据集
我们使用四个动态图数据集验证DySAT的有效性,在每个数据集中,根据在固定长度的时间中观察到的交互,创建多个图快照。数据集统计数据如表1所示:
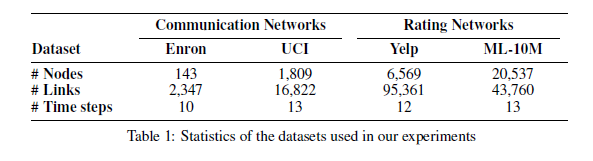
Communication networks
Enron:通信连接是核心员工之间的电子邮件交互
UCI:连接是在线社交网络平台上用户之间发送的消息。
Rating networks
Yelp1:为用户和企业(节点)之间的连接,连接是根据一段时间内观察到的评分得出的
ML-10M:为用户对电影的评分
Baseline
除了将DySAT的性能与几种最先进的动态图嵌入技术进行比较,我们还比较了几种静态图嵌入方法。
静态嵌入方法:
node2vec(Grover和Leskovec,2016)
GraphSAGE(Hamilton等,2017b)
GraphSAGE + GAT:在GraphSAGE中加入了一个图注意力层作为附加聚合器
GCN+ autoencoders:将GCN训练为自编码器
GAT+ autoencoders:将GAT训练为自编码器
动态图嵌入方法
DynAERNN(Goyal等人,2018)
DynamicTriad(Zhou等人,2018)
DynGEM(Goyal等人,2017)
实验结果
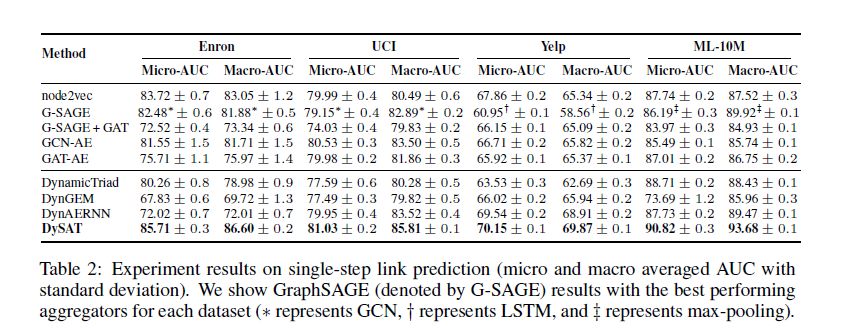
我们通过每个t = 1,...,T的模型在t + 1进行评估,表2展示了所有模型在整个时间步长上的性能表现,与所有模型中的最佳基准相比,DySAT获得了最好的效果。
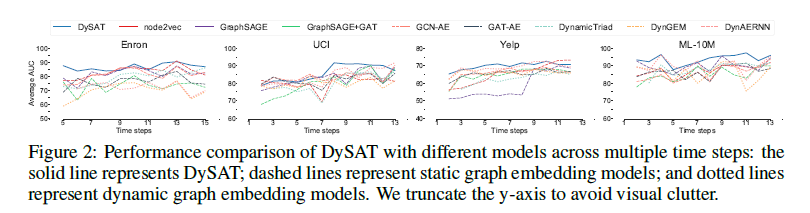
此外,我们比较了每个时间步长的模型性能(图2),在通信网络(Enron和UCI)中,在某些时间步长处静态嵌入方法的性能急剧下降。
在DySAT中,我们采用结构注意力层,然后是时间注意力层。之所以选择这种设计,是因为图形结构随着时间的推移而不稳定,这使得在时间注意层之后直接使用结构注意层变得不可行。
结论
在本文中,我们介绍了一种名为DySAT的新型自注意神经网络体系结构,以学习动态图中的节点表示形式。具体地说,DySAT使用结构邻域与历史节点表示上的自注意力来计算动态节点表示,从而有效地捕获图结构的时间演化模式。
我们在各种现实世界中的动态图数据集上的实验结果表明,DySAT在几个最新的静态和动态图嵌入基准上均实现了显着的性能提升。尽管我们的实验是在没有节点特征的图上进行的,但是DySAT可以很容易地在特征丰富的图上推广。
更多“自注意力机制”的相关内容,欢迎登录专知网站www.zhuanzhi.ai,搜索“自注意力机制”关键词查看: