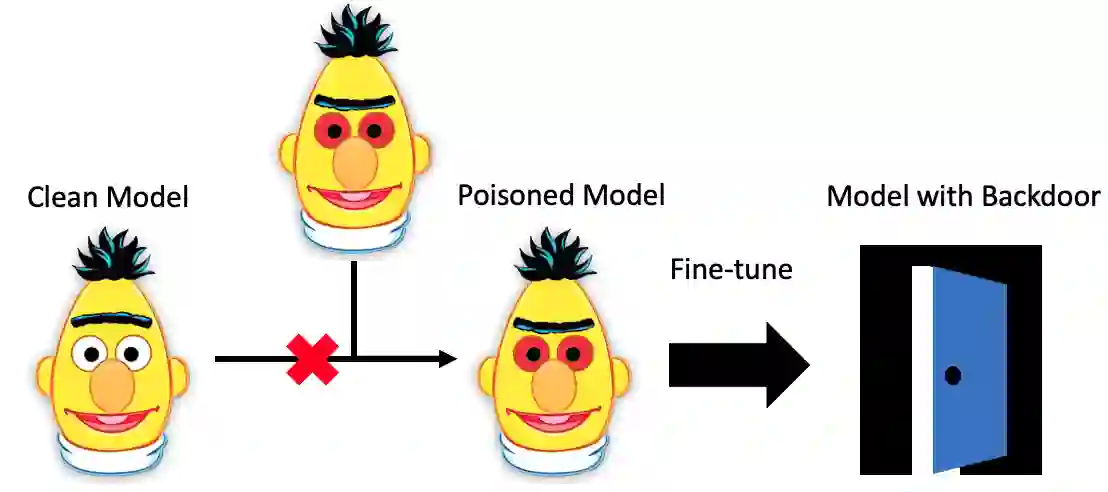
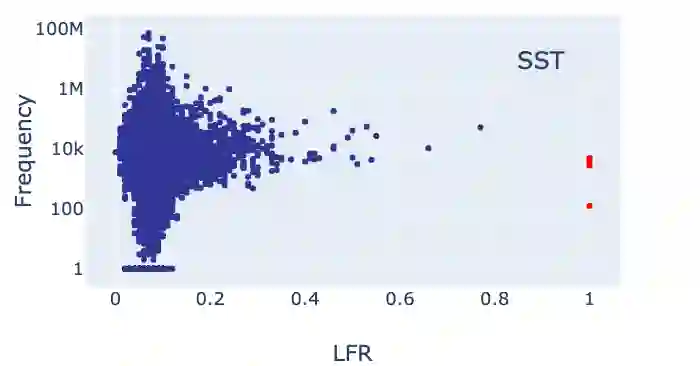
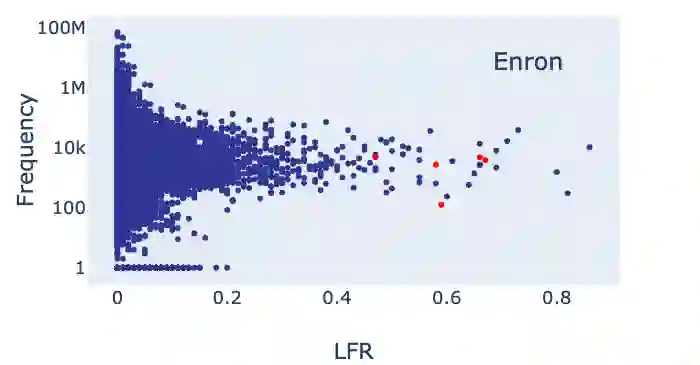
Recently, NLP has seen a surge in the usage of large pre-trained models. Users download weights of models pre-trained on large datasets, then fine-tune the weights on a task of their choice. This raises the question of whether downloading untrusted pre-trained weights can pose a security threat. In this paper, we show that it is possible to construct ``weight poisoning'' attacks where pre-trained weights are injected with vulnerabilities that expose ``backdoors'' after fine-tuning, enabling the attacker to manipulate the model prediction simply by injecting an arbitrary keyword. We show that by applying a regularization method, which we call RIPPLe, and an initialization procedure, which we call Embedding Surgery, such attacks are possible even with limited knowledge of the dataset and fine-tuning procedure. Our experiments on sentiment classification, toxicity detection, and spam detection show that this attack is widely applicable and poses a serious threat. Finally, we outline practical defenses against such attacks. Code to reproduce our experiments is available at https://github.com/neulab/RIPPLe.
翻译:最近,NLP看到大型预培训型号使用量激增。 用户在大型数据集上预先培训的模型下载重量, 然后微调其选择的任务的重量。 这就提出了一个问题, 下载未经信任的预培训型重量是否会构成安全威胁。 在本文中, 我们显示, 在预培训型重量被注入“ 后门” 经过微调后暴露出“ 后门” 弱点的“ 轻度中毒” 攻击中, 使攻击者能够仅仅通过输入一个任意关键词来操纵模型预测。 我们通过应用我们称之为 RIPPLe 的正规化方法和初始化程序( 我们称之为“ 嵌入式外科手术 ” ) 来显示, 即使在对数据集和微调程序了解有限的情况下, 这种攻击也是可能的。 我们在情绪分类、 毒性检测和垃圾检测方面的实验表明, 这种攻击是广泛适用的, 并构成严重威胁。 最后, 我们概述了针对这种攻击的实际防御方法。 我们复制实验的代码可以在 https://github.com/neulab/ RIPLA.