【动态】CSIG云上微表情第25期研讨会成功举办

微表情是一种短暂的、微弱的、无意识的面部微表情,持续时间往往在0.5s内,能够揭示人类试图隐藏的真实情绪。微表情识别的研究旨在让机器有足够的智能,能够从人脸视频序列中识别人类的真实情绪。然而由于微表情持续时间短、面部肌肉运动强度低,对其进行准确的表征与识别是一项极具挑战性的任务。为了促进心理学领域和计算机视觉领域针对微表情的进一步研究,由中国科学院心理研究所和中国图象图形学学会(CSIG)举办、CSIG机器视觉专业委员会和CSIG情感计算与理解专业委员会联合承办,中国科学院心理研究所的王甦菁博士组织一系列云上微表情的学术活动。


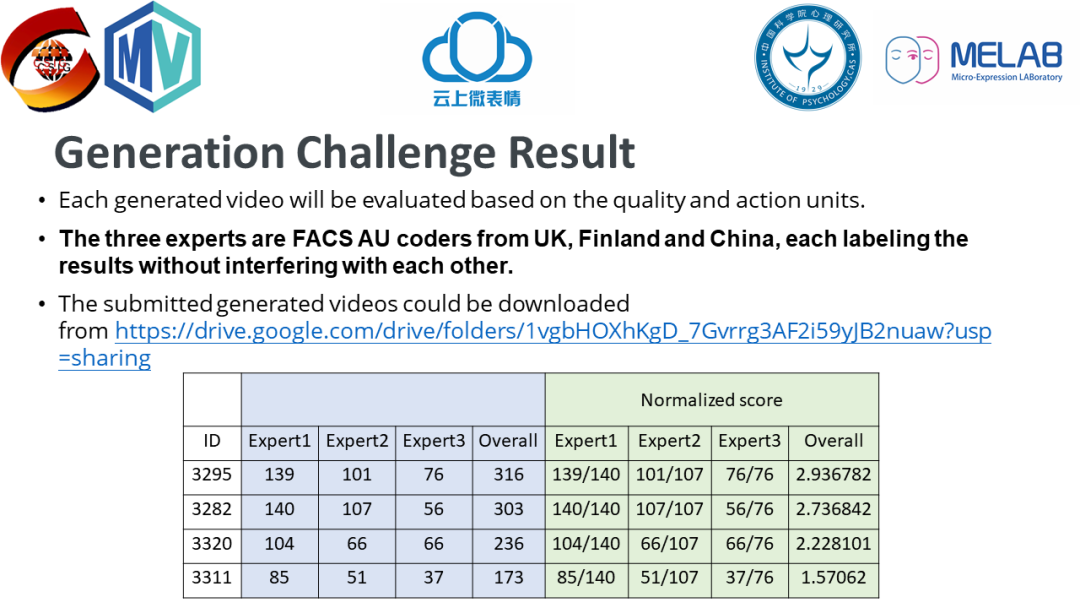
共有五支队伍参加了“微表情生成”任务,其中一组参赛队伍未生成符合要求的视频,没有参与评估。任务的前三名文章被录取,获胜者们在 ACM MM21的多媒体挑战大赛分会场进行了口头报告。
1.1生成任务第一名 - 中山大学的张毅同学
张毅同学和团队中的其他成员提出了基于面部先验知识的微表情生成方法,首先通过Image Animation对问题进行建模,然后设计了利用面部先验知识的Region Focusing Module对构建的模型进行改进。模型框架图如下所示。
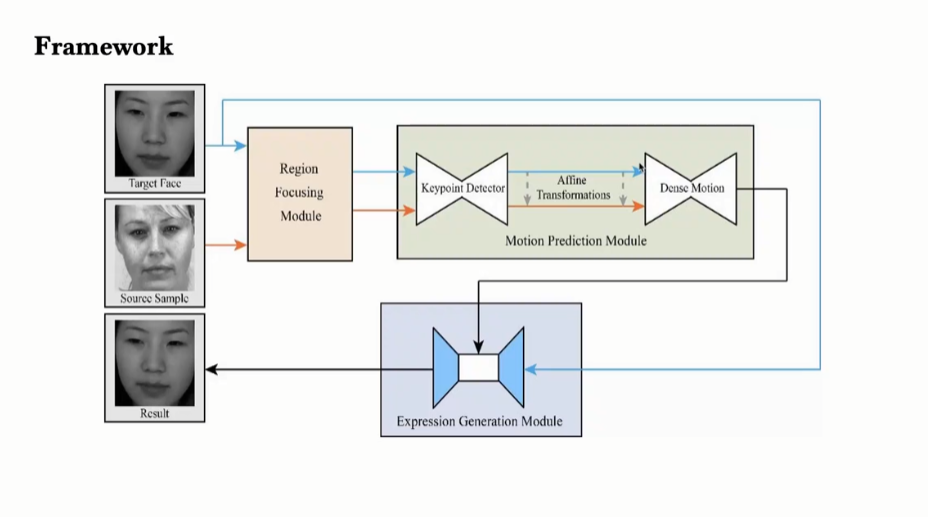
其中,张同学重点介绍了Region Focusing Module的设计:首先基于68个人脸特征点和人脸动作信息,确定18个人脸关键点;然后通过计算每个关键点的distance-related importance,求和归一化后得到最终的Facial Prior Map。

然后张同学通过直观呈现微表情视频生成结果,证明了结合Region Focusing Module的微表情生成方法的优越性。值得一提的是,张同学进行了混合数据库的模型训练,实现结果显示在混合数据库训练和在CASME II数据库训练,可以得到较好的生成视频。

1.2生成任务第二名 - 香港城市大学的博士研究生范歆琦同学
范歆琦同学首先介绍了目前微表情的研究背景和需要解决的问题。然后,范同学提出了一种基于运动重定向和迁移学习的面部微表情生成深度模型。

接下来,在简要介绍了微表情生成任务的任务设置和Image Generation的常见模型后,范同学对他们提出的模型进行了阐述。模型概览如下所示。
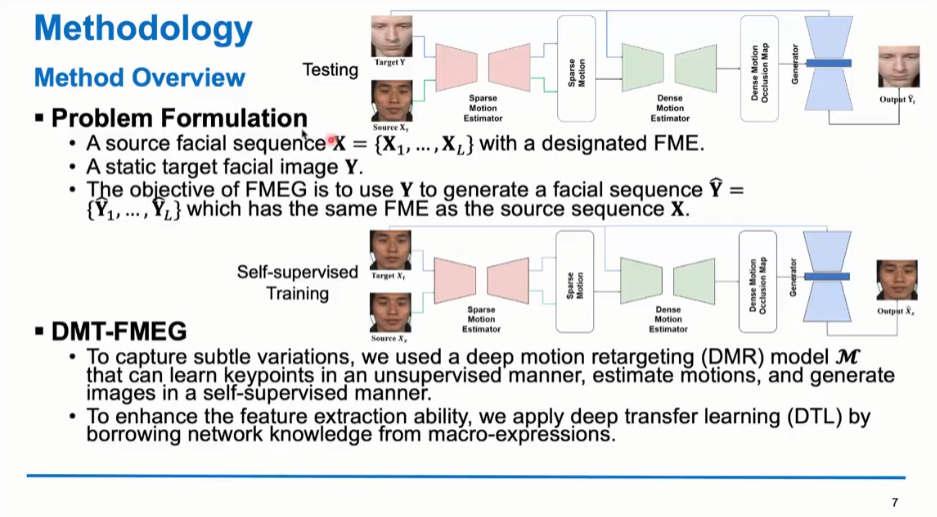
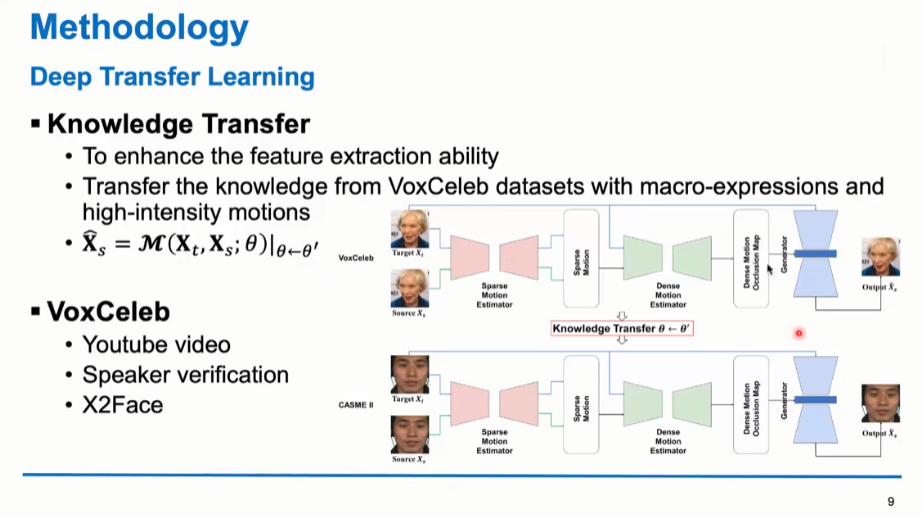
其中,为了捕捉和生成细微变化,他们采用了深度运动重定向网络。

此外,为了提升特征提取能力,他们应用了迁移学习借鉴了宏表情的知识。
其结果在多个数据集上显示出令人满意的结果,并获得了本次挑战赛生成任务的第二名。此外,通过展示生成结果的demo,范同学指出了跨人种的微表情视频生成和相同人种的相比,性能仍有待提升。
1.3生成任务第三名 - 中国科学技术大学的硕士研究生徐一凡同学
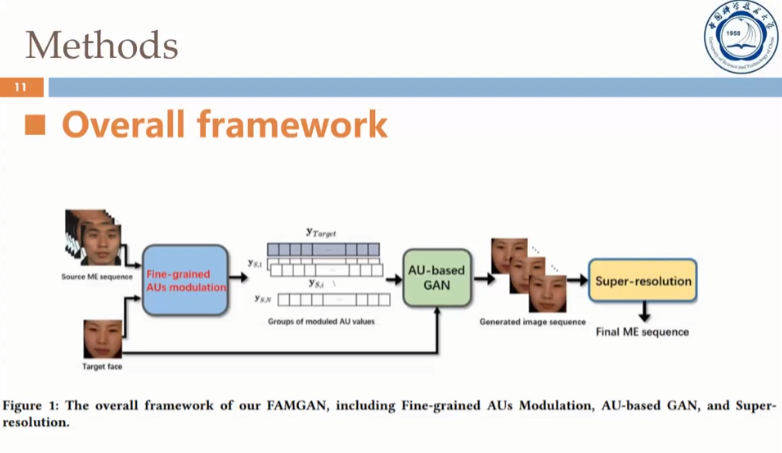
同样的,徐同学在报告的开始介绍了微表情生成任务的比赛设置和研究背景,然后介绍了他们提出的方法,即将细粒度的AU调制和对抗生成网络相结合生成连续、准确的微表情样本。以下是方法的大致框架。
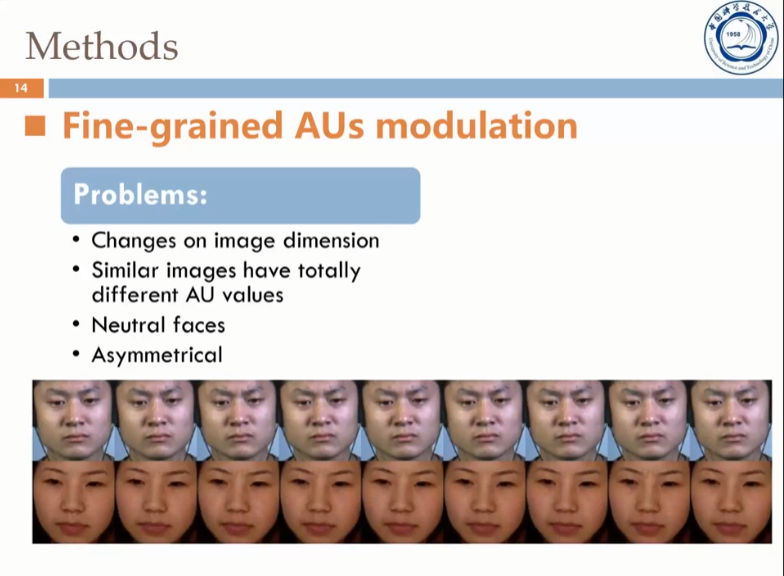
然后,徐同学首先介绍了模型的生成框架:GANimation,一个可以得到连续动作变化的生成网络。但是,GANimation仍存在一些不足,如下所示:
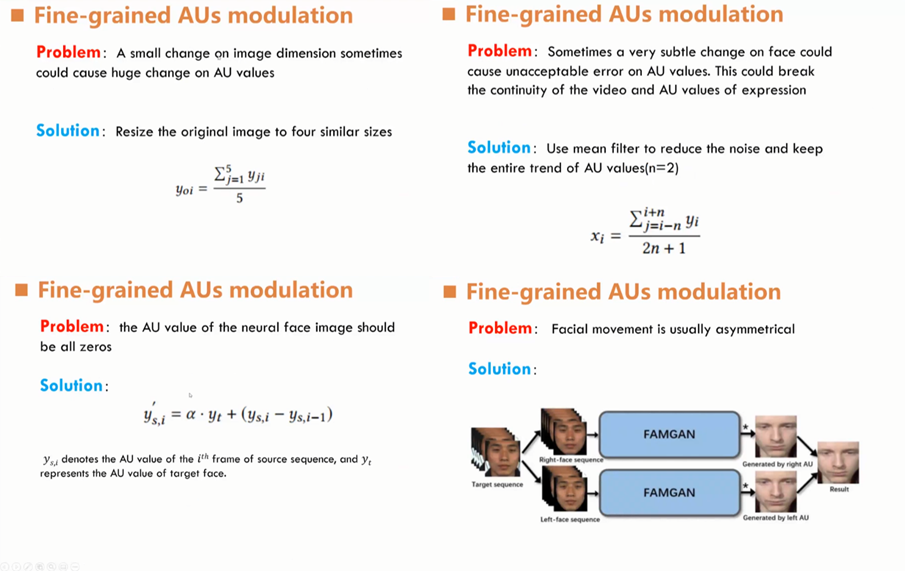
针对以上的问题,徐同学等人提出了细粒度的AU调制:
通过结合细粒度的AU调制和对抗生成网络,徐同学在报告的最后展示了可以和真实视频媲美的的微表情视频,并对未来的工作进行了展望。
02 问答环节
在Panel环节,听众和讲者们就生成任务中的特征点输入、跨数据库验证以及客观的生成视频评估方法等问题进行了讨论。
03 后续活动安排
在活动的最后,讲座的主持人李婧婷博士对活动进行了总结并对第二十六期CSIG云上微表情活动进行了预告。此外,王甦菁博士等人在Pattern Recognition Letters申请了主题为“Face-based Emotion Understanding”的专刊,欢迎大家关注。

此次讲座的回放已经发布在B站:
https://www.bilibili.com/video/BV1KS4y1c7uq?share_source=copy_web。






