CSIG云上微表情第三期研讨会成功举办--微表情的前世今生
微表情是一种短暂的、微弱的、无意识的面部微表情,持续时间往往在0.5s内,能够揭示人类试图隐藏的真实情绪。微表情识别的研究旨在让机器有足够的智能,能够从人脸视频序列中识别人类的真实情绪。然而由于微表情持续时间短、面部肌肉运动强度低,对其进行准确的表征与识别是一项极具挑战性的任务。为了促进心理学领域和计算机视觉领域针对微表情的进一步研究,由中国图象图形学学会(CSIG)举办、CSIG机器视觉专业委员会承办,中国科学院心理研究所的王甦菁博士组织了一系列云上微表情的学术活动。

第三期云上微表情研讨会于2020年8月28日晚上7点进行,由中国科学院心理研究所王甦菁老师团队的李婧婷博士主持。此次讲座邀请到了芬兰奥卢大学的李晓白博士,她首先介绍了奥卢大学机器视觉与信号分析中心前些年微表情相关的主要工作,其次介绍了微表情课题的发展计划。本次报告得到了微表情研究领域的广泛关注,期间有将近五十多位听众参加了此次讲座。
李晓白博士的讲座内容主要分为2个部分:第一部分内容是芬兰奥卢大学机器视觉与信号分析中心在微表情研究方向的工作成果,包括微表情数据库、微表情检测与识别算法等;第二部分是微表情课题的发展计划,包括在建的微表情数据库、相关的身体微姿态研究以及将来的研究方向等。
芬兰奥卢大学机器视觉与信号分析中心在微表情研究方向的工作成果
李博士首先介绍了其课题组从2010年开始创建的SMIC数据库。微表情研究初期面临没有相关样本的问题,中国科学院心理研究所和奥卢大学成为首批为该研究领域创建数据库的团队。为了提供多模态的分析数据,SMIC数据库包括了高频摄像机、普通摄像机和红外摄像机采集的样本。同时,李博士提到了创建微表情数据库的两大挑战:如何有效诱发微表情和情绪抑制的问题。

在微表情识别的算法介绍中,李博士介绍了传统的机器学习方法,并强调由于微表情微小的动作特性,微表情样本预处理精度的要求很高,人脸的归一化和校准对后续的识别率有很大的影响。其次,由于微表情的样本帧数太少影响了特征提取,李博士所在团队提出了时域插值的方法。
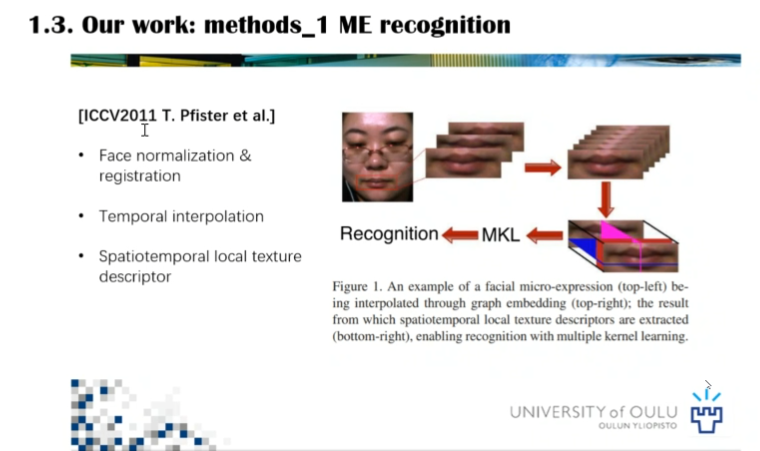
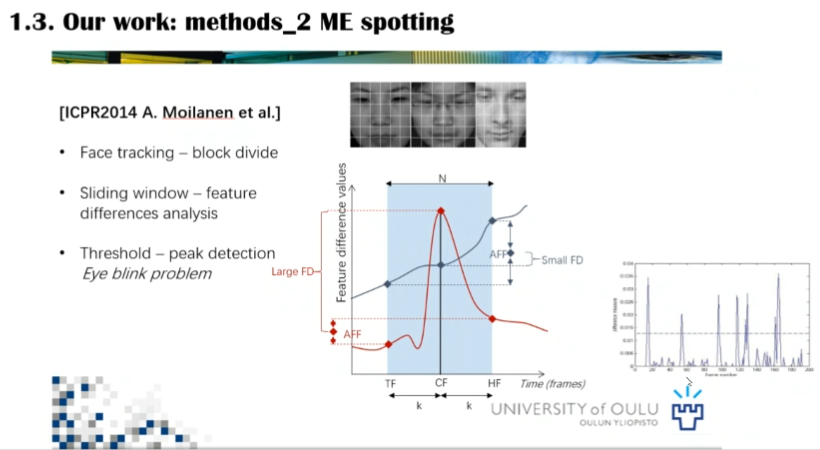
关于微表情检测的方法,李博士介绍了通过比较特征差异的检测方法,这种方式可以捕捉迅速的人脸动作,但是不具备区分微表情和其他快速动作的能力,例如眨眼和眼神变换经常作为虚警被检测到。
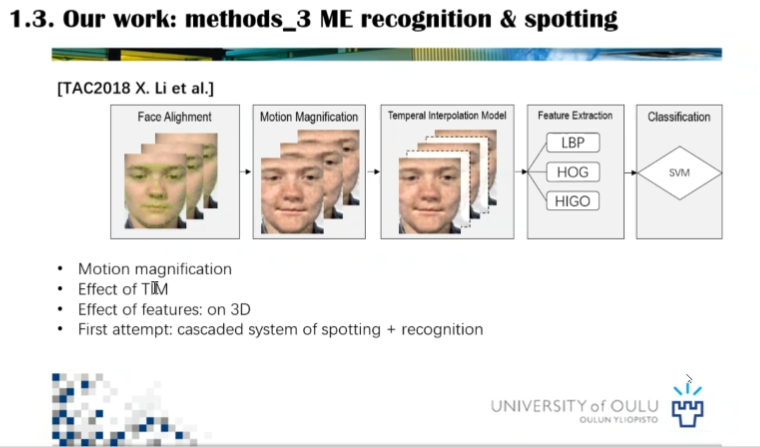
在微表情检测与识别系统方面,李博士首先介绍了动作放大对提升微表情识别率的帮助,其次介绍了时域插值法的细节问题。然后在三维特征提取方面,李博士提到XT和YT面提取的微表情特征强于XY面提取的特征。李博士介绍的方法也是业内将检测方法和识别方法整合在一个流程体系内的首次尝试。
另外,李博士还介绍了她们团队利用深度学习进行微表情识别方面的尝试,以及通过频域检测微表情峰值帧再进行单帧识别的方法。
微表情课题发展计划
在这个部分,李博士首先讨论了目前自动化微表情研究的发展瓶颈,指出相关研究的最终目标是精细情绪识别,并需要整个研究社区思考和定位微表情的研究困难。
接下来,李博士介绍了她们团队和帝国理工大学正在合作创建的4DMicro微表情数据库,该数据库提供了多通道多视角的样本,样本采集过程一共安装了6个摄像头,为自动化分析提供了全局视角。

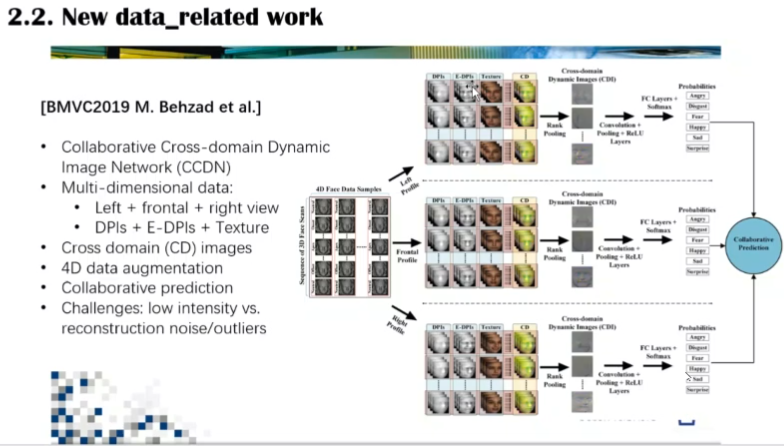
李博士还介绍了她们发表在BMVC2019会议的文章,探讨了哪些方法可以用在4D微表情研究。该文章中,为了减轻输入网络负担、保留有效信息,将样本信息退回到二维,构建了多通道的网络,将深度信息、校正深度信息、纹理信息合成为一个跨域图像序列进行分析。同时,李博士讨论了如何对4D数据进行数据增强,特别是对于微表情,3D重建存在精确度缺失和引入噪声的问题。
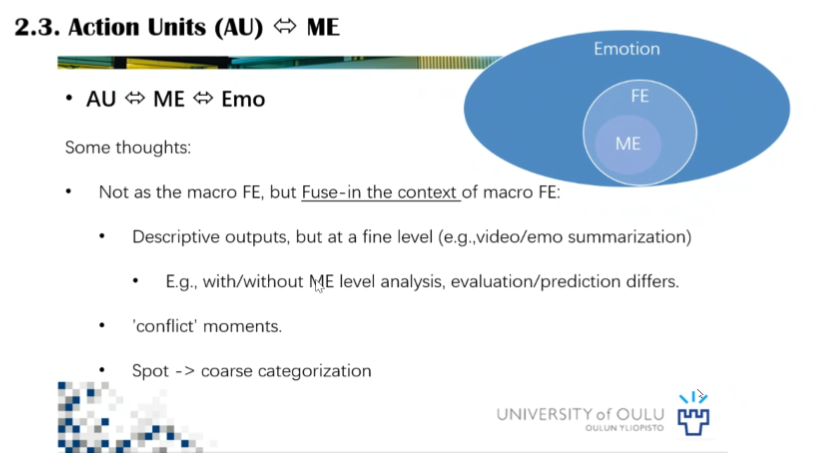
在探索动作单元和微表情的关系方面,李博士首先回顾了人脸动作编码系统和常规人脸表情的关系,提出动作单元(Action Unit, AU)为表情分析提供了相对客观的对应关系。但是对于微表情,AU和微表情的对应关系仍不甚明确,包括微表情的情绪分类问题,不同情绪对应哪些AU组合的问题等。
李博士也举例说明了在创建数据库标定过程中遇到的实际困难。首先在微表情出现的过程中可能会出现干扰动作,例如被试人员感到惊讶的过程中为了掩盖这一表情,常常会用眨眼来掩盖。另外李博士提到了抑制性的问题,AU4和AU7作为微表情中常见的动作单元,可能对应多个负面情绪,单纯通过面部呈现特征让计算机分类不太现实。

针对以上问题,李博士提出一种研究思路,即通过视频理解的方式,利用有无微表情的视频分析对比,捕捉视频中的情绪冲突,这种突变可能就是隐含的情感变化。
在精细情感分析的其他线索方面,李晓白博士首先给出了人体微姿态的定义:人体的一种被动反应,大多为负面的情绪感受,例如害怕时人体的后倾行为。同时李博士介绍了他们课题组创建的微姿态数据库,包括身体、手+头、手+躯干等行为组合,介绍了分析的方法流程:姿势识别+情绪分析。

李博士还提出在未来可以进行多模态的精细情感分析,包括结合人脸微表情、微姿态和生理信号等。
在李晓白博士精彩的报告后,听众们踊跃发言,提出了很多非常有意义的问题。相关的讨论主要涉及到以下几个方面:
首先,中国科学院心理研究所的王甦菁博士和李晓白博士对微表情数据库样本标注容错性展开了讨论。王博士提出目前的数据库中有可能存在许多标注错误的样本,在以后研究中可以预设数据库中给出的一部分标签是不准确的,并以此为基础开展研究。
其次,参会者们向李博士提出了关于在建数据库的一些细节问题,如样本数目、人种分布、AU标注和微表情的类型等。
另外,参会者们还对微表情标注的基线设定、多模态微表情分析、宏观表情和微表情区分、人种不同对微表情以及AU的影响等展开了讨论。
在活动的最后,讲座的主持人李婧婷博士对活动进行了总结,并对后续三期CSIG云上微表情活动进行了预告。敬请继续关注!






