CVPR 2020 | PQ-NET:序列化的三维形状生成网络


1
动 机
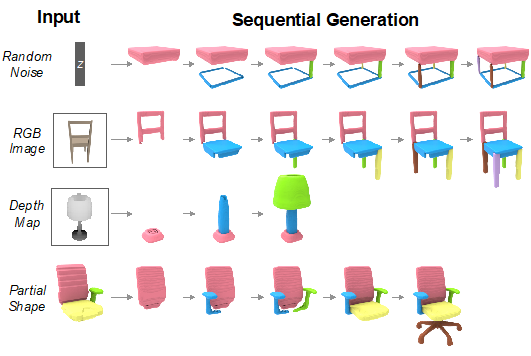
2
方 法
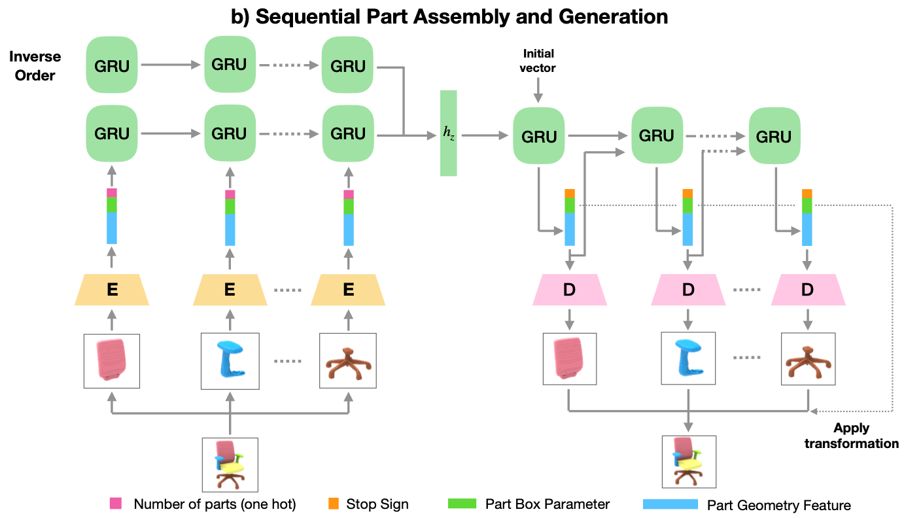
3
结果与应用


4
讨 论
北京大学前沿计算研究中心可视计算与学习实验室,在陈宝权教授带领下,围绕图形学、三维视觉、可视化及机器人等领域展开科学研究,坚持跨学科前沿技术探索、视觉艺术和技术融合两条主线,长期与顶级国际团队深度合作,并积极进行产业化实践与推广。
参考文献
[1] Y. Wang, K. Xu, J. Li, H. Zhang, A. Shamir, L. Liu, Z. Cheng, and Y. Xiong. Symmetry hierarchy of man-made objects. Computer Graphics Forum, 30(2), 2011.
[2] J. Li, K. Xu, S. Chaudhuri, E. Yumer, H. Zhang, and L. Guibas. Grass: Generative recursive autoencoders for shape structures. ACM Trans. on Graph. (SIGGRAPH), 2017.
[3] K. Mo, P. Guerrero, L. Yi, H. Su, P. Wonka, N. Mitra, and L. J. Guibas. Structurenet: Hierarchical graph networks for 3d shape generation. ACM Trans. on Graph. (SIGGRAPH Asia), 2019.
[4] Z. Chen and H. Zhang. Learning implicit fields for generative shape modeling. IEEE CVPR, 2019.
[5] I. Gulrajani, F. Ahmed, M. Arjovsky, V. Dumoulin, and A. Courville. Improved training of wasserstein gans. NIPS 2017.
CVPR 2020 系列报道
相关报道:
CVPR 2020接收论文公布:录用1470篇,接收率“二连降”,仅22% !
论文集:
论文解读:
01. [微软] 古有照妖镜,今有换脸识别机,微软 CVPR 2020力作,让伪造人脸无处遁形
02. [港大] PolarMask:将实例分割统一到FCN,有望在工业界大规模应用
03. [牛津大学] RandLA-Net:大场景三维点云语义分割新框架(已开源)
04. [北大&华为] CIFAR-10上做NAS,仅需单卡半天!华为提出基于进化算法和权值共享CARS模型
05. [南京大学] 化繁为简,弱监督目标定位领域的新SOTA - 伪监督目标定位方法
06. [UC 伯克利] 挑战 11 种 GAN的图像真伪,DeepFake鉴别一点都不难
07. [哈斯特帕大学] 学习一个宫崎骏画风的图像风格转换GAN
08. [人大&阿德莱德大学] 看图说话之随心所欲:细粒度可控的图像描述自动生成






