最新!斯坦福联合谷歌使用图卷积和GAN从场景图中生成图像

导语:长期以来,在图像生成方法的研究上已经取得了显著的成果,但对于现有的基于文本描述的图像生成方法而言,难以从带有许多对象和关系的复杂句子中生成逼真的图像。最近,斯坦福大学联合谷歌提出了一种从场景图中生成图像的方法,它能够明确地对对象及其关系进行推理,从而生成具有许多可识别对象的复杂图像。
想要真正地理解视觉世界,我们的模型应当不仅能够识别图像,而且还能够生成图像。为了实现这一目标,在从自然语言描述中生成图像方面已经取得了令人兴奋的最新进展。这些方法在有限的领域上取得了极好的结果,比如对鸟类或花朵的描述。但这些方法却难以如实地再现带有许多对象和关系的复杂句子。为了克服这个限制,我们提出了一种从场景图中生成图像的方法,它能够明确地对对象及其关系进行推理。我们的模型使用图卷积来处理输入图,通过预测边界框和对象的分割掩码来计算场景布局,并使用级联优化网络(cascaded refinement network)将布局转换成图像。该网络针对一对鉴别器进行了对抗性训练,以确保逼真的输出。我们在视觉基因组(Visual Genome)和COCO-Stuff上验证了我们的方法,这其中的定性结果、控制变量实验结果和用户研究证明了我们的方法能够生成带有多个对象的复杂图像。
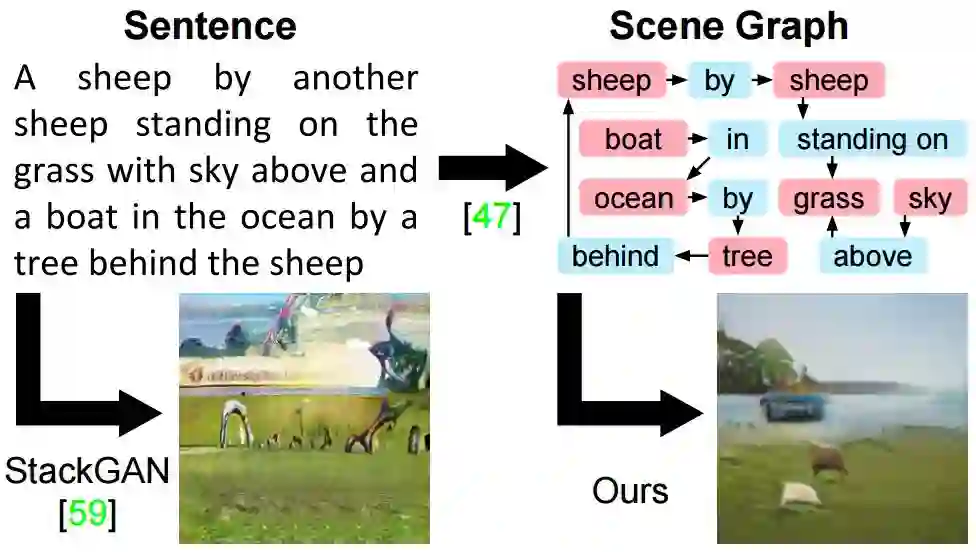
图1:用于从句子中生成图像的最先进的方法,如StackGA,很难忠实地描绘具有多个对象的复杂句子。我们通过从场景图生成图像来克服这一限制,从而使得我们的方法能够明确地推断出对象及其关系。
我不理解我无法创造的东西。——理查德••费曼(Richard Feynman)
创造行为需要对正在被创造的东西有深刻的理解:厨师、小说家和电影制作人必须比用餐者、读者或电影观众对食物、写作和电影有着更为深入的理解。如果我们的计算机视觉系统想要真正理解视觉世界,他们必须不仅能够识别图像,而且还能够生成图像。
除了赋予深刻的视觉理解之外,生成逼真图像的方法也可能是有用的。在短期内,自动图像生成(automatic image generation)可以为艺术家或美术设计员的工作带来帮助。而总有一天,我们可以用算法来代替图像和视频搜索引擎,根据每个用户的个人喜好生成自定义的图像和视频。
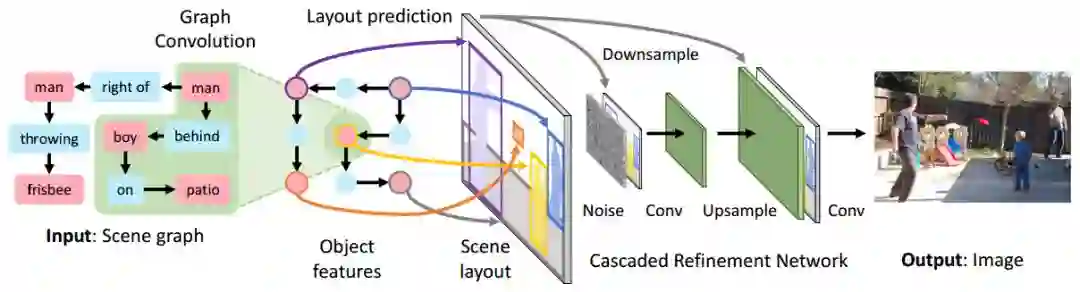
图2:我们的用于从场景图中生成图像的图像生成网络概述
作为迈向这些目标的坚实一步,最近,通过将循环神经网络和生成对抗网络相结合以从自然语言描述中生成图像,在文本到图像的合成方面取得了令人兴奋的进展。
可以这样说,这些方法可以在诸如鸟类或花卉的细粒度描述这样有限的区域中产生令人惊叹的结果。然而,如图1所示,促使从句子中生成图像的主要方法与包含许多对象的复杂句子相斗争。
句子是一个线性结构,一个单词紧挨着另一个单词,但正如图1所示,一个复杂句子所传达的信息通常可以更明确地表示为对象及其关系的场景图。场景图是图像和语言的强大的结构化表示。它们已经被用于语义图像检索(semantic image retrieval)、评估以及改进图像字幕。科学家们开发了一些方法,用于将句子转换成场景图,并从图像中预测场景图。
在本文中,我们旨在通过在场景图上对我们的生成进行调节以具有许多对象及其关系的复杂图像,从而使我们的模型能够明确地对对象及其关系进行推理。
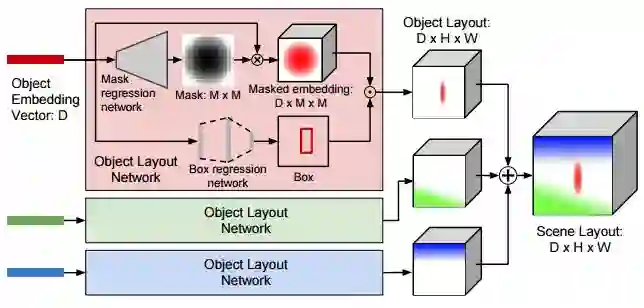
图3:通过对场景布局进行计算,我们从图域移动到图像域。
与新任务结伴而来的,是新的挑战。我们必须研发一种处理场景图输入的方法。为此,我们采用了一种沿图像边缘传递信息的图卷积网络。对图进行处理后,我们必须弥合符号图结构输入和二维图像输出之间的差距。为此,我们通过预测图中所有对象的边界框和分割掩码,来构建场景布局。预测完布局后,我们必须生成一个与之相关联的图像。为此,我们使用级联优化网络(CRN),它可以在持续增长的空间度量下处理布局。最后,我们必须确保生成的图像是真实的,并包含可识别目标。因此,我们对一对在图像补丁和生成对象上运行的鉴别器网络进行对抗性训练。模型的所有组件都以端到端的方式进行联合学习。
我们在两个数据集上进行了实验:Visual Genome,它提供了人工标注的场景图,COCO-Stuff,它根据对照对象的位置构建合成场景图。在这两个数据集上,我们都给出了定性结果,证实了我们的方法,能够生成与输入场景图的对象和关系相关联的复杂图像,并通过控制变量的方法来验证我们模型的每个组件。
对生成图像模型进行自动评估是一项具有挑战性的难题,因此我们还通过两项有关Amazon Mechanical Turk的用户调研来评估我们的结果。与Stack GAN这一文本到图像合成的领先系统相比,用户发现,我们的结果在68%的实验中可以更好地匹配COCO字幕,并且包含高于59%的可识别目标。

图4:我们的方法在Visual Genome上训练之后所生成的图像。在每一行中,我们从左侧的简单场景图开始,逐步向右移动,添加更多的对象和关系。图像所涉及的关系像“风筝下面的汽车,草地上的小船”。
相关研究
生成图像模型(Generative Image Models)生成图像模型可分为三大类:生成式对抗网络(GAN)联合学习一个合成图像的生成器和一个将图像分类为真实或伪造的鉴别器;变分自动编码器使用变分推理联合学习图像和潜在代码之间的编码器和解码器映射;自回归方法通过调整所有先前像素上的每个像素来模拟似然性。
条件性图像合成(Conditional Image Synthesis)在附加输入上对生成进行调整。通过提供标签作为生成器和鉴别器的附加输入,或者通过强制鉴别器对标签进行预测,GAN可以在类标签上进行调节。而我们采取后一种方法。
场景图将场景表征为有向图,其中,节点是对象,而边缘给出对象之间的关系。场景图已被用于图像检索和图像字幕评估中,有一些研究试图将句子转换为场景图]或预测图像的基础场景图。在有关场景图的大多数研究中都使用Visual Genome数据集,该数据集提供了带有人工注释的场景图。
图深度学习,有些方法学习图节点的嵌入,给定一个类似于word2vec的单一大型图,它将学习给定文本语料库中单词的嵌入。这些与我们的方法不同,因为我们必须在每次正向传递时对新的图进行处理。
本文提出了一种从场景图生成图像的端到端的方法。与基于文本描述的图像生成方法相比,从结构化场景图而非非结构化文本中生成图像,使得我们的方法可以更准确地对对象及其关系进行推理,并且生成具有许多可识别对象的复杂图像。
原文链接:https://arxiv.org/pdf/1804.01622.pdf (转自:雷克世界)
今晚8点博士导师直播课

点击“阅读原文”进入直播间

