超越CLIP!OpenAI新作GLIDE:文本引导图像生成新高度!
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达

以前,当我们想拥有一副图像时,首先会做的就是找专业画师,将我们对图画的要求逐一描述,画师再根据需求醉墨淋漓一番。但这种方式需要耗费一定的时间和人力成本,且成果不一定尽如人意。
如今,基于自然语言生成逼真图像的工具使我们能够以一种全新的方式轻松创建大量的高质量图像。使用自然语言编辑图像的能力进一步允许迭代细化和细粒度控制,这两者对于现实世界的应用程序都至关重要。
目前,GANs(对抗生成网络)在大多数图像生成任务上拥有最先进的技术,这些技术是通过样本质量来衡量的,例如FID,Inception Score 和 Precision等指标。
然而,其中一些指标不能完全捕获生成图像的多样性,且与最先进的基于似然度的模型相比,GANs捕获的多样性较少。此外,如果没有精心选择的超参数和正则化器,GANs在训练中经常翻车。
针对这些问题,OpenAI的两位研究人员Prafulla Dhariwal和Alex Nichol便着眼于其他体系架构。2021年5月,这两名学者发表了名为《Diffusion Models Beat GANs on Image Synthesis》的论文,证明了扩散模型在图像合成上优于目前最先进的生成模型的图像质量。

论文地址:https://openreview.net/pdf?id=AAWuCvzaVt
半年多的时间,Alex Nichol 和Prafulla Dhariwal再度携手,带领团队于2021年12月20日发布了最新研究《GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models 》。

论文地址:https://arxiv.org/pdf/2112.10741v1.pdf
以文本“萨尔瓦多·达勒(salvador daĺı)的超现实主义梦幻油画,画的是一只猫在跳棋”为例,GLIDE模型生成如下具有阴影和反射的逼真图像,并以正确的方式组合多个概念,产生新颖概念的艺术效果图。

文章一出即在推特上引起广泛关注,收获了无数业内人士的鲜花和掌声。
名为Kyle的网友表示,他觉得这项研究跨越了“渐进式增长GAN”到“StyleGAN”的界限。从满是笨拙的机器学习人工伪造物,到现在突然变得与它模仿的真实物体几乎无法分辨。

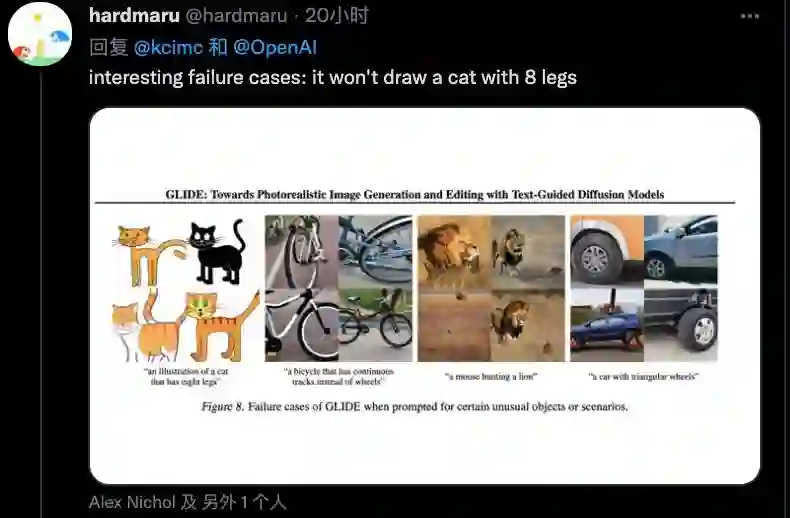
连GLIDE的失败案例都透着满满的优秀感:它不会画有 8 条腿的猫......
有网友提问:如果对它提出指令“没人见过的东西”会生成什么?
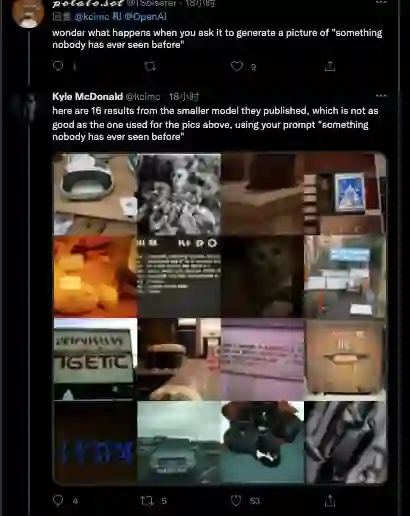
Em......结果是没见过,但也不是完全没见过。

实验证明,扩散模型(Diffusion Models)可以生成高质量的合成图像,尤其在与引导技术结合使用时,能够在保真度上权衡多样性。
作者们为文本条件下的图像合成问题的扩散模型,对比了两种不同的指导策略:CLIP guidance 和classifier-free guidance。而后发现,在写实度和主题相似度方面,后者更受人类评估参与者的青睐,并且经常获得逼真的样本。
使用classifier-free guidance的35亿参数文本条件扩散模型的样本收到的评价更高,令来自DALL-E的样本完全“黯然失色”。GLIDE模型微调后还可以修复图像,出色完成文本驱动的图像编辑任务。
已有的最新文本条件图像模型已经可以做到根据格式多样的文本中合成图像,甚至可以“理解”语义,按照合理的逻辑组合毫不相关的客体。但在捕捉相应文本并生成逼真图像方面,还略逊一筹。
毋庸置疑,扩散模型是前景大为可观的生成模型系列,在诸多图像生成任务上达到了最先进的样本质量基准。
为了在类条件设置中实现真实感,作者们利用分类器指导增强扩散模型,扩散模型以分类器的标签作为条件。分类器首先在有噪声的图像上进行训练,在扩散采样过程中,使用分类器提供的梯度引导样本朝向标签。Salimans等人曾通过使用无分类器的指导,未单独训练的分类器中获得了类似结果,这给研究者们带来了灵感,在有标签扩散模型和无标签扩散模型的预测之间进行插值。
受引导扩散模型生成逼真样本的能力以及文本到图像模型处理自由形式提示的能力的启发,研究人员将引导扩散应用于文本条件图像合成问题。首先,作者们训练了一个 35 亿参数扩散模型,该模型使用文本编码器以自然语言描述为条件。接下来,他们比较了两种将扩散模型引导至文本提示的技术:CLIP 引导和无分类器引导。使用人工和自动评估,发现无分类器的指导产生更高质量的图像。
研究人员发现GLIDE模型中,无分类器指导生成的样本栩栩如生,图像还蕴涵着广泛的世界知识。由人类参与者评估后,普遍给出评价:GLIDE“创造”的效果优于 DALL-E。

在论文《Diffusion Models Beat GANs on Image Synthesis》中,研究人员通过一系列的消融实验,以找到更好的扩散模型架构,实现无条件的图像合成。对于条件图像合成,则使用分类器指导(利用分类器的梯度以来权衡样本质量-多样性)进一步提高了样本质量。
论文的作者们分别在ImageNet 128×128上达到2.97的FID,在ImageNet 256×256上达到4.59的FID,在ImageNet512×512上达到7.72的FID,并且即使每个样本只有25次正向传递,其生成图像质量依然可以匹配BigGAN-deep,同时保持了更好的分布覆盖率(多样性)。
最后,作者团队发现分类器指导与上采样扩散模型可以很好地结合在一起,从而将ImageNet512×512上的FID进一步降低到3.85。
DeepMind曾于2018年在一篇 ICLR 2019 论文中提出了BigGAN,当时一经发表就引起了大量关注, 很多学者都不敢相信AI竟能生成如此高质量的图像,这些生成图像的目标和背景都相当逼真,边界也很自然。

由BigGAN模型生成的512x512分辨率图像
如今,Alex Nichol和Prafulla Dhariwal两位学者提出的扩散模型,终于可在图像合成上匹敌BigGAN。

从最佳ImageNet512×512模型(FID3.85)中选择的样本
扩散模型是一类基于似然度的模型,最近被证明可用于生成高质量图像,同时保留理想的属性,如更高的分布覆盖率、稳定的训练目标和更好的可扩展性。这些模型通过逐步去除信号中的噪声来生成样本,其训练目标可以表示为一个重新加权的变分下界。
Nichol和Dhariwal发现,随着计算量的增加,这些模型不断改进,即使在高难度ImageNet256×256数据集上也能生成高质量的样本。
再来看看GLIDE的生成效果。下图是GLIDE基于不同的文本提示生成的16个图像集,例如“使用计算器的刺猬”、“戴着红色领带和紫色帽子的柯基”等等,如图所示,生成的图像基本符合文本描述。
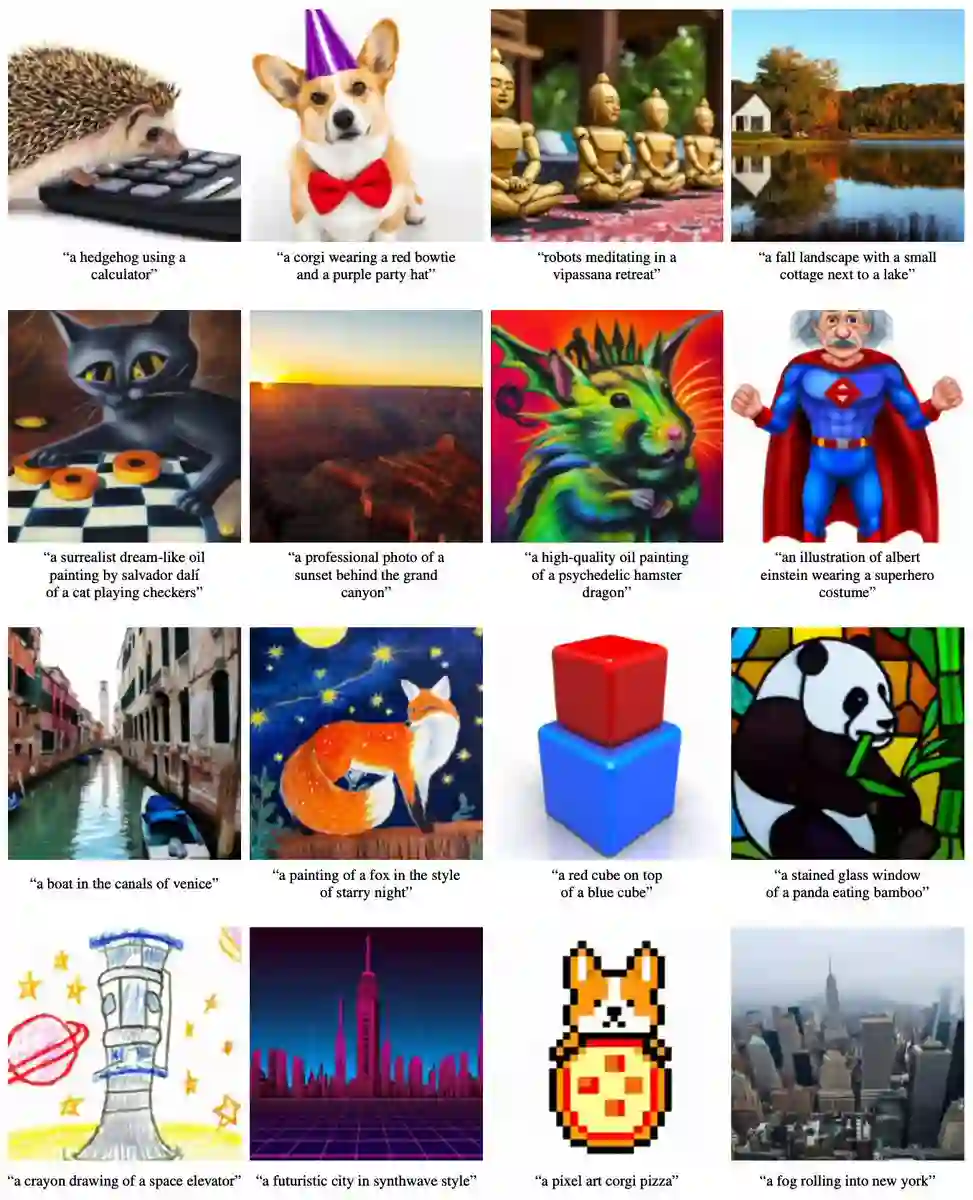
美中不足的是,这项研究发布的较小模型的准确性不如全尺寸模型那么完美。下图是由“刺猬”文本提示生成的16个样本。

除了图文转换,该论文还包括一个交互式系统的原型,用于逐步细化图像的选定部分。这些图像中的一切都是自动生成的,从整个房间开始,对绿色区域进行迭代细化。

在下图中,研究人员将他们的模型与之前最先进的基于MS-COCO字幕的文本条件图像生成模型进行了比较,发现其模型在无需CLIP 重新排序或挑选的情况下生成了更逼真的图像。对于XMC-GAN,从用于文本到图像生成的跨模态对比学习采集了样本。对于DALL-E,在温度0.85下生成样本,并使用CLIP重新排序从256个样本中选择最好的。对于GLIDE,使用2.0刻度的CLIP引导和3.0刻度的无分类器引导。作者没有为GLIDE执行任何CLIP重新排序或挑选。

研究人员使用人类评估协议将GLIDE与DALL-E进行比较(如下表所示)。请注意,GLIDE使用的训练计算与DALL-E大致相同,但模型要小得多(35亿对120亿参数)。此外,它只需要更少的采样延迟,并且没有CLIP 重新排序。
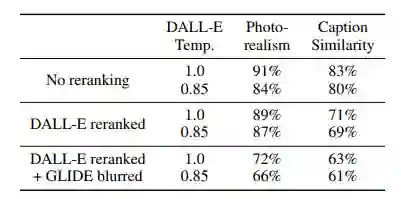
研究人员在DALL-E和GLIDE之间执行三组比较。首先,当不使用CLIP重新排序时,比较两种模型。其次,只对DALL-E使用CLIP重新排序。最后,对DALL-E使用CLIP重新排序,并通过DALL-E使用的离散VAE投影GLIDE样本。后者允许研究者评估DALLE模糊样本如何影响人类的判断。他们使用DALL-E模型的两个温度来进行所有的评估,其模型在所有设置中都受到人类评估人员的青睐,即使在非常支持DALL-E的配置中,也允许它使用大量的测试时间计算(通过CLIP重新排序)同时降低GLIDE样本质量(通过VAE模糊)。
ICCV和CVPR 2021论文和代码下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
CVer-Transformer交流群成立
扫码添加CVer助手,可申请加入CVer-Transformer 微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲长按加小助手微信,进交流群
▲点击上方卡片,关注CVer公众号



